
Haben Sie sich schon mal gefragt, wie massive Bücher so schnell übersetzt werden und dabei perfekte Konsistenz bewahrt bleibt? Es ist keine Magie, und es ist nicht rein eine Maschine, die die Arbeit verrichtet. Das Geheimnis liegt in einem Prozess namens Computer-Assisted Translation, oder CAT.
Es geht nicht darum, einen erfahrenen menschlichen Übersetzer durch KI zu ersetzen. Denken Sie eher an eine kraftvolle Partnerschaft. CAT-Tools sind ausgefeilte Assistenten, die sich wiederholende, speicherbasierte Aufgaben bewältigen und den menschlichen Experten so frei machen, um sich auf das zu konzentrieren, was er am besten kann: Nuancen erfassen, kulturelle Kontexte verstehen und die subtile Kunst der Sprache beherrschen.
Computer-Assisted Translation für PDFs verstehen

Stellen Sie sich einen Meisterkoch mit einem hochmodernen Sous-Chef vor. Der Küchenchef ist immer noch die kreative Kraft, der probiert, anpasst und jede kritische Entscheidung trifft. Aber der Sous-Chef erledigt die mühsame Vorbereitungsarbeit tadellos – Schneiden, Messen und perfektes Auswendiglernen jedes Rezepts. Genau so funktioniert CAT. Es ist eine Zusammenarbeit, keine automatisierte Fabrik.
Die Software „denkt" nicht für den Übersetzer und trifft keine kreativen Entscheidungen. Sie optimiert einfach den Arbeitsablauf, indem sie sich um Aufgaben kümmert, die Menschen anstrengend finden, aber Computer im Handumdrehen erledigen können.
Die Kernkomponenten von CAT-Software
Dieses menschliche und maschinelle Team erhält seine Kraft von zwei Hauptmerkmalen, die die Grundlage jedes ernsthaften Übersetzungsprojekts bilden:
- Translation Memory (TM): Dies ist eine lebendige Datenbank, die alles speichert, an dem ein Übersetzer je gearbeitet hat – jeden Satz, jede Phrase und jeden Absatz. Das nächste Mal, wenn ein ähnlicher Satz auftaucht, schlägt das TM sofort die vorherige Übersetzung vor. Dies spart eine unglaubliche Menge Zeit und hält die Sprache konsistent von Kapitel eins bis zum Anhang.
- Terminology Databases (Termbases): Denken Sie an eine Termbase als ein benutzerdefiniertes Glossar für Ihr spezifisches Projekt. Es ist eine Liste kritischer Begriffe, die müssen jedes einzelne Mal auf die gleiche Weise übersetzt werden. Für einen Fantasy-Roman könnte dies Charakternamen, magische Zaubersprüche oder fiktive Orte umfassen. Es ist das Tool, das Konsistenz gewährleistet.
Dieses kraftvolle Duo ist ein Hauptgrund für das Wachstum der Branche. Der Machine-Translation-Markt, der oft in CAT-Systeme integriert ist, wurde 2020 auf 153,8 Millionen USD geschätzt und ist auf dem Weg, bis 2026 230,67 Millionen USD zu erreichen. Effizienz ist das Spiel, besonders wenn man mit den massiven Wortmengen von Büchern zu tun hat.
Das Wichtigste, das man sich merken sollte, ist, dass CAT von Augmentation handelt, nicht von Automatisierung. Es verbessert menschliche Fähigkeiten und befreit Übersetzer, um sich auf die kreative und kulturelle Verfeinerung zu konzentrieren, die eine Übersetzung wirklich großartig macht.
Aber hier kommt der Haken, wenn Sie eine PDF ins Spiel bringen. Bevor dieses erstaunliche System funktionieren kann, muss die Software das Dokument lesen können. Eine PDF ist oft wie ein Bild von Text; Sie können die Wörter sehen, aber Sie können sie nicht einfach greifen, um damit zu arbeiten.
