
Masz niemiecki plik PDF, który musi być w języku angielskim. Zanim w ogóle pomyślisz o oprogramowaniu do tłumaczenia, musisz wykonać jedno krytyczne sprawdzenie. To jest różnica między pracą pięciominutową a wielogodzinnym koszmarom. Musisz ustalić, czy Twój plik PDF jest „natywny" czy „zeskanowany".
Zrobienie tego od początku to wszystko. Określa to narzędzia, które będziesz używać, kroki, które podejmiesz, i ostatecznie jakość Twojego ostatecznego dokumentu w języku angielskim.
Po pierwsze, ustal, z jakim rodzajem niemieckiego pliku PDF masz do czynienia

Nie wszystkie pliki PDF są tworzone w ten sam sposób. Prawdziwe pytanie brzmi: czy Twój dokument powstał cyfrowo, czy jest po prostu zdjęciem strony papieru?
Pomyśl o natywnym pliku PDF jako dokumencie utworzonym na komputerze i zapisanym bezpośrednio z programu takiego jak Microsoft Word lub Adobe InDesign. Tekst wewnątrz to prawdziwy, żywy tekst. Możesz go kliknąć, podświetlić zdanie i skopiować je do innej aplikacji. To najlepszy scenariusz.
Zeskanowany plik PDF natomiast to zasadniczo fotografia. Ktoś wziął dokument fizyczny — na przykład stary kontrakt, stronę z książki lub podpisany formularz — i przepuścił go przez skaner. Dla Twojego komputera plik to nie tekst; to tylko jeden duży obraz złożony z pikseli. Nie możesz wybierać poszczególnych słów bardziej niż w pliku JPEG.
Jak je rozróżnić: test dwu sekundowy
Na szczęście określenie typu pliku PDF jest niezwykle proste. Otwórz plik i spróbuj tego:
- Czy możesz kliknąć i przeciągnąć kursor, aby podświetlić zdanie? Jeśli tekst zmieni kolor na niebieski (lub kolor podświetlenia Twojego systemu), gratulacje. Masz natywny plik PDF. Twoim następnym krokiem będzie wyodrębnienie tego tekstu.
- Czy Twój kursor rysuje pole wokół części strony? Jeśli nie możesz wybierać poszczególnych słów i możesz wybierać tylko obszar prostokątny, masz do czynienia ze zeskanowanym plikiem PDF. Oznacza to, że będziesz musiał użyć Optycznego Rozpoznawania Znaków (OCR), zanim będziesz mógł cokolwiek zrobić.
Ten prosty test jest nie do negocjacji. Próba wrzucenia zeskanowanego pliku PDF do tłumacza opartego na tekście spowoduje tylko komunikat o błędzie lub całkowicie pusty dokument. Musisz najpierw przekonwertować obraz na tekst.
Zapotrzebowanie na tego rodzaju inteligencję dokumentów jest ogromne. Niemiecki rynek oprogramowania do tłumaczenia języka osiągnął około 5,4 miliarda USD w 2024 roku i jest na drodze do prawie podwojenia, osiągając prognozowany 9,7 miliarda USD do 2035 roku. Możesz przeczytać więcej o tym wzroście, aby zobaczyć, gdzie zmierza technologia.
Aby to było jeszcze jaśniejsze, oto szybkie zestawienie różnic.
Natywny plik PDF vs. Zeskanowany plik PDF — szybkie porównanie
Ta tabela zawiera przegląd kluczowych różnic między natywnymi i zeskanowanymi plikami PDF, aby szybko zidentyfikować typ pliku i zrozumieć ścieżkę tłumaczenia dla każdego z nich.
