
Sie haben also eine deutsche PDF-Datei, die ins Englische übersetzt werden soll. Bevor Sie überhaupt an Übersetzungssoftware denken, müssen Sie eine kritische Überprüfung durchführen. Das ist der Unterschied zwischen einer fünfminütigen Aufgabe und einem mehrstündigen Albtraum. Sie müssen herausfinden, ob Ihre PDF „nativ" oder „gescannt" ist.
Von Anfang an richtig zu liegen ist alles. Es bestimmt, welche Tools Sie verwenden, welche Schritte Sie unternehmen und letztendlich die Qualität Ihres endgültigen englischen Dokuments.
Zunächst: Herausfinden, mit welcher Art von deutscher PDF Sie es zu tun haben

Nicht alle PDFs sind gleich. Die eigentliche Frage ist: Wurde Ihr Dokument digital erstellt oder ist es nur ein Bild einer Papiersseite?
Stellen Sie sich eine native PDF als ein Dokument vor, das auf einem Computer erstellt und direkt aus einem Programm wie Microsoft Word oder Adobe InDesign gespeichert wird. Der Text darin ist echter, lebendiger Text. Sie können darauf klicken, einen Satz markieren und ihn in eine andere Anwendung kopieren und einfügen. Das ist das beste Szenario.
Eine gescannte PDF hingegen ist im Grunde eine Fotografie. Jemand hat ein physisches Dokument – wie einen alten Vertrag, eine Seite aus einem Buch oder ein unterzeichnetes Formular – genommen und durch einen Scanner geleitet. Für Ihren Computer ist die Datei kein Text; es ist nur ein großes Bild aus Pixeln. Sie können keine einzelnen Wörter auswählen, genauso wenig wie bei einer JPEG-Datei.
So unterscheiden Sie sie: Der Zwei-Sekunden-Test
Glücklicherweise ist die Identifizierung Ihres PDF-Typs unglaublich einfach. Öffnen Sie einfach die Datei und versuchen Sie dies:
- Können Sie Ihren Cursor klicken und ziehen, um einen Satz hervorzuheben? Wenn der Text blau wird (oder die Hervorhebungsfarbe Ihres Systems), herzlichen Glückwunsch. Sie haben eine native PDF. Ihr nächster Schritt besteht darin, diesen Text zu extrahieren.
- Zeichnet Ihr Cursor ein Kästchen um einen Bereich der Seite? Wenn Sie keine einzelnen Wörter auswählen können und nur einen rechteckigen Bereich auswählen können, schauen Sie sich eine gescannte PDF an. Das bedeutet, dass Sie Optical Character Recognition (OCR) verwenden müssen, bevor Sie etwas anderes tun können.
Dieser einfache Test ist nicht verhandelbar. Wenn Sie versuchen, eine gescannte PDF in einen textbasierten Übersetzer einzufügen, erhalten Sie nur eine Fehlermeldung oder ein völlig leeres Dokument. Sie müssen das Bild zuerst in Text konvertieren.
Die Nachfrage nach dieser Art von Dokumentintelligenz ist riesig. Der Markt für deutsche Sprachübersetzungssoftware erreichte 2024 etwa 5,4 Milliarden USD und ist auf dem besten Weg, sich fast zu verdoppeln und bis 2035 eine projizierte 9,7 Milliarden USD zu erreichen. Sie können mehr über dieses Wachstum lesen, um zu sehen, wohin die Technologie führt.
Um es noch deutlicher zu machen, hier ist eine kurze Aufschlüsselung der Unterschiede.
