
所以,你有一份德文PDF需要翻译成英文。在你甚至考虑使用翻译软件之前,有一项关键检查你必须做。这是区分五分钟工作和多小时麻烦的区别。你需要判断你的PDF是"原生"还是"扫描"的。
从一开始就把这件事做对是一切的关键。它决定了你将使用的工具、你将采取的步骤,以及最终你的英文文档的质量。
首先,判断你处理的是什么类型的德文PDF

并非所有PDF都是相同的。真正的问题是:你的文档是生来就是数字形式,还是只是一张纸质页面的图片?
原生PDF是在计算机上创建并直接从Word或Adobe InDesign等程序保存的文档。其中的文本是真实的、活动的文本。你可以点击它、高亮一个句子,并将其复制粘贴到另一个应用程序中。这是最好的情况。
扫描PDF则基本上是一张照片。有人拿了一份物理文档——比如一份旧合同、书中的一页或一份已签署的表格——并通过扫描仪扫描它。对你的计算机来说,该文件不是文本;它只是由像素组成的一张大图像。你无法选择单个单词,就像你在JPEG中无法选择单词一样。
如何区分它们:两秒测试
幸运的是,识别你的PDF类型非常简单。只需打开文件并尝试以下操作:
- 你能点击并拖动光标来高亮一个句子吗?如果文本变成蓝色(或你系统的高亮颜色),恭喜。你有一份原生PDF。你的下一步将是提取这个文本。
- 你的光标是否在页面的一部分周围绘制一个框?如果你无法选择单个单词,只能选择矩形区域,那么你看的是扫描PDF。这意味着在你能做任何其他事情之前,你需要使用光学字符识别(OCR)。
这个简单的测试是不可商量的。尝试将扫描的PDF输入到基于文本的翻译工具中只会导致错误消息或完全空白的文档。你必须先将图像转换为文本。
对这类文档智能的需求是巨大的。德国语言翻译软件市场在2024年达到约54亿美元,并有望翻番,预计到2035年达到97亿美元。你可以阅读更多关于这一增长的信息,看看技术的发展方向。
为了更清楚,这里是差异的快速分解。
原生PDF与扫描PDF快速对比
该表格分解了原生PDF和扫描PDF之间的关键差异,以帮助你快速识别文件类型并了解每种类型的翻译路径。
| 特征 | 原生PDF | 扫描PDF(基于图像) |
|---|---|---|
| 创建方法 | 直接从软件应用程序(如Word、InDesign)保存。 | 通过扫描物理纸质文档创建。 |
| 文本可选择? | 是的,你可以高亮、复制和粘贴文本。 | 否,文本是平面图像的一部分。 |
| 可搜索? | 是的,你可以使用Ctrl+F(或Cmd+F)来查找单词。 | 否,在执行OCR之前不可搜索。 |
| 典型用例 | 报告、电子书、现代学术论文、发票。 | 旧档案、已签署合同、历史文档、信件。 |
| 翻译路径 | 直接文本提取→翻译 | OCR提取文本→翻译 |
知道你的起点是成功的一半。如果你有一份现代大学论文,它几乎肯定是原生PDF。如果它是来自历史档案的数字化记录,你可以打赌它是扫描的。提前识别这一点会为你设置正确的路径,以实现平稳和准确的翻译。