Das bedeutet, dass es einen entscheidenden ersten Schritt gibt, bevor irgendwelche Übersetzungsmagie stattfinden kann. Die Technologie dahinter, die es Maschinen ermöglicht, menschliche Sprache zu verstehen, ist faszinierend. Wenn Sie neugierig sind, wie es funktioniert, können Sie einen großartigen Überblick bekommen, indem Sie Natural Language Processing (NLP) erkunden.
Die einzigartigen Herausforderungen beim Übersetzen von PDF-Dateien
Also, warum ist das Übersetzen einer PDF so viel schwieriger als, sagen wir, ein einfaches Word-Dokument? Hier ist eine gute Möglichkeit, es zu sehen: Eine PDF ist wie eine Fotografie einer Buchseite. Sie können die Wörter und Bilder sehr gut sehen, aber Sie können sie nicht einfach anklicken und bearbeiten wie in einem normalen Textdokument. Dieses feste Format ist das Herz des Problems.
Dieses einzelne Problem wirft einen großen Schraubenschlüssel in jeden computer assisted translation PDF Arbeitsablauf. Bevor ein CAT-Tool überhaupt anfangen kann, seine Arbeit mit Translation Memory oder Glossaren zu tun, benötigt es sauberen, bearbeitbaren Text. Eine PDF kämpft von Natur aus bei jedem Schritt gegen Sie.
Digital-Native versus gescannte PDFs
Sie werden im Allgemeinen auf zwei Arten von PDFs stoßen, und jede bringt ihre eigenen Schwierigkeiten mit sich. Herauszufinden, mit welchem Typ Sie es zu tun haben, ist der erste Schritt.
- Digital-Native PDFs: Dies sind Dateien, die direkt aus Programmen wie Microsoft Word oder Adobe InDesign erstellt wurden. Der Text ist technisch vorhanden, aber er ist oft an Ort und Stelle gesperrt. Der Versuch, ihn herauszuziehen, kann sich anfühlen wie das Zerschmettern eines Sparschweins – ja, Sie bekommen die Münzen heraus, aber Sie sind mit einem Durcheinander von zerbrochenem Formatting und unterbrochenen Absätzen zurückgelassen.
- Gescannte PDFs: Diese sind noch schwieriger. Eine gescannte PDF ist im Grunde nur ein Bild, was bedeutet, dass der „Text" nichts anderes als ein Pixelmuster ist. Um es etwas zu machen, das ein Computer verstehen kann, müssen Sie es durch Optical Character Recognition (OCR) führen, einen Prozess, der das Bild scannt und diese Pixel zurück in digitalen Text konvertiert.
Ein großer Teil der PDF-Übersetzung ist einfach das Ringen mit diesen gescannten Dokumenten. Das Beherrschen, wie man den Text sauber extrahiert, ist eine kritische Fähigkeit. Um ein besseres Verständnis für diesen komplexen Prozess zu bekommen, lohnt es sich zu lernen, wie man gescannte PDF-Dateien übersetzt.
Häufige Fallstricke für Autoren
Ohne die richtigen Tools und einen Prozess stoßen Autoren, die versuchen, eine PDF zu übersetzen, auf eine Wand aus frustrierenden, zeitraubenden Problemen, die die endgültige Qualität ihres Buches ruinieren. Für einen tieferen Blick auf die Navigation dieser Herausforderungen ist unser Leitfaden zum Übersetzen einer gescannten PDF eine großartige Ressource.
Das grundlegende Problem mit einer PDF ist, dass sie zum Anzeigen, nicht zum Bearbeiten entworfen wurde. Ihr ganzer Zweck ist es, ein statisches visuelles Layout auf jedem Gerät zu bewahren, was genau das Gegenteil von dem ist, was ein Übersetzungsarbeitsablauf benötigt: flexibler, zugänglicher Inhalt.
Dieser grundlegende Konflikt führt zu all den klassischen Kopfschmerzen:
- Zerstörtes Formatting: Wenn Sie den Text endlich herausreißen, können diese sauberen Spalten und ordentlich organisierten Absätze sich in ein chaotisches Durcheinander verwandeln.