Native PDF vs. Gescannte PDF – Schneller Vergleich
Diese Tabelle zeigt die wichtigsten Unterschiede zwischen nativen und gescannten PDFs, um Ihnen dabei zu helfen, Ihren Dateityp schnell zu identifizieren und den Übersetzungspfad für jeden zu verstehen.
| Merkmal | Native PDF | Gescannte PDF (bildbasiert) |
|---|---|---|
| Erstellungsmethode | Direkt aus einer Softwareanwendung gespeichert (z. B. Word, InDesign). | Erstellt durch Scannen eines physischen Papierdokuments. |
| Text auswählbar? | Ja, Sie können Text markieren, kopieren und einfügen. | Nein, der Text ist Teil eines flachen Bildes. |
| Durchsuchbar? | Ja, Sie können Strg+F (oder Cmd+F) verwenden, um Wörter zu finden. | Nein, nicht bis nach der OCR durchgeführt wird. |
| Typischer Anwendungsfall | Berichte, eBooks, moderne wissenschaftliche Arbeiten, Rechnungen. | Alte Archive, unterzeichnete Verträge, historische Dokumente, Briefe. |
| Übersetzungspfad | Direkte Textextraktion → Übersetzung | OCR zur Textextraktion → Übersetzung |
Ihren Ausgangspunkt zu kennen ist die halbe Miete. Wenn Sie ein modernes Universitätspapier haben, ist es fast sicher eine native PDF. Wenn es sich um einen digitalisierten Datensatz aus einem historischen Archiv handelt, können Sie sicher sein, dass er gescannt ist. Die Identifizierung davon im Voraus setzt Sie auf den richtigen Weg für eine reibungslose und genaue Übersetzung.
Vorbereitung des deutschen Textes zur Übersetzung
Sie haben also herausgefunden, ob Ihre PDF nativ oder gescannt ist. Großartig. Der nächste Schritt besteht darin, den deutschen Text in einem sauberen, nutzbaren Format zu extrahieren. Dies ist nicht nur ein einfaches Kopieren und Einfügen; denken Sie daran, es als Grundlage für eine hochwertige Übersetzung zu legen. Die Art und Weise, wie Sie diese Phase handhaben, bestimmt direkt die Qualität des endgültigen englischen Dokuments.
Bei nativen PDFs ist der Text bereits vorhanden und bereit zum Auswählen. Aber wenn Sie einfach Ihren Cursor über alles ziehen und es in einen Übersetzer einfügen, landen Sie wahrscheinlich bei einem Durcheinander aus unterbrochenen Zeilen und durcheinander gewirbelten Absätzen. Dies gilt besonders für alles mit einem mehrspaltigem Layout. Der Trick besteht darin, eine Methode zu verwenden, die die ursprüngliche Struktur des Dokuments versteht und respektiert.
Extrahieren von Text aus nativen PDFs
Ein viel besserer Weg nach vorne ist die Verwendung eines dedizierten PDF-zu-Text-Konverters oder eines ordnungsgemäßen PDF-Editors. Diese Tools sind dafür konzipiert, zu analysieren, wie ein Dokument fließt, und den Text in der richtigen Lesereihenfolge zu extrahieren. Das Durchführen dieses zusätzlichen Schritts kann Ihnen viel Zeit sparen, die Sie sonst damit verbringen würden, Zeilenumbrüche manuell zu beheben und Sätze neu zu ordnen, bevor Sie überhaupt eine deutsche PDF ins Englische konvertieren.
Stellen Sie sich ein zweispaltiges wissenschaftliches Papier vor. Wenn Sie einfach kopieren und einfügen, springt der Text auf jeder einzelnen Zeile von der linken Spalte zur rechten, was es völlig unlesbar macht. Ein gutes Extraktions-Tool liest die ganze erste Spalte, bevor es zur zweiten übergeht, genau wie ein Mensch.
Verwendung von OCR für gescannte deutsche Dokumente
Wenn Sie es mit einer gescannten PDF zu tun haben, müssen Sie sie durch Optical Character Recognition (OCR) verarbeiten. Diese Technologie „liest" das Bild der Seite im Grunde und konvertiert es in bearbeitbaren, digitalen Text. Modernes OCR ist fantastisch, aber bei Deutsch richtig hinzubekommen bedeutet, auf einige spezifische Details zu achten.