为翻译准备德文文本
所以,你已经判断出你的PDF是原生的还是扫描的。很好。接下来的步骤是以干净、可用的格式提取德文文本。这不仅仅是一个简单的复制粘贴工作;把它看作是为高质量翻译奠定基础。你在这个阶段的处理方式直接影响最终英文文档的质量。
对于原生PDF,文本已经存在,准备好被选择。但如果你只是用光标拖过所有内容并将其粘贴到翻译工具中,你可能会得到一堆破碎的行和混乱的段落。对于任何具有多列布局的内容尤其如此。诀窍是使用一种理解并尊重文档原始结构的方法。
从原生PDF提取文本
一个更好的方法是使用专用的PDF转文本转换器或适当的PDF编辑器。这些工具旨在分析文档如何流动并按正确的阅读顺序提取文本。采取这个额外的步骤可以节省你大量的时间,否则你会花费在手动修复行断和重新排序句子上,甚至在你将德文PDF转换为英文之前。
想象一篇两列的学术论文。如果你只是复制粘贴,文本会在每一行从左列跳到右列,使其完全无法阅读。一个好的提取工具会一直读到第一列的底部,然后再移动到第二列,就像人类会做的那样。
为扫描的德文文档使用OCR
如果你处理的是扫描的PDF,你需要通过光学字符识别(OCR)运行它。这项技术基本上"读取"页面的图像并将其转换为可编辑的数字文本。现代OCR很棒,但用德文正确使用它需要注意一些具体细节。
为了获得最准确的结果,请记住以下几点:
- 语言设置:这很关键。始终将OCR软件的语言设置为德文。这告诉工具期望并正确识别特殊字符,如元音变音(ä, ö, ü)和Eszett(ß),这大大提高了准确性。
- 图像质量:清晰、高分辨率的扫描会产生巨大的差异。如果你的PDF模糊、黑暗或对比度低,OCR输出将充满错误。
- 校对:永远不要假设OCR是完美的。在翻译之前,花几分钟扫描提取的德文文本以查找明显的错误。这是一个小时间投资,但会带来巨大的回报。
这种精确性很重要。德国的语言服务市场是欧洲最大的,语言服务提供商(LSP)在2017年产生了超过12.5亿欧元的收入。该国是翻译技术的主要参与者,所以工具是存在的。你可以在这里了解更多关于德国语言技术行业的信息。
关键要点:你的文本提取质量——无论是来自原生PDF还是通过OCR——直接决定了最终翻译的最高可能质量。这是古老的"垃圾进,垃圾出"原则。干净的源文本是获得准确、可读的英文文档的唯一方法。
如需深入了解此过程,请查看我们的OCR和翻译指南。
3. 为你的项目选择合适的翻译工具
好的,你已经成功地从PDF中提取了干净的德文文本。现在到了关键部分:选择如何实际翻译它。这不仅仅是关于选择你在谷歌上找到的第一个工具。这是关于将方法与你的具体目标相匹配,因为你的选择会直接影响最终文档的速度、成本,最重要的是,它的专业外观。
对好的翻译的需求是巨大的。该市场预计将在2024年达到417.8亿美元,主要是因为75%的人更喜欢用自己的语言购买产品。显然,正确的翻译很重要。如果你好奇,你可以深入了解这些翻译市场趋势。