| Charakterystyka | Natywny plik PDF | Zeskanowany plik PDF (oparty na obrazach) |
|---|---|---|
| Metoda tworzenia | Zapisany bezpośrednio z aplikacji programowej (np. Word, InDesign). | Utworzony przez zeskanowanie dokumentu fizycznego papieru. |
| Tekst można wybierać? | Tak, możesz podświetlać, kopiować i wklejać tekst. | Nie, tekst jest częścią płaskiego obrazu. |
| Można przeszukiwać? | Tak, możesz użyć Ctrl+F (lub Cmd+F), aby znaleźć słowa. | Nie, nie dopóki nie zostanie wykonane OCR. |
| Typowy przypadek użycia | Raporty, e-booki, nowoczesne prace akademickie, faktury. | Stare archiwa, podpisane umowy, dokumenty historyczne, listy. |
| Ścieżka tłumaczenia | Bezpośrednie wyodrębnienie tekstu → Tłumaczenie | OCR do wyodrębnienia tekstu → Tłumaczenie |
Znanie punktu wyjścia to połowa bitwy. Jeśli masz nowoczesną pracę uniwersytecką, to prawie na pewno natywny plik PDF. Jeśli jest to zdigitalizowany dokument z historycznego archiwum, możesz się założyć, że jest zeskanowany. Zidentyfikowanie tego z góry ustawia Cię na właściwej ścieżce do gładkiego i dokładnego tłumaczenia.
Przygotowanie niemieckiego tekstu do tłumaczenia
Więc ustaliliśmy, czy Twój plik PDF jest natywny czy zeskanowany. Świetnie. Następnym krokiem jest wyodrębnienie niemieckiego tekstu w czystym, użytecznym formacie. To nie jest po prostu prosta praca kopiuj i wklej; pomyśl o tym jako o położeniu fundamentu pod wysokiej jakości tłumaczenie. To, jak poradzisz sobie na tym etapie, bezpośrednio wpływa na jakość ostatecznego dokumentu w języku angielskim.
W przypadku natywnych plików PDF tekst jest już tam, gotowy do wyboru. Ale jeśli po prostu przeciągniesz kursor nad wszystkim i wkleisz go do tłumacza, prawdopodobnie skończysz z bałaganem złamanych linii i pomieszanych akapitów. Jest to szczególnie ważne w przypadku czegokolwiek z wielokolumnowym układem. Sztuką jest użycie metody, która rozumie i szanuje oryginalną strukturę dokumentu.
Wyodrębnianie tekstu z natywnych plików PDF
Dużo lepszą drogą do przodu jest użycie dedykowanego konwertera PDF na tekst lub właściwego edytora PDF. Te narzędzia są zbudowane do analizy sposobu przepływu dokumentu i wyodrębniania tekstu w prawidłowej kolejności czytania. Podjęcie tego dodatkowego kroku może zaoszczędzić Ci dużo czasu, który w innym przypadku spędziłbyś na ręcznym naprawianiu podziałów wierszy i zmienianiu kolejności zdań, zanim w ogóle przystąpisz do konwersji niemieckiego pliku PDF na angielski.
Wyobraź sobie dwukolumnowy artykuł akademicki. Jeśli po prostu skopiujesz i wkleisz, tekst będzie przeskakiwać z lewej kolumny na prawą w każdym wierszu, czyniąc to całkowicie nieczytelnym. Dobre narzędzie do ekstrakcji czyta całą pierwszą kolumnę, zanim przejdzie do drugiej, dokładnie jak by to zrobiła osoba.
Używanie OCR dla zeskanowanych dokumentów niemieckich
Jeśli masz do czynienia ze zeskanowanym plikiem PDF, będziesz musiał przepuścić go przez Optyczne Rozpoznawanie Znaków (OCR). Ta technologia zasadniczo „czyta" obraz strony i konwertuje go na edytowalny, cyfrowy tekst. Nowoczesne OCR jest fantastyczne, ale uzyskanie prawidłowych wyników z niemieckim oznacza zwrócenie uwagi na kilka konkretnych szczegółów.
Aby uzyskać najdokładniejsze wyniki, pamiętaj o tych rzeczach:
- Ustawienie języka: To jest kluczowe. Zawsze ustaw język oprogramowania OCR na niemiecki. To mówi narzędziu, aby oczekiwać i prawidłowo identyfikować znaki specjalne, takie jak umlauts (ä, ö, ü) i Eszett (ß), co znacznie zwiększa dokładność.
- Jakość obrazu: Ostry, wysokorozdzielczy skan robi ogromną różnicę. Jeśli Twój plik PDF jest rozmyty, ciemny lub ma niski kontrast, dane wyjściowe OCR będą pełne błędów.