Um die genauesten Ergebnisse zu erhalten, beachten Sie diese Dinge:
- Spracheinstellung: Das ist entscheidend. Stellen Sie die Sprache der OCR-Software immer auf Deutsch ein. Dies teilt dem Tool mit, dass es Sonderzeichen wie Umlaute (ä, ö, ü) und das Eszett (ß) erwarten und korrekt identifizieren soll, was die Genauigkeit massiv erhöht.
- Bildqualität: Ein scharfes, hochauflösendes Scan macht den großen Unterschied. Wenn Ihre PDF verschwommen, dunkel oder kontrastarm ist, wird die OCR-Ausgabe voller Fehler sein.
- Korrekturlesen: Nehmen Sie nie an, dass das OCR perfekt ist. Verbringen Sie ein paar Minuten damit, den extrahierten deutschen Text auf offensichtliche Fehler zu überprüfen, bevor Sie ihn übersetzen. Das ist eine kleine Zeitinvestition, die sich großartig auszahlt.
Diese Präzision ist wichtig. Deutschlands Sprachdienstleistungsmarkt ist der größte in Europa, wobei Language Service Provider (LSPs) 2017 über 1,25 Milliarden Euro generierten. Das Land ist ein großer Akteur in der Übersetzungstechnologie, daher sind die Tools vorhanden. Sie können mehr über Deutschlands Sprachtechnologie-Branche erfahren.
Wichtigste Erkenntnis: Die Qualität Ihrer Textextraktion – ob aus einer nativen PDF oder über OCR – bestimmt direkt die maximal mögliche Qualität Ihrer endgültigen Übersetzung. Es ist das alte Prinzip „Garbage In, Garbage Out". Ein sauberer Quelltext ist der einzige Weg zu einem genauen, lesbaren englischen Dokument.
Für einen tieferen Einblick in diesen Prozess lesen Sie unseren Leitfaden zu OCR und Übersetzung.
3. Wählen Sie das richtige Übersetzungstool für Ihr Projekt
Okay, Sie haben sauberen deutschen Text erfolgreich aus Ihrer PDF extrahiert. Jetzt kommt der entscheidende Teil: zu wählen, wie Sie ihn tatsächlich übersetzen. Es geht nicht nur darum, das erste Tool zu wählen, das Sie auf Google finden. Es geht darum, die Methode an Ihr spezifisches Ziel anzupassen, da Ihre Wahl die Geschwindigkeit, Kosten und vor allem das professionelle Erscheinungsbild des endgültigen Dokuments direkt beeinflusst.
Die Nachfrage nach guter Übersetzung ist riesig. Der Markt soll 2024 41,78 Milliarden Dollar erreichen, hauptsächlich weil 75% der Menschen es vorziehen, Produkte in ihrer eigenen Sprache zu kaufen. Es ist klar, dass eine richtige Übersetzung wichtig ist. Sie können diese Übersetzungsmarkttrends hier genauer erforschen, wenn Sie neugierig sind.
Der nachfolgende Entscheidungsbaum fasst den ersten kritischen Schritt zusammen, den wir behandelt haben – herauszufinden, ob Ihre PDF nativ oder gescannt ist, um Ihren Text für diese Tools vorzubereiten.