下面的决策树总结了我们涵盖的第一个关键步骤——判断你的PDF是原生的还是扫描的,以为这些工具准备你的文本。
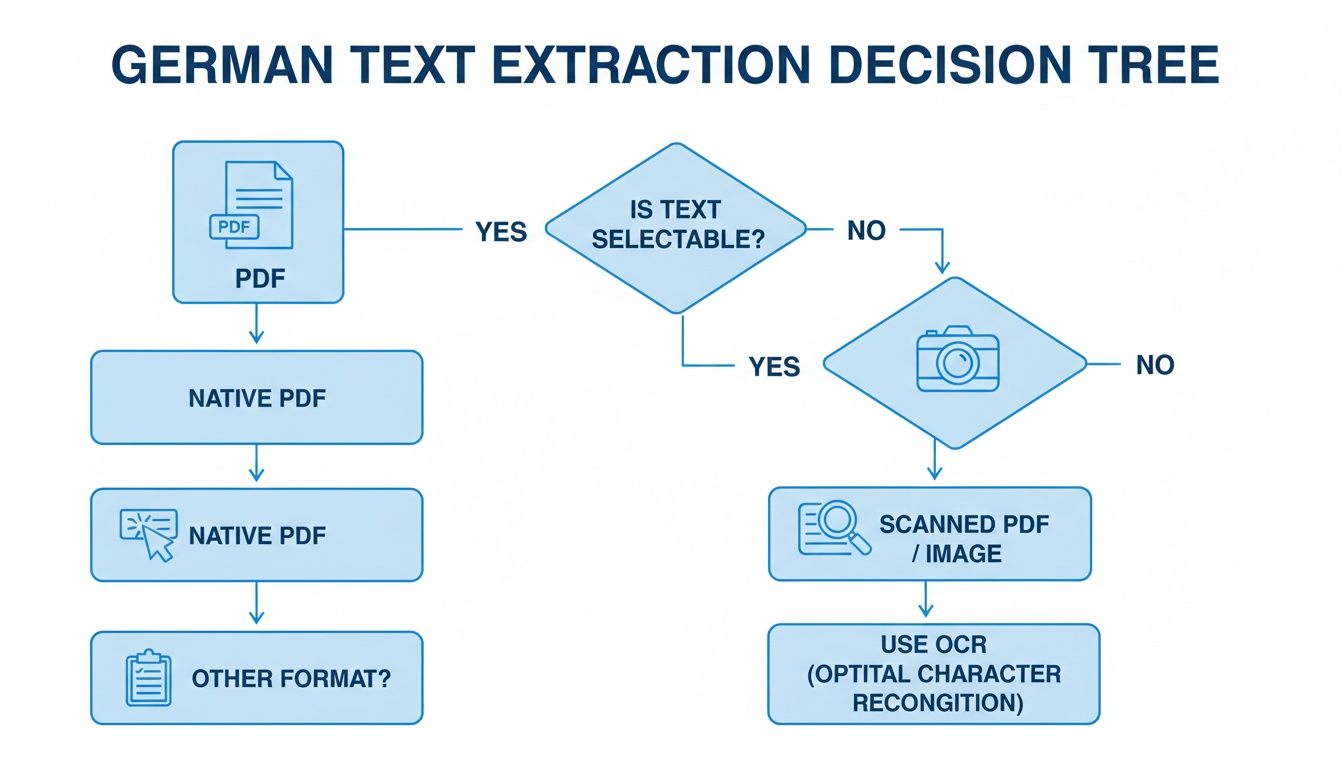
如你所见,你的路径根据文本是否可选择(原生)或需要OCR(扫描)而分开。这第一个选择为之后的一切奠定了基础。
经典权衡:速度与格式
对于快速、非正式的工作,免费在线工具如DeepL或谷歌翻译很棒。你可以粘贴提取的德文文本并在几秒内获得英文版本。如果你只需要理解文章的要点或一封短邮件,这通常是你所需要的全部。
主要缺点?格式。一旦你将翻译后的文本粘贴回新文档中,你会失去一切——标题、粗体文本、斜体、段落断开和章节分隔。手动重建长文档的布局是一项令人沮丧的任务。我经历过,这不是很有趣。
- 场景:你有一份10页的德文用户手册,格式简单。你只需要理解说明以供个人使用。
- 最佳方法:免费在线翻译工具在这里是完美的。速度值得最少的努力重新阅读纯文本。
我的个人建议:即使使用最好的机器翻译工具,德英翻译也可能很棘手。我发现DeepL经常为欧洲语言对产生更自然的翻译,因为它的特定训练数据。它通常是我快速检查的第一站。
当布局是一切:更聪明的工作流
但如果你需要将德文PDF转换为英文并且结构是不可协商的呢?想象一篇有引用的学术论文、一份有图表的技术手册或一部有精心布置章节的小说。对于这些项目,保留布局与翻译本身一样重要。
这是你需要更高级工作流的地方。与其只是翻译原始文本,你的目标应该是翻译整个文档结构。
这是一个可靠的方法:
- 转换为EPUB:首先,将你的干净德文文本转换为EPUB文件。EPUB是一种电子书格式,专门设计来保存结构信息,如章节、标题和样式。
- 使用专业工具:接下来,使用为翻译结构化文档而构建的平台,如BookTranslator.ai。
这种方法完全避免了格式丢失。像BookTranslator.ai这样的服务读取德文EPUB,在保持标题和章节的底层代码完整的情况下翻译内容,并输出完全格式化的英文EPUB。你最终得到一份专业、可读的文档,镜像原始的布局,节省你数小时的手动重新格式化。
探索其他翻译文档的软件选项可以让你更多地了解为什么专业工具通常是严肃项目的正确选择。
为了帮助你决定,这是我们讨论过的方法的快速分解。
翻译方法对比
该表格提供了不同翻译方法的清晰对比,帮助你决定哪种方法最适合你的项目对速度、准确性和格式的需求。
| 方法 | 最适合 | 布局保留 | 成本 |
|---|---|---|---|
| 免费在线工具 | 快速、非正式的短文档或邮件要点。 | 无。你会失去所有格式。 | 免费 |
| CAT工具(专业) | 在复杂项目上工作的专业翻译者。 | 高。保留标签和结构。 | 高(软件和劳动力) |
| 转换为EPUB并使用BookTranslator.ai | 长的、结构化的文档,如书籍或手册,其中布局很关键。 | 优秀。镜像原始文件。 | 中等(服务费) |
