
Zastanawiałeś się kiedyś, jak ogromne książki są tłumaczone tak szybko, zachowując przy tym doskonałą spójność? To nie magia i nie jest to wyłącznie praca maszyny. Sekret leży w procesie zwanym Computer-Assisted Translation, czyli CAT.
To nie chodzi o zastąpienie wykwalifikowanego tłumacza człowieka sztuczną inteligencją. Myśl o tym raczej jako o potężnym partnerstwie. Narzędzia CAT to wyrafinowani asystenci, którzy zajmują się powtarzalnymi, opartymi na pamięci zadaniami, zwalniając eksperta człowieka do skupienia się na tym, co robi najlepiej: uchwyceniu niuansów, kontekstu kulturowego i subtelnej sztuki języka.
Zrozumienie Computer-Assisted Translation dla plików PDF

Wyobraź sobie mistrza kuchni z wysokotech sous chefem. Szef kuchni jest wciąż siłą kreatywną, smakiem, dostosowaniem i podejmowaniem każdej krytycznej decyzji. Ale sous chef bezbłędnie zajmuje się nudną pracą przygotowawczą – krojeniem, mierzeniem i doskonałym pamiętaniem każdego przepisu. Dokładnie tak działa CAT. To współpraca, a nie zautomatyzowana linia produkcyjna.
Oprogramowanie nie „myśli" za tłumacza ani nie podejmuje kreatywnych wyborów. Po prostu usprawnia przepływ pracy, zajmując się zadaniami, które ludzie uważają za wyczerpujące, ale komputery mogą wykonać w mgnieniu oka.
Główne komponenty oprogramowania CAT
Ten zespół człowieka i maszyny czerpie swoją moc z dwóch głównych funkcji, które są fundamentem każdego poważnego projektu tłumaczenia:
- Translation Memory (TM): To żywa baza danych, która zapisuje wszystko, nad czym pracował tłumacz – każde zdanie, zwrot i akapit. Następnym razem, gdy pojawi się podobne zdanie, TM natychmiast sugeruje poprzednie tłumaczenie. To oszczędza niewiarygodnie dużo czasu i utrzymuje konsekwencję języka od rozdziału pierwszego do załącznika.
- Terminology Databases (Termbases): Pomyśl o termbzie jako o niestandardowym słowniku dla Twojego konkretnego projektu. To lista krytycznych terminów, które muszą być tłumaczone w dokładnie taki sam sposób za każdym razem. W powieści fantasy mogą to być imiona postaci, zaklęcia magiczne lub fikcyjne lokalizacje. To narzędzie zapewniające spójność.
To potężne duo jest głównym powodem wzrostu branży. Rynek tłumaczenia maszynowego, który jest często zintegrowany z systemami CAT, był wyceniany na 153,8 miliona USD w 2020 roku i jest na dobrej drodze do osiągnięcia 230,67 miliona USD do 2026 roku. Wydajność to nazwa gry, szczególnie gdy masz do czynienia z ogromnymi liczbami słów w książkach.
Najważniejsza rzecz do zapamiętania to to, że CAT dotyczy wspomagania, a nie automatyzacji. Wzmacnia umiejętności człowieka, zwalniając tłumaczy do skupienia się na twórczym i kulturalnym dopracowaniu, które czyni tłumaczenie naprawdę świetnym.
Ale tutaj pojawia się haczyk, gdy wrzucisz plik PDF do mieszanki. Zanim ten niesamowity system będzie mógł pracować, oprogramowanie musi być w stanie przeczytać dokument. Plik PDF to często jak zdjęcie tekstu; możesz zobaczyć słowa, ale nie możesz ich łatwo chwycić do pracy.
Oznacza to, że istnieje kluczowy pierwszy krok, zanim jakakolwiek magia tłumaczenia będzie mogła się zdarzyć. Technologia stojąca za tym, która pozwala maszynom rozumieć język ludzki, jest fascynująca. Jeśli chcesz wiedzieć, jak to działa, możesz uzyskać świetny przegląd, badając Natural Language Processing (NLP).
Wyjątkowe wyzwanie tłumaczenia plików PDF
Dlaczego zatem tłumaczenie pliku PDF jest znacznie trudniejsze niż, powiedzmy, prosty dokument Word? Oto dobry sposób na myślenie o tym: plik PDF to jak fotografia strony książki. Możesz dobrze widzieć słowa i obrazy, ale nie możesz ich po prostu kliknąć i edytować, jak byś to zrobił w normalnym dokumencie tekstowym. Ten stały format jest sercem problemu.
Ten pojedynczy problem wprowadza ogromną zmieszanie do dowolnego przepływu pracy computer assisted translation PDF. Zanim narzędzie CAT będzie mogło nawet zacząć pracę z Translation Memory lub słownikami, potrzebuje czystego, edytowalnego tekstu. Plik PDF, z samej swojej natury, walczy z tobą na każdym kroku.