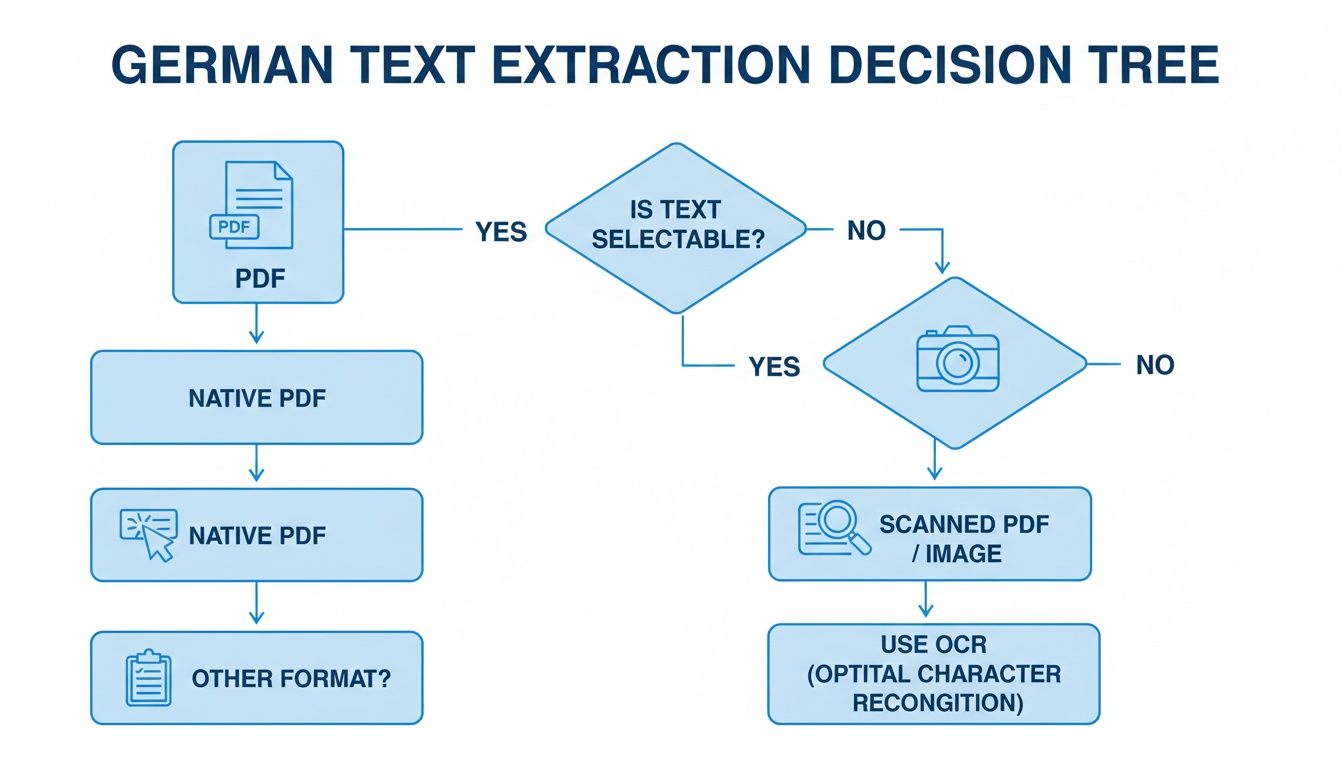
Wie Sie sehen, teilt sich Ihr Pfad je nachdem, ob der Text auswählbar (nativ) oder OCR-bedürftig (gescannt) ist. Diese erste Wahl setzt die Bühne für alles, was folgt.
Der klassische Kompromiss: Geschwindigkeit vs. Formatierung
Für schnelle, informelle Jobs sind kostenlose Online-Tools wie DeepL oder Google Translate fantastisch. Sie können Ihren extrahierten deutschen Text einfügen und in Sekunden eine englische Version erhalten. Wenn Sie nur die Essenz eines Artikels oder einer kurzen E-Mail verstehen müssen, ist dies oft alles, was Sie brauchen.
Der Hauptnachteil? Formatierung. Sobald Sie den übersetzten Text in ein neues Dokument einfügen, verlieren Sie alles – Überschriften, fetten Text, Kursivdruck, Absatzumbrüche und Kapitaleinteilungen. Das Layout für ein langes Dokument manuell neu aufzubauen ist eine seelenzermürbende Aufgabe. Ich bin dort gewesen, und es macht keinen Spaß.