- Nicht bearbeitbare Grafiken: Jeder Text, der Teil eines Bildes ist, wie in einem Diagramm oder einer Abbildung, bleibt gesperrt. Er ist ohne ernsthafte Bildbearbeitung nicht übersetzbar.
- Ungenaue Textextraktion: OCR ist eine leistungsstarke Technologie, aber sie ist nicht fehlerfrei. Sie kann Zeichen falsch lesen, Tippfehler einführen oder bei minderwertigen Scans völlig fehlschlagen. Das bedeutet, dass jemand den gesamten Text mühsam Korrektur lesen muss, bevor die Übersetzung überhaupt beginnen kann.
Diese Probleme sind genau der Grund, warum ein professioneller, werkzeuggestützter Ansatz nicht nur ein Nice-to-Have ist; er ist essentiell für ein hochwertiges Ergebnis.
Ihr Schritt-für-Schritt PDF-Übersetzungs-Arbeitsablauf
In ein computer assisted translation PDF Projekt zu springen, besonders für etwas so Komplexes wie ein Buch, kann sich überwältigend anfühlen. Aber wenn Sie es in einen klaren, methodischen Arbeitsablauf aufteilen, wird der Prozess viel überschaubarer. Diese Roadmap führt Sie durch die gesamte Reise, von dieser gesperrten PDF zu einem perfekt übersetzten, veröffentlichungsfertigen Buch.
Die echte Arbeit beginnt lange bevor das erste Wort übersetzt wird. Die erste, und wohl wichtigste, Phase dreht sich alles um Vorbereitung. Denken Sie daran, wie das Fundament für ein Haus zu legen – wenn Sie diesen Teil nicht richtig machen, wird alles, das Sie darauf aufbauen, instabil sein. Das Ziel hier ist, Ihre statische PDF in ein Format zu bringen, das Übersetzungssoftware tatsächlich lesen kann.
Phase 1: Vorbereitung und Textextraktion
Ihre erste Aufgabe ist es, den Text aus der starren Struktur der PDF zu befreien. Wie Sie das tun, hängt ganz davon ab, mit welcher Art von PDF Sie es zu tun haben: eine, die digital geboren wurde, oder eine, die ein Scan eines physischen Dokuments ist.
Der Weg, den Sie ganz am Anfang einschlagen, ändert sich basierend auf dem Ursprung der PDF.
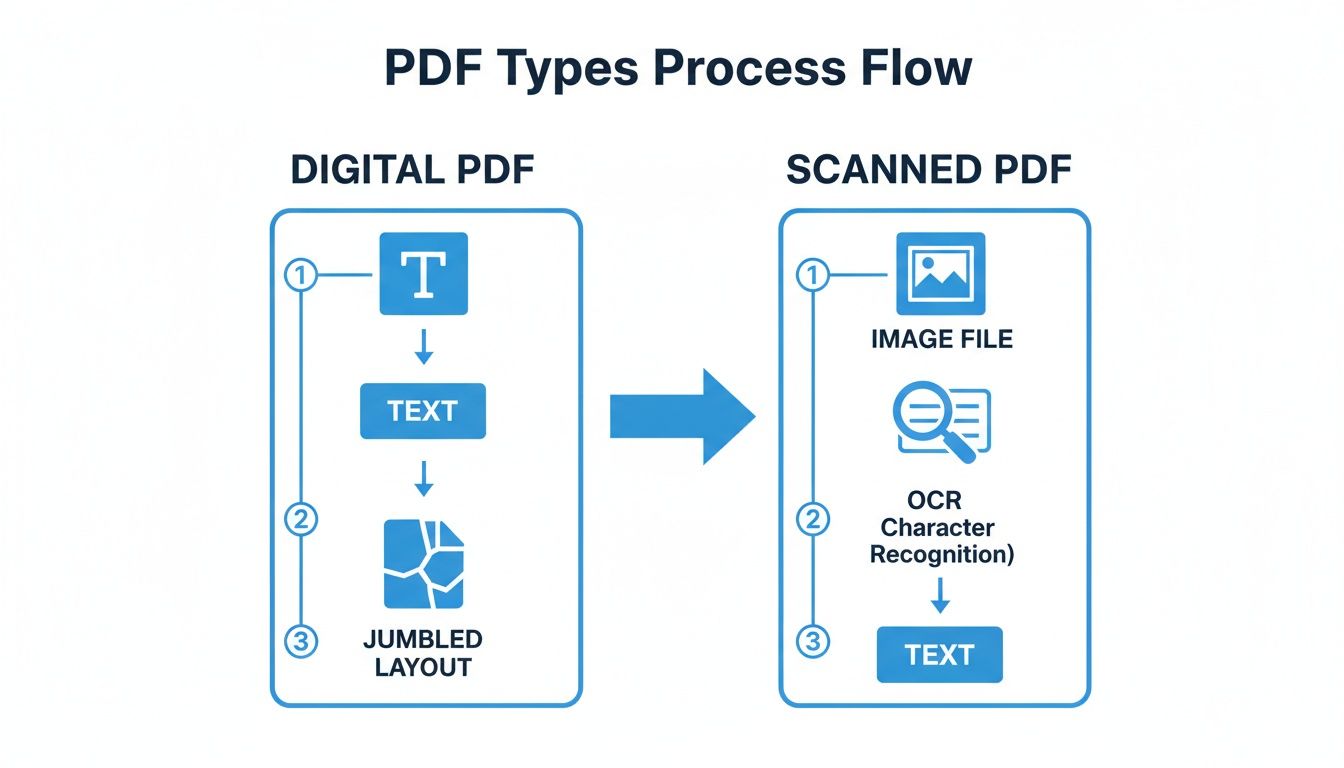