最终,正确的工具完全取决于你的最终目标。对于快速查看,免费工具是可以的。对于任何需要看起来专业并保持其原始结构的东西,投资一点在专业工作流中将节省你巨大的麻烦。
完美格式的实用演练
当你需要将德文PDF转换为英文并保持专业布局完整时,只是复制和粘贴是不行的。这种方法在商业报告、学术论文或整本书等复杂文档中会崩溃。
对于这些项目,你需要一个尊重文档结构的工作流。这是我无数次使用过的可靠技术:首先将文档转换为EPUB文件。这种方法不仅仅是关于翻译单词;它是关于翻译整个文档——文本、章节、标题和所有内容。这是获得干净、专业的英文版本和花费数小时修复的混乱之间的区别。
从文本到结构化EPUB
首先,你需要将你的干净德文文本放入EPUB文件。如果你不熟悉,EPUB是一种电子书格式,在保留文档结构方面非常出色。把它看作是一个蓝图,告诉任何电子阅读器章节从哪里开始、什么文本是标题,以及段落应该如何流动。
我做这项工作的首选工具是Calibre。它是一个很棒的、免费的电子书管理软件,使将文件转换为EPUB变得轻而易举。
- 准备你的文本:取出你提取的德文文本——无论是从原生PDF复制还是使用OCR从扫描的文本中提取。将其保存为简单的.docx甚至.txt文件。
- 添加到Calibre:打开Calibre并简单地将你的德文文档拖放到其库中。
- 转换为EPUB:选择书籍并点击"转换书籍"按钮。一个新窗口会弹出。在右上角,将输出格式设置为EPUB。Calibre足够聪明,可以从源文件的格式中检测章节和标题。点击"确定",你就有一份完美结构化的德文EPUB准备好了。
为什么这有效:首先创建EPUB是秘密武器。你在翻译之前锁定了文档的结构。这确保最终的英文版本将镜像原始的专业布局,这是直接文本翻译工具根本无法处理的。
用精确度翻译EPUB
现在你有了德文EPUB,是时候进行翻译了。为此,你需要一个理解结构化文件的工具。这是BookTranslator.ai这样的专业服务闪耀的地方。它专门设计用于处理电子书格式,翻译文本同时保留底层格式代码不变。
这个过程再简单不过了:
- 上传EPUB:上传你刚用Calibre创建的德文EPUB。该平台旨在处理大文件,非常适合长报告或整本书。
- 选择你的语言:将源设置为德文,目标设置为英文。
- 翻译:AI开始工作,处理其结构标签内的文本。它知道
<h1>是章节标题,<p>是段落,所以它在翻译后的输出中完美地保持了该层级。
你得到的是一份完全翻译、格式完美的英文EPUB。你可以在任何电子阅读器中打开它,甚至可以再次使用Calibre将其转换回PDF(如果这是你需要的)。这种方法优雅地避免了常见的布局麻烦,提供了一份与原始一样专业和可读的最终文档。
如果你从扫描的文档开始,你可能会发现我们关于如何翻译扫描的PDF的专门指南对于那些初始OCR步骤很有用。
审查和完善你的英文翻译