- Korekta: Nigdy nie zakładaj, że OCR jest doskonały. Poświęć kilka minut na przeskanowanie wyodrębnionego niemieckiego tekstu w poszukiwaniu oczywistych błędów przed jego tłumaczeniem. To mała inwestycja czasu, która się opłaca.
Ta precyzja jest ważna. Niemiecki rynek usług językowych jest największy w Europie, a Dostawcy Usług Językowych (LSP) generują ponad 1,25 miliarda euro już w 2017 roku. Kraj jest ważnym graczem w technologii tłumaczenia, więc narzędzia tam są. Możesz odkryć więcej o niemieckiej branży technologii językowej tutaj.
Kluczowy wniosek: Jakość wyodrębnienia tekstu — czy pochodzi z natywnego pliku PDF, czy przez OCR — bezpośrednio określa maksymalną możliwą jakość Twojego ostatecznego tłumaczenia. To stara zasada „śmieci wejdą, śmieci wyjdą". Czysty tekst źródłowy to jedyna droga do dokładnego, czytelnego dokumentu w języku angielskim.
Aby głębiej zanurzyć się w ten proces, sprawdź nasz przewodnik dotyczący OCR i tłumaczenia.
3. Wybierz odpowiednie narzędzie tłumaczenia dla Twojego projektu
Okej, pomyślnie wyodrębniłeś czysty niemiecki tekst z Twojego pliku PDF. Teraz przychodzi kluczowa część: wybór sposobu jego faktycznego tłumaczenia. To nie tylko o wybraniu pierwszego narzędzia, które znajdziesz na Google. Chodzi o dopasowanie metody do Twojego konkretnego celu, ponieważ Twój wybór będzie bezpośrednio wpływać na szybkość, koszt i, co najważniejsze, profesjonalny wygląd ostatecznego dokumentu.
Zapotrzebowanie na dobre tłumaczenie jest ogromne. Rynek ma osiągnąć 41,78 miliarda dolarów w 2024 roku, głównie dlatego, że aż 75% ludzi woli kupować produkty w swoim własnym języku. Oczywiście, zrobienie prawidłowego tłumaczenia ma znaczenie. Możesz głębiej zapoznać się z tymi trendami na rynku tłumaczeń tutaj, jeśli jesteś ciekawy.
Poniższe drzewo decyzyjne podsumowuje pierwszy krytyczny krok, który omówiliśmy — ustalenie, czy Twój plik PDF jest natywny czy zeskanowany, aby przygotować tekst do tych narzędzi.
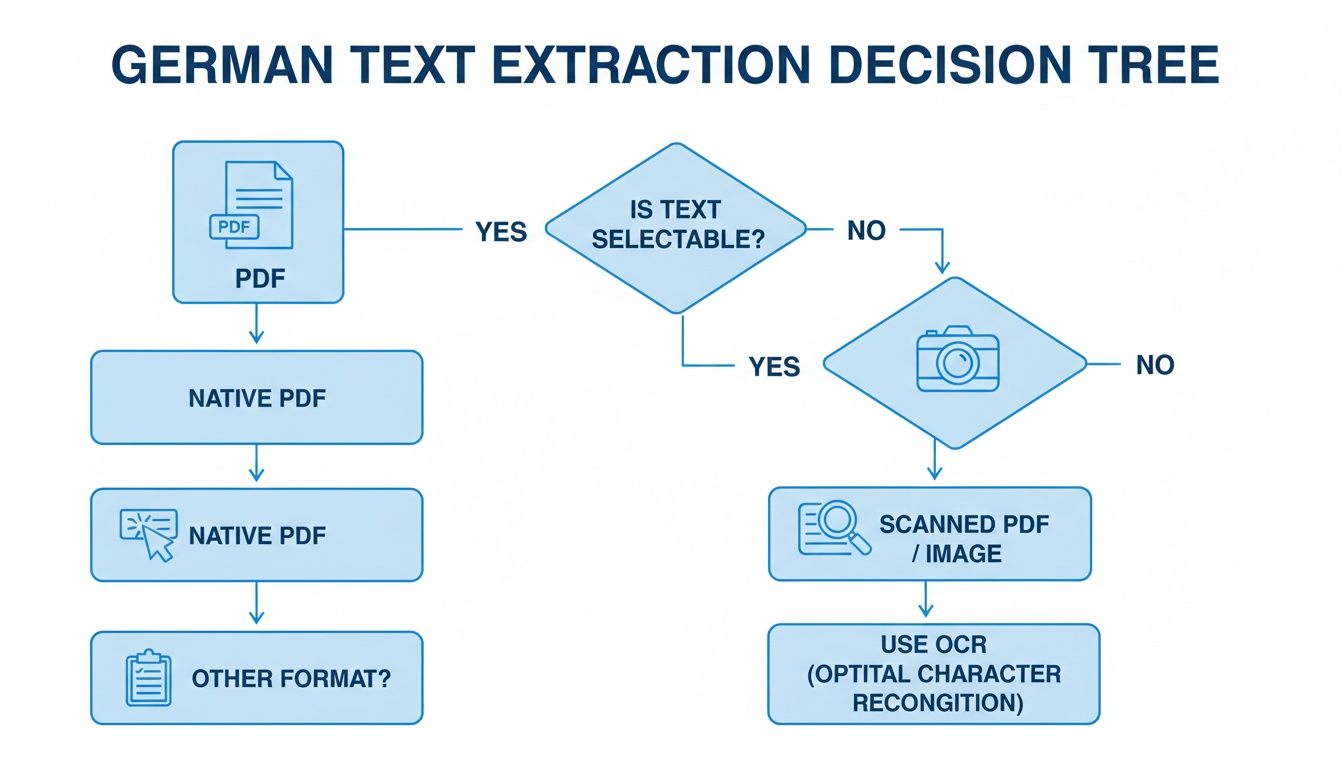
Jak widać, Twoja ścieżka się rozdziela w zależności od tego, czy tekst można wybierać (natywny) czy wymaga OCR (zeskanowany). Ten pierwszy wybór ustawia scenę dla wszystkiego, co następuje.