Wie Sie sehen können, führen beide Pfade zu extrahiertem Text, aber die gescannte PDF fügt einen kniffligen zusätzlichen Schritt hinzu: OCR.
Für gescannte Bücher bedeutet dies, die Seiten durch Optical Character Recognition (OCR) Software zu führen. Seien Sie gewarnt: Dieser Prozess ist selten fehlerfrei. Er spuckt oft Fehler aus wie falsch gelesene Buchstaben („l" statt „1") oder seltsam zusammengefügte Wörter. Deshalb ist eine sorgfältige Bereinigung und Korrekturlesen des extrahierten Textes absolut essentiell, bevor Sie etwas anderes tun.
Um Ihnen ein klareres Bild zu geben, hier ist eine Aufschlüsselung des gesamten Arbeitsablaufs von Anfang bis Ende.
CAT-Arbeitsablauf-Phasen für die PDF-Übersetzung
Diese Tabelle skizziert die wesentlichen Phasen in einem Computer-Assisted-Translation-Arbeitsablauf für eine PDF-Datei und zeigt, was bei jedem Schritt passiert und welche Tools beteiligt sind.
| Phase | Ziel | Gängige Tools oder Techniken |
|---|---|---|
| 1. Textextraktion | Konvertieren Sie die PDF in ein bearbeitbares Textformat, das ein CAT-Tool verarbeiten kann. | Adobe Acrobat Pro, Abbyy FineReader (für OCR), verschiedene Online-Konverter. |
| 2. CAT-Import | Importieren Sie den sauberen Text in eine CAT-Umgebung und teilen Sie ihn in Segmente auf. | Trados Studio, MemoQ, Phrase, Smartling. |
| 3. Übersetzung | Übersetzen Sie den Text Segment für Segment und nutzen Sie dabei TM- und Termbase-Assets. | Menschlicher Linguist, der im Editor des CAT-Tools arbeitet. |
| 4. Qualitätssicherung | Führen Sie automatisierte und manuelle Prüfungen durch, um Inkonsistenzen, Fehler und Formatierungsprobleme zu finden. | Eingebaute QA-Checker in CAT-Tools (z. B. Xbench), manuelle Korrekturlesen. |
| 5. Layout (DTP) | Erstellen Sie das ursprüngliche Buchenlayout mit dem übersetzten Text und Grafiken neu. | Adobe InDesign, QuarkXPress, Affinity Publisher. |
Jede dieser Phasen baut auf der vorherigen auf und stellt sicher, dass das endgültig übersetzte Buch genau, konsistent und professionell formatiert ist.