- Szenario: Sie haben ein 10-seitiges deutsches Benutzerhandbuch in einem einfachen Textformat. Sie müssen die Anweisungen nur für den persönlichen Gebrauch verstehen.
- Bester Ansatz: Ein kostenloser Online-Übersetzer ist hier perfekt. Die Geschwindigkeit ist den minimalen Aufwand wert, um einfachen Text erneut zu lesen.
Mein persönlicher Tipp: Auch mit den besten Tools für maschinelle Übersetzung kann Deutsch-zu-Englisch knifflig sein. Ich habe festgestellt, dass DeepL oft natürlicher klingende Übersetzungen für europäische Sprachpaare erzeugt, weil es spezifische Trainingsdaten hat. Es ist normalerweise mein erster Halt für eine schnelle Überprüfung.
Wenn Layout alles ist: Ein intelligenterer Arbeitsablauf
Aber was ist, wenn Sie eine deutsche PDF ins Englische konvertieren müssen und die Struktur nicht verhandelbar ist? Denken Sie an ein wissenschaftliches Papier mit Zitaten, ein technisches Handbuch mit Diagrammen oder einen Roman mit sorgfältig gestalteten Kapiteln. Für diese Projekte ist die Beibehaltung des Layouts genauso wichtig wie die Übersetzung selbst.
Hier brauchen Sie einen fortgeschritteneren Arbeitsablauf. Anstatt nur rohen Text zu übersetzen, sollte Ihr Ziel sein, die gesamte Dokumentstruktur zu übersetzen.
Hier ist ein zuverlässiger Weg, um es zu tun:
- Zu EPUB konvertieren: Konvertieren Sie zunächst Ihren sauberen deutschen Text in eine EPUB-Datei. EPUB ist ein E-Book-Format, das speziell dafür konzipiert ist, Strukturinformationen wie Kapitel, Überschriften und Styling zu enthalten.
- Ein spezialisiertes Tool verwenden: Verwenden Sie dann eine Plattform, die für die Übersetzung strukturierter Dokumente konzipiert ist, wie BookTranslator.ai.
Diese Methode umgeht die Formatierungsverluste vollständig. Ein Service wie BookTranslator.ai liest die deutsche EPUB, übersetzt den Inhalt, während der zugrunde liegende Code für Überschriften und Kapitel intakt bleibt, und gibt eine vollständig formatierte englische EPUB aus. Sie erhalten ein professionelles, lesbares Dokument, das das Layout des Originals widerspiegelt und spart Ihnen Stunden manueller Neuformatierung.
Die Erkundung anderer Softwareoptionen zur Übersetzung von Dokumenten kann Ihnen mehr Kontext darüber geben, warum spezialisierte Tools für ernsthafte Projekte oft die richtige Wahl sind.
Um Ihnen bei der Entscheidung zu helfen, hier ist eine kurze Aufschlüsselung der Methoden, die wir besprochen haben.
Vergleich der Übersetzungsmethoden
Diese Tabelle bietet einen klaren Vergleich verschiedener Übersetzungsmethoden und hilft Ihnen zu entscheiden, welcher Ansatz am besten für die Anforderungen Ihres Projekts bezüglich Geschwindigkeit, Genauigkeit und Formatierung geeignet ist.