Klasyczny kompromis: szybkość kontra formatowanie
Dla szybkich, nieformalne prace, bezpłatne narzędzia online, takie jak DeepL lub Google Translate, są fantastyczne. Możesz wkleić wyodrębniony niemiecki tekst i uzyskać angielską wersję w kilka sekund. Jeśli po prostu chcesz zrozumieć istotę artykułu lub krótką wiadomość e-mail, to jest często wszystko, czego potrzebujesz.
Główna wada? Formatowanie. W momencie, gdy wkleisz przetłumaczony tekst z powrotem do nowego dokumentu, tracisz wszystko — nagłówki, pogrubiony tekst, kursywę, podziały akapitów i podziały rozdziałów. Ręczne przebudowywanie układu dla długiego dokumentu to druzgocące zadanie. Byłem tam i to nie jest zabawne.
- Scenariusz: Masz 10-stronicową niemiecką instrukcję obsługi w prostym formacie tekstowym. Musisz tylko zrozumieć instrukcje do użytku osobistego.
- Najlepsze podejście: Bezpłatny tłumacz online jest tutaj idealny. Szybkość jest warta minimalnego wysiłku ponownego czytania zwykłego tekstu.
Moja osobista wskazówka: Nawet w przypadku najlepszych narzędzi do tłumaczenia maszynowego, niemiecki na angielski może być trudny. Stwierdziłem, że DeepL często produkuje bardziej naturalne brzmienie tłumaczenia dla par języków europejskich ze względu na jego specjalne dane treningowe. To zwykle mój pierwszy krok do szybkiego sprawdzenia.
Gdy układ jest wszystkim: bardziej inteligentny przepływ pracy
Ale co, jeśli musisz przekonwertować niemiecki plik PDF na angielski i struktura jest nie do negocjacji? Pomyśl o artykule akademickim z cytatami, instrukcji technicznej z diagramami lub powieści z starannie ułożonymi rozdziałami. W przypadku tych projektów zachowanie układu jest równie ważne jak samo tłumaczenie.
To wymaga bardziej zaawansowanego przepływu pracy. Zamiast po prostu tłumaczyć surowy tekst, Twoim celem powinno być tłumaczenie całej struktury dokumentu.
Oto niezawodny sposób, aby to zrobić:
- Konwertuj na EPUB: Najpierw weź czysty niemiecki tekst i konwertuj go na plik EPUB. EPUB to format e-booka specjalnie zaprojektowany do przechowywania informacji strukturalnych, takich jak rozdziały, nagłówki i style.