Natywne cyfrowo versus zeskanowane pliki PDF
Generalnie natkniesz się na dwa rodzaje plików PDF, a każdy niesie swój własny smak trudności. Ustalenie, z którym typem się masz do czynienia, to pierwszy krok.
- Natywne cyfrowo pliki PDF: To pliki utworzone bezpośrednio z programów takich jak Microsoft Word lub Adobe InDesign. Tekst jest technicznie tam, ale jest często zablokowany na miejscu. Próba jego wyciągnięcia może przypominać rozbijanie świnki skarbonki – pewnie wyciągniesz monety, ale zostaniesz z bałaganem rozbite formatowanie i złamane akapity.
- Zeskanowane pliki PDF: Te są jeszcze trudniejsze. Zeskanowany plik PDF to zasadniczo tylko obraz, co oznacza, że „tekst" to nic więcej niż wzór pikseli. Aby uczynić go czymś, co komputer może zrozumieć, musisz go przeprowadzić przez Optical Character Recognition (OCR), proces, który skanuje obraz i konwertuje te piksele z powrotem na tekst cyfrowy.
Ogromna część tłumaczenia PDF to po prostu walka z tymi zeskanowanymi dokumentami. Opanowanie sposobu czystego wyodrębniania tekstu to kluczowa umiejętność. Aby lepiej zrozumieć ten złożony proces, warto nauczyć się, jak tłumaczyć zeskanowane pliki PDF.
Typowe pułapki dla autorów
Bez odpowiednich narzędzi i procesu, autorzy próbujący tłumaczyć plik PDF często napotykają mur frustrujących, pochłaniających czas problemów, które niweczą ostateczną jakość ich książki. Aby uzyskać głębszy wgląd w poruszanie się wśród tych wyzwań, nasz przewodnik dotyczący sposobu tłumaczenia zeskanowanego pliku PDF to świetny zasób.
Fundamentalnym problemem pliku PDF jest to, że został zaprojektowany do przeglądania, a nie edycji. Jego całym celem jest zachowanie statycznego układu wizualnego na dowolnym urządzeniu, co jest dokładnym przeciwieństwem tego, czego potrzebuje przepływ pracy tłumaczenia: elastycznej, dostępnej zawartości.
Ten podstawowy konflikt prowadzi do wszystkich klasycznych bólów głowy:
- Rozbite formatowanie: Kiedy w końcu wyrwiesz tekst, te czyste kolumny i starannie zorganizowane akapity mogą zamienić się w chaotyczny bałagan.
- Nieeditowalnych grafiki: Każdy tekst, który jest częścią obrazu, na przykład na wykresie lub diagramie, pozostaje zablokowany. Jest niemożliwy do tłumaczenia bez poważnej edycji obrazu.
- Niedokładne wyodrębnianie tekstu: OCR to potężna technologia, ale nie jest doskonała. Może źle czytać znaki, wprowadzać literówki lub po prostu całkowicie zawieść na skanach niskiej jakości. Oznacza to, że ktoś musi żmudnie sprawdzić cały tekst zanim tłumaczenie będzie mogło się nawet zacząć.
Te problemy są dokładnie dlatego, dlaczego profesjonalne, oparte na narzędziach podejście to nie tylko miłe do posiadania; jest to niezbędne do uzyskania wysokiej jakości wyniku.
Twój przepływ pracy tłumaczenia PDF krok po kroku
Wskoczenie do projektu computer assisted translation PDF, szczególnie dla czegoś tak złożonego jak książka, może wydawać się przytłaczające. Ale kiedy rozbijasz to na jasny, metodyczny przepływ pracy, proces staje się znacznie bardziej zarządzalny. Ten plan działania przeprowadzi Cię przez całą podróż, od tego zablokowanego pliku PDF do doskonale przetłumaczonej, gotowej do publikacji książki.
Prawdziwa praca zaczyna się na długo przed tłumaczeniem pierwszego słowa. Pierwsza, i prawdopodobnie najważniejsza, faza dotyczy przygotowania. Myśl o tym jak o położeniu fundamentu domu – jeśli nie zrobisz tego poprawnie, wszystko, co na nim zbudujesz, będzie niestabilne. Celem tutaj jest wprowadzenie statycznego pliku PDF do formatu, który oprogramowanie tłumaczeniowe może faktycznie przeczytać.
Faza 1: Przygotowanie i wyodrębnianie tekstu
Twoim pierwszym zadaniem jest uwolnienie tekstu z sztywnej struktury pliku PDF. Sposób, w jaki to robisz, całkowicie zależy od tego, z jakim rodzajem pliku PDF masz do czynienia: takiego, który urodził się cyfrowo, czy takiego, który jest skanem dokumentu fizycznego.
Ścieżka, którą podążasz na samym początku, zmienia się w zależności od pochodzenia pliku PDF.