Phase 2: CAT-Umgebung und Übersetzung
Mit Ihrem sauberen, bearbeitbaren Text ist es an der Zeit, in die CAT-Umgebung zu gehen. Hier passiert die Magie, mit leistungsstarken Softwarefunktionen, die Konsistenz sicherstellen und die Arbeit beschleunigen.
- Import und Segmentierung: Sie beginnen damit, den Text in Ihr CAT-Tool zu importieren. Die Software zerlegt den Text dann automatisch in kleinere Chunks, sogenannte Segmente, die normalerweise Sätze oder Phrasen sind.
- Nutzung von Assets: Während der Übersetzer jedes Segment durcharbeitet, schlägt das Tool aktiv Übereinstimmungen aus dem Translation Memory (TM) vor. Gleichzeitig markiert die Termbase (Ihr Projekt-Glossar) Schlüsselbegriffe, um sicherzustellen, dass sie jedes Mal, wenn sie erscheinen, auf die gleiche Weise übersetzt werden.
- Menschliche Übersetzung und Überprüfung: Hier übernimmt der menschliche Experte. Ein professioneller Übersetzer wird die Vorschläge der Software akzeptieren, ablehnen oder anpassen und dabei seine sprachlichen Fähigkeiten nutzen, um den richtigen Ton, kulturelle Nuancen und präzise Bedeutung zu erfassen. Dieser Schritt ist das, was eine hochwertige Übersetzung von einer unbeholfenen, maschinengenerierten unterscheidet.
Der Einfluss von KI in diesem Bereich ist unmöglich zu ignorieren. Der KI-Sprachübersetzungsmarkt explodierte von 1,88 Milliarden USD im Jahr 2023 auf 2,34 Milliarden USD im Jahr 2024, ein klares Zeichen der massiven Nachfrage nach diesen Tools. Es verändert auch, wie Profis arbeiten, mit 70% der europäischen Sprachfachleute, die nun Maschinenübersetzung als Teil ihres täglichen Arbeitsablaufs nutzen. Sie können mehr über den Aufstieg der KI in der Übersetzung auf sonix.ai erfahren.
Die CAT-Umgebung ist das Herz des Arbeitsablaufs. Hier verschmelzen Technologie und menschliches Fachwissen, wobei gespeichertes Wissen (TM und Glossare) genutzt wird, um Schicht für Schicht eine konsistente, hochwertige Übersetzung aufzubauen.
Phase 3: Qualitätssicherung und finales Layout
Sobald jeder Satz übersetzt wurde, verschiebt sich der Fokus auf Polieren und Präsentation. Das ist die Zielgerade.
Zunächst führen Sie eine Serie von automatisierten Quality Assurance (QA) Prüfungen durch. Diese Tools sind entwickelt, um die Art von Fehlern zu finden, die das menschliche Auge leicht übersehen kann, wie inkonsistente Terminologie, Zahlenformatierungsfehler oder zusätzliche Leerzeichen. Denken Sie daran als digitales Sicherheitsnetz.
Schließlich wird der übersetzte Text an die Desktop Publishing (DTP) Phase übergeben. Hier öffnet ein professioneller Designer ein Programm wie Adobe InDesign und baut das ursprüngliche Layout Ihres Buches sorgfältig neu auf. Sie fügen Bilder erneut ein, formatieren den neuen Text, damit er passt, und stellen sicher, dass das endgültig übersetzte Buch eine perfekte visuelle Übereinstimmung mit dem Original ist. Es ist ein mühsamer, aber absolut kritischer letzter Schritt.