- Użyj specjalistycznego narzędzia: Następnie użyj platformy zbudowanej do tłumaczenia strukturalnych dokumentów, takich jak BookTranslator.ai.
Ta metoda całkowicie omija utratę formatowania. Usługa taka jak BookTranslator.ai czyta niemiecki EPUB, tłumaczy zawartość, zachowując jednocześnie podstawowy kod dla nagłówków i rozdziałów, i wyświetla w pełni sformatowany angielski EPUB. Otrzymujesz profesjonalny, czytelny dokument, który odzwierciedla układ oryginału, oszczędzając Ci godzin ręcznego przeformatowania.
Eksploracja innych opcji oprogramowania do tłumaczenia dokumentów może dać Ci więcej kontekstu, dlaczego specjalistyczne narzędzia są często właściwym wyborem dla poważnych projektów.
Aby pomóc Ci zdecydować, oto szybkie zestawienie omówionych metod.
Porównanie metod tłumaczenia
Ta tabela oferuje jasne porównanie różnych metod tłumaczenia, pomagając Ci zdecydować, które podejście najlepiej odpowiada potrzebom Twojego projektu w zakresie szybkości, dokładności i formatowania.
| Metoda | Najlepsze dla | Zachowanie układu | Koszt |
|---|---|---|---|
| Bezpłatne narzędzia online | Szybkie, nieformalne przedstawienia krótkich dokumentów lub e-maili. | Brak. Tracisz całe formatowanie. | Bezpłatnie |
| Narzędzia CAT (Pro) | Profesjonalni tłumacze pracujący nad złożonymi projektami. | Wysoki. Zachowuje tagi i strukturę. | Wysoki (oprogramowanie i praca) |
| Konwertuj na EPUB i użyj BookTranslator.ai | Długie, strukturalne dokumenty, takie jak książki lub instrukcje, gdzie układ jest krytyczny. | Doskonały. Odzwierciedla oryginalny plik. | Umiarkowany (opłata za usługę) |
Ostatecznie, odpowiednie narzędzie zależy całkowicie od Twojego ostatecznego celu. Do szybkiego wyglądu, narzędzia bezpłatne są w porządku. Dla czegokolwiek, co musi wyglądać profesjonalnie i zachować oryginalną strukturę, inwestycja w specjalistyczny przepływ pracy zaoszczędzi Ci ogromnego bólu głowy.
Praktyczny przewodnik dla doskonałego formatowania
Gdy musisz przekonwertować niemiecki plik PDF na angielski i zachować profesjonalny układ, samo kopiowanie i wklejanie nie wystarczy. To podejście rozpada się na złożonych dokumentach, takich jak raporty biznesowe, artykuły akademickie czy całe książki.
W przypadku tych projektów potrzebujesz przepływu pracy, który szanuje strukturę dokumentu. Oto niezawodna technika, którą użyłem niezliczoną ilość razy: najpierw konwertuj dokument na plik EPUB. Ta metoda to nie tylko tłumaczenie słów; to tłumaczenie całego dokumentu — tekstu, rozdziałów, nagłówków i wszystkiego. To różnica między uzyskaniem czystej, profesjonalnej angielskiej wersji a bałaganem, który zajmuje godziny naprawy.
Od tekstu do strukturalnego EPUB
Przede wszystkim musisz umieścić czysty niemiecki tekst w pliku EPUB. Jeśli nie znasz EPUB, jest to format e-booka, który jest doskonały w zachowywaniu struktury dokumentu. Pomyśl o tym jako o planie, który mówi każdemu czytnikowi e-booka, gdzie zaczynają się rozdziały, jaki tekst jest nagłówkiem i jak powinny płynąć akapity.
Moje ulubione narzędzie do tego zadania to Calibre. To fantastyczne, bezpłatne oprogramowanie do zarządzania e-bookami, które konwertowanie plików na EPUB robi niezwykle proste.
- Przygotuj swój tekst: Weź niemiecki tekst, który wyodrębniłeś — skopiowany z natywnego pliku PDF lub wyciągnięty za pomocą OCR ze zeskanowanego — i zapisz go jako prosty plik .docx, a nawet .txt.