所以,你已经通过翻译工具运行了你的PDF。繁重的工作完成了,但不要急着发送。把AI生成的文本看作一个很棒的初稿——一个坚实的基础,而不是完成的杰作。这是关键阶段,你要介入以打磨翻译,确保它听起来像是由人写的,而不是程序。
对于德英等常见语言的机器翻译已经变得非常好,一些研究显示准确率达到90%。但最后10%是真正的麻烦可能隐藏的地方。正是在这些边界中,上下文会丢失,可信度会冒险,意义会变得混乱。
AI可能会逐字翻译一个常见的德文短语,这可能导致英文中出现一些非常令人困惑或无意中搞笑的结果。这个最后的审查是关于在你的观众发现这些错误之前捕获它们。
在你的审查中要寻找什么
当你将德文PDF转换为英文时,你的编辑后传递需要远远超过简单的拼写检查。你在寻找自动化工具几乎总是会错过的细微错误。
这是我总是关注的:
- 文化细微差别:语气对吗?德文商业写作通常比其英文对应物更正式。直译可能听起来很生硬或过度要求。你可能需要软化语言以符合英语使用者的文化期望。
- 习语短语:对无法逐字翻译的表达要高度警惕。经典的德文短语"Das ist mir Wurst"逐字翻译为"那对我来说是香肠"。AI可能会理解它,但它也可能让你留下一个奇怪的、无意义的句子。实际的意思是"我不在乎",你的最终文本需要反映这个意图。
- 技术术语:这对专业文档来说是一个大问题。如果你在处理工程手册或医学报告,你必须验证每个技术术语都是英文中的正确行业标准等价物。自动化工具可能选择一个似是而非但不正确的术语,这可能会产生严重的后果。
- 语气和声音:翻译是否捕捉了文档的原始感觉?学术论文需要听起来学术和精确。营销手册应该是吸引人和有说服力的。通常,AI翻译将这种声音压平为某种通用和机械化的东西。你的工作是将这种个性注入回去。
即使有今天的强大工具,上下文也是一切。机器缺乏真实世界的经验。它不总是知道德文单词"Bank"是否应该是金融机构或河岸。这就是为什么敏锐的人眼睛是你对抗这些微妙但关键错误的最佳防线。
何时引入母语使用者
让我们现实一点。如果你刚刚翻译了一份文档以供你自己的内部研究,你自己的审查可能就足够了。
但如果赌注很高——想象商业提案、法律合同、已发布的材料或面向客户的网站内容——让母语英语使用者进行最后的审查是你能做的最聪明的投资之一。
他们会捕捉你可能错过的尴尬措辞和细微错误,确保文本自然流动。这一步是区分仅仅是"翻译"的文档和真正专业且准备好留下正确印象的文档的区别。
关于翻译德文PDF的常见问题
通过步骤来将德文PDF转换为英文通常会提出一些实际问题,特别是如果你处理大型、复杂的文档或那些棘手的德文字符。提前解决这些问题可以为你节省大量的挫折。让我们解决人们遇到的一些最常见的障碍。
我能直接翻译扫描的PDF而不需要OCR吗?
简短的回答是否定的,你不能。把扫描的PDF看作一张页面的照片。你看到的单词只是像素的集合,而不是计算机可以读取和处理的实际文本字符。
为了使其工作,你绝对必须首先通过光学字符识别(OCR)工具运行它。OCR软件扫描图像,识别字母形