Wesentliche Tools für die Computer-Assisted PDF-Übersetzung

Um eine PDF erfolgreich mit Computer-Assisted-Methoden zu übersetzen, brauchen Sie mehr als nur ein Stück Software. Es geht darum, einen spezialisierten digitalen Werkzeugkasten zusammenzustellen. Jedes Tool hat eine sehr spezifische Aufgabe: Den Text sorgfältig aus der PDF zu ziehen, Ihnen beim Übersetzen zu helfen und dann alles in einer neuen Sprache wieder zusammenzusetzen, damit es genau wie das Original aussieht.
Denken Sie daran wie an eine dreistufige Werkstatt für Ihr Buch. Zuerst müssen Sie das Original sorgfältig auseinandernehmen. Zweitens bauen Sie die Kernkomponenten – die Wörter selbst – in der Zielsprache wieder auf. Schließlich kümmern Sie sich um die endgültige Montage und die letzten Schliffe. Jede Stufe braucht das richtige Werkzeug für die Arbeit.
Den Text mit Konvertern und OCR entsperren
Der allererste Schritt ist oft der kniffligste. Sie brauchen eine Möglichkeit, den Text aus dem festen, „flachen" PDF-Format freizuschalten. Für die Übersetzung ganzer Bücher ist es absolut kritisch, diese erste Phase richtig zu machen.
Ihre Hauptwerkzeuge dafür sind:
- PDF-Konverter: Wenn Ihre PDF ursprünglich aus einem Programm wie Word erstellt wurde, kann ein guter Konverter wie Adobe Acrobat Pro sie oft sauber in ein bearbeitbares Format zurückexportieren. Dies ist immer das beste Szenario.
- OCR-Software: Für gescannte Bücher oder PDFs, die im Grunde nur Bilder von Text sind, benötigen Sie Optical Character Recognition (OCR). Ein leistungsstarkes Tool wie ABBYY FineReader ist konzipiert, um das Bild jeder Seite zu „lesen" und die Formen der Buchstaben zurück in tatsächlichen, bearbeitbaren Text zu konvertieren.
Ohne eines dieser Tools ist Ihre PDF eine verschlossene Kiste. Sie sind die Torwächter Ihres Inhalts, die ihn für die Übersetzungstools, die als nächstes kommen, zugänglich machen.
Das Übersetzungs-Engine: CAT-Tools
Sobald der Text frei ist, bewegt er sich zum Herzen der Operation: dem CAT-Tool. Dies ist, wo die Fähigkeiten des Übersetzers auf leistungsstarke Software treffen, um eine genaue und, am wichtigsten, konsistente Übersetzung zu produzieren.
Professionelle CAT-Tools wie Trados Studio oder memoQ sind um zwei Merkmale herum gebaut, die absolut essentiell für Projekte in Buchgröße sind. Ihr ganzer Zweck ist es, Konsistenz von Seite eins bis zum letzten Kapitel sicherzustellen.
Translation Memory (TM): Denken Sie daran als das persönliche Gedächtnis Ihres Projekts. Es speichert jeden Satz, den Sie übersetzen. Wenn dieser gleiche Satz – oder ein sehr ähnlicher – wieder auftaucht, schlägt das TM sofort die vorherige Übersetzung vor.
Terminology Management (Termbase): Dies ist ein benutzerdefiniertes Glossar für Ihr Buch. Es stellt sicher, dass Schlüsselbegriffe, wie Charakternamen, Orte oder einzigartige Konzepte, jedes einzelne Mal, wenn sie erscheinen, genau auf die gleiche Weise übersetzt werden.
Diese Software wird zentral für die globale Kommunikation. Der Sprachübersetzungssoftware-Markt, bewertet auf 10,72 Milliarden USD im Jahr 2024, wird erwartet, bis 2033 auf 18,26 Milliarden USD zu wachsen, wobei die Dokumentenübersetzung sein größtes Stück ist. Dieses Wachstum zeigt einfach, wie vital diese Tools geworden sind. Sie können mehr über diese Markttrends auf researchnester.com lesen.