- Dodaj go do Calibre: Otwórz Calibre i po prostu przeciągnij i upuść swój niemiecki dokument do jego biblioteki.
- Konwertuj na EPUB: Wybierz książkę i kliknij przycisk „Konwertuj książki". Pojawi się nowe okno. W prawym górnym rogu ustaw format wyjściowy na EPUB. Calibre jest wystarczająco inteligentny, aby wykryć rozdziały i nagłówki z formatowania pliku źródłowego. Kliknij „OK" i masz idealnie strukturowany niemiecki EPUB gotowy do użycia.
Dlaczego to działa: Tworzenie EPUB w pierwszej kolejności to sekretny sos. Blokujesz strukturę dokumentu przed tłumaczeniem. To zapewnia, że ostateczna angielska wersja będzie odzwierciedlać profesjonalny układ oryginału, czego bezpośrednie tłumacze tekstowe po prostu nie mogą obsługiwać.
Tłumaczenie EPUB z precyzją
Teraz, gdy masz swój niemiecki EPUB, czas na tłumaczenie. W tym celu potrzebujesz narzędzia, które rozumie strukturalne pliki. To właśnie tutaj specjalistyczna usługa taka jak BookTranslator.ai robi wspaniałe wrażenie. Jest zaprojektowana specjalnie do przetwarzania formatów e-booków, tłumaczenia tekstu przy jednoczesnym pozostawieniu podstawowego kodu formatowania bez zmian.
Proces nie mógł być prostszy:
- Prześlij EPUB: Prześlij niemiecki EPUB, który właśnie utworzyłeś za pomocą Calibre. Platforma jest zbudowana do obsługi dużych plików, co czyni ją idealną dla długich raportów lub całych książek.
- Wybierz swoje języki: Ustaw źródło na niemiecki i cel na angielski.
- Przetłumacz: AI przystępuje do pracy, przetwarzając tekst w ramach jego tagów strukturalnych. Wie, że
<h1>to tytuł rozdziału i<p>to akapit, więc doskonale zachowuje tę hierarchię w przetłumaczonym wyniku.
To, co otrzymasz z powrotem, to w pełni przetłumaczony, doskonale sformatowany angielski EPUB. Możesz go otworzyć w dowolnym czytniku e-booków, a nawet użyć Calibre ponownie, aby przekonwertować go z powrotem do PDF, jeśli tego potrzebujesz. Ta metoda elegancko omija powszechne problemy z układem, dostarczając ostateczny dokument, który jest równie profesjonalny i czytelny jak oryginał.
Jeśli zacząłeś ze zeskanowanym dokumentem, możesz znaleźć nasz dedykowany przewodnik na temat sposobu tłumaczenia zeskanowanego pliku PDF przydatny dla tych początkowych kroków OCR.
Przeglądanie i ulepszanie angielskiego tłumaczenia

Więc przepuściłeś swój plik PDF przez tłumacza. Ciężka praca jest gotowa, ale nie wysyłaj jeszcze. Pomyśl o tym tekście wygenerowanym przez AI jako fantastycznym pierwszym szkicu — solidnej podstawie, a nie gotowym arcydziele. To jest krytyczny etap, na którym wkraczasz, aby wypolerować tłumaczenie, zapewniając, że brzmi jak napisane przez osobę, a nie program.
Tłumaczenie maszynowe dla typowych języków, takich jak niemiecki na angielski, stało się niezwykle dobre, a niektóre badania pokazują wskaźniki dokładności przekraczające 90%. Ale ten ostatni 10% to miejsce, gdzie może się ukrywać prawdziwy problem. To w tych marginesach, gdzie kontekst zostaje utracony, wiarygodność jest zagrożona i znaczenie się mąci.
AI może dosłownie przetłumaczyć powszechne niemieckie powiedzenie, co może prowadzić do bardzo mylących lub niezamierzenie śmiesznych wyników w języku angielskim. Ten ostateczny przegląd to wszystko o złapaniu tych błędów, zanim to zrobi Twoja publiczność.
Na co zwrócić uwagę podczas przeglądu
Gdy konwertujesz niemiecki plik PDF na angielski, Twój przebieg po edycji musi wykraczać daleko poza prosty spraw