| Methode | Beste für | Layouterhaltung | Kosten |
|---|---|---|---|
| Kostenlose Online-Tools | Schnelle, informelle Zusammenfassungen kurzer Dokumente oder E-Mails. | Keine. Sie verlieren die gesamte Formatierung. | Kostenlos |
| CAT-Tools (Pro) | Professionelle Übersetzer, die an komplexen Projekten arbeiten. | Hoch. Erhält Tags und Struktur. | Hoch (Software & Arbeit) |
| Zu EPUB konvertieren & BookTranslator.ai verwenden | Lange, strukturierte Dokumente wie Bücher oder Handbücher, bei denen das Layout entscheidend ist. | Ausgezeichnet. Spiegelt die Originaldatei wider. | Moderat (Servicegebühr) |
Letztendlich hängt das richtige Tool ganz von Ihrem Endziel ab. Für einen schnellen Überblick sind kostenlose Tools in Ordnung. Für alles, das professionell aussehen und seine ursprüngliche Struktur behalten muss, wird die Investition in einen spezialisierten Arbeitsablauf Ihnen einen massiven Kopfschmerz ersparen.
Eine praktische Anleitung für perfekte Formatierung
Wenn Sie eine deutsche PDF ins Englische konvertieren müssen und das professionelle Layout intakt halten möchten, reicht einfaches Kopieren und Einfügen nicht aus. Dieser Ansatz scheitert bei komplexen Dokumenten wie Geschäftsberichten, wissenschaftlichen Arbeiten oder ganzen Büchern.
Für diese Projekte benötigen Sie einen Arbeitsablauf, der die Struktur des Dokuments respektiert. Hier ist eine zuverlässige Technik, die ich unzählige Male verwendet habe: Konvertieren Sie das Dokument zuerst in eine EPUB-Datei. Diese Methode geht nicht nur um die Übersetzung der Wörter; es geht um die Übersetzung des gesamten Dokuments – Text, Kapitel, Überschriften und alles. Das ist der Unterschied zwischen einer sauberen, professionellen englischen Version und einem durcheinander gewirbelten Durcheinander, das Stunden zu reparieren dauert.
Von Text zu einer strukturierten EPUB
Zunächst müssen Sie Ihren sauberen deutschen Text in eine EPUB-Datei bringen. Falls Sie nicht vertraut sind, ist ein EPUB ein E-Book-Format, das fantastisch darin ist, die Dokumentstruktur zu bewahren. Denken Sie daran, es als einen Plan, der jedem E-Reader mitteilt, wo Kapitel beginnen, welcher Text eine Überschrift ist und wie Absätze fließen sollen.
Mein Lieblingswerkzeug für diese Aufgabe ist Calibre. Es ist eine fantastische, kostenlose E-Book-Management-Software, die die Konvertierung von Dateien in EPUBs zum Kinderspiel macht.
- Bereiten Sie Ihren Text vor: Nehmen Sie den deutschen Text, den Sie extrahiert haben – entweder aus einer nativen PDF kopiert oder mit OCR aus einer gescannten extrahiert. Speichern Sie ihn als einfache .docx oder sogar eine .txt-Datei.
- Fügen Sie ihn zu Calibre hinzu: Öffnen Sie Calibre und ziehen Sie einfach Ihr deutsches Dokument per Drag & Drop in die Bibliothek.
- Zu EPUB konvertieren: Wählen Sie das Buch aus und klicken Sie auf die Schaltfläche „Bücher konvertieren". Ein neues Fenster wird angezeigt. Stellen Sie in der oberen rechten Ecke das Ausgabeformat auf EPUB ein. Calibre ist intelligent genug, um Kapitel und Überschriften aus der Formatierung Ihrer Quelldatei zu erkennen. Klicken Sie auf „OK", und Sie haben eine perfekt strukturierte deutsche EPUB, die bereit ist.
Warum das funktioniert: Die Erstellung einer EPUB zuerst ist die geheime Zutat. Sie sperren die Struktur des Dokuments vor der Übersetzung. Dies stellt sicher, dass die endgültige englische Version das professionelle Layout des Originals widerspiegelt, was direkte Textübersetzer einfach nicht bewältigen können.
Übersetzung der EPUB mit Präzision
Jetzt, da Sie Ihre deutsche EPUB haben, ist es Zeit für die Übersetzung. Dafür brauchen Sie ein Tool, das strukturierte Dateien versteht. Hier glänzt ein spezialisierter Service wie BookTranslator.ai. Es ist speziell dafür konzipiert, E-Book-Formate zu verarbeiten und den Text zu übersetzen, während der zugrunde liegende Formatierungscode unberührt bleibt.