Die Visuals mit DTP-Software neu aufbauen
Nach Abschluss der Übersetzung bleibt Ihnen ein Block aus reinem Text. Der letzte, kritische Schritt ist es, diesen Text zurück in das ursprüngliche Layout des Buches zu bringen, komplett mit Bildern und professioneller Formatierung. Dies ist die Aufgabe der Desktop Publishing (DTP) Software.
Branchenstandard-Programme wie Adobe InDesign werden für diese Phase verwendet. Ein erfahrener Designer nimmt den übersetzten Text und platziert ihn sorgfältig zurück in das Layout, fügt Bilder erneut ein, passt Abstände an, um die Texterweiterung zu berücksichtigen, und stellt sicher, dass das fertige Buch ein perfektes Spiegelbild des Originals ist. Dies ist ein praktischer Prozess, der einen Designer-Blick erfordert, nicht einen automatisierten Schritt. Unser Leitfaden zu Dokumentenübersetzungssoftware geht tiefer in diese Art von Tools ein.
Best Practices für die Übersetzung Ihres PDF-Buches
Eine Buchübersetzung richtig zu machen, besonders wenn Sie mit einer PDF anfangen, ist alles eine Frage der Strategie. Wenn Sie ohne einen Plan hineinspringen, können Sie leicht in einem frustrierenden, teuren Durcheinander landen. Aber durch Befolgen einiger bewährter Best Practices können Sie den Prozess reibungslos navigieren und ein Ergebnis erhalten, das Ihrem Originalwerk Gerechtigkeit widerfährt.
Die erste und bei weitem wichtigste Regel ist diese: Suchen Sie immer zuerst nach der Originaldatei. Bevor Sie überhaupt daran denken, die PDF anzugehen, tun Sie alles, um die Datei zu finden, aus der sie erstellt wurde, ob das ein Adobe-InDesign-Projekt, ein Microsoft-Word-Dokument oder etwas anderes ist. Dieser eine Schritt kann Sie vor einer Welt voller Schmerz bewahren und umgeht den kniffligen und zeitaufwändigen Prozess der Textextraktion und des Neubaus des Layouts von Grund auf.
Bewerten Sie Ihren Startpunkt
Okay, Sie haben alles versucht und die PDF ist alles, was Sie haben. Was nun? Ihr nächster Schritt ist herauszufinden, genau welche Art von PDF Sie haben. Eine saubere, digital erstellte PDF ist ein völlig anderes Tier als eine verschwommene, gescannte.
Ein schneller Weg, das zu testen, ist, das Dokument zu öffnen und zu versuchen, den Text mit Ihrem Cursor hervorzuheben. Wenn Sie einzelne Wörter und Sätze auswählen können, sind Sie in guter Form. Das bedeutet, der Text ist „live" und kann wahrscheinlich sauber extrahiert werden.
Wenn Sie nichts auswählen können, haben Sie eine bildbasierte PDF in den Händen, was bedeutet, dass Sie auf dem Weg zur OCR-Phase sind. Der Erfolg dieses Prozesses hängt ganz von der Qualität des Scans ab.
- Überprüfen Sie auf Klarheit und Auflösung: Sind die Buchstaben scharf und knackig, oder sehen sie etwas verschwommen aus? Hochauflösende Scans geben der OCR-Software viel bessere Chancen, alles richtig zu machen.
- Suchen Sie nach komplexen Layouts: Halten Sie Ausschau nach kniffligem Formatting. Dinge wie mehrere Spalten, Text, der um Bilder herumfließt, und viele Tabellen können Extraktionstools leicht verwirren.
- Identifizieren Sie handschriftliche Notizen: OCR-Technologie ist berüchtigt dafür, schlecht Handschrift zu lesen. Alle gekritzelten Notizen oder Markierungen müssen fast sicher manu