Der Prozess könnte nicht einfacher sein:
- Laden Sie die EPUB hoch: Laden Sie die deutsche EPUB hoch, die Sie gerade mit Calibre erstellt haben. Die Plattform ist dafür gebaut, große Dateien zu verarbeiten, was sie perfekt für lange Berichte oder vollständige Bücher macht.
- Wählen Sie Ihre Sprachen: Stellen Sie die Quelle auf Deutsch und das Ziel auf Englisch ein.
- Übersetzen: Die KI macht sich an die Arbeit und verarbeitet den Text innerhalb seiner strukturellen Tags. Sie weiß, dass ein
<h1>ein Kapiteltitel ist und ein<p>ein Absatz, daher behält sie diese Hierarchie in der übersetzten Ausgabe perfekt bei.
Was Sie zurückbekommen, ist eine vollständig übersetzte, perfekt formatierte englische EPUB. Sie können sie in jedem E-Reader öffnen oder sogar Calibre erneut verwenden, um sie zurück in eine PDF zu konvertieren, falls das ist, was Sie brauchen. Diese Methode umgeht elegant die häufigen Layoutkopfschmerzen und liefert ein endgültiges Dokument, das genauso professionell und lesbar ist wie das Original.
Wenn Sie mit einem gescannten Dokument begonnen haben, könnte unser dedizierter Leitfaden zum Übersetzen einer gescannten PDF für diese anfänglichen OCR-Schritte nützlich sein.
Überprüfung und Verbesserung Ihrer englischen Übersetzung

Sie haben Ihre PDF also durch einen Übersetzer laufen lassen. Die schwere Arbeit ist erledigt, aber senden Sie noch nicht ab. Denken Sie an diesen KI-generierten Text als einen fantastischen ersten Entwurf – eine solide Grundlage, nicht das fertige Meisterwerk. Dies ist die entscheidende Phase, in der Sie eingreifen, um die Übersetzung zu polieren und sicherzustellen, dass sie klingt, als wäre sie von einer Person geschrieben worden, nicht von einem Programm.
Maschinelle Übersetzung für häufige Sprachen wie Deutsch zu Englisch ist bemerkenswert gut geworden, mit einigen Studien, die Genauigkeitsraten von über 90% zeigen. Aber diese letzte 10% ist, wo die wirklichen Probleme lauern können. Es ist in diesen Rändern, wo der Kontext verloren geht, die Glaubwürdigkeit riskiert wird und die Bedeutung durcheinander gerät.
Eine KI könnte eine häufige deutsche Redewendung wörtlich übersetzen, was zu einigen sehr verwirrenden oder unbeabsichtigt lustigen Ergebnissen im Englischen führen kann. Diese endgültige Überprüfung handelt alles davon, diese Fehler zu fangen, bevor Ihr Publikum es tut.
Worauf Sie bei Ihrer Überprüfung achten sollten
Wenn Sie eine deutsche PDF ins Englische konvertieren, muss Ihr Nachbearbeitungs-Pass weit über eine einfache Rechtschreibprüfung hinausgehen. Sie suchen nach den subtilen Fehlern, die automatisierte Tools fast immer übersehen.
Hier ist, worauf ich mich immer konzentriere:
- Kulturelle Nuancen: Ist der Ton richtig? Deutsche Geschäftsschrift ist oft formeller als ihr englisches Gegenstück. Eine direkte Übersetzung könnte steif oder übermäßig fordernd wirken. Sie könnten die Sprache abschwächen müssen, um den englischsprachigen kulturellen Erwartungen zu entsprechen.
- Idiomatische Ausdrücke: Seien Sie äußerst wachsam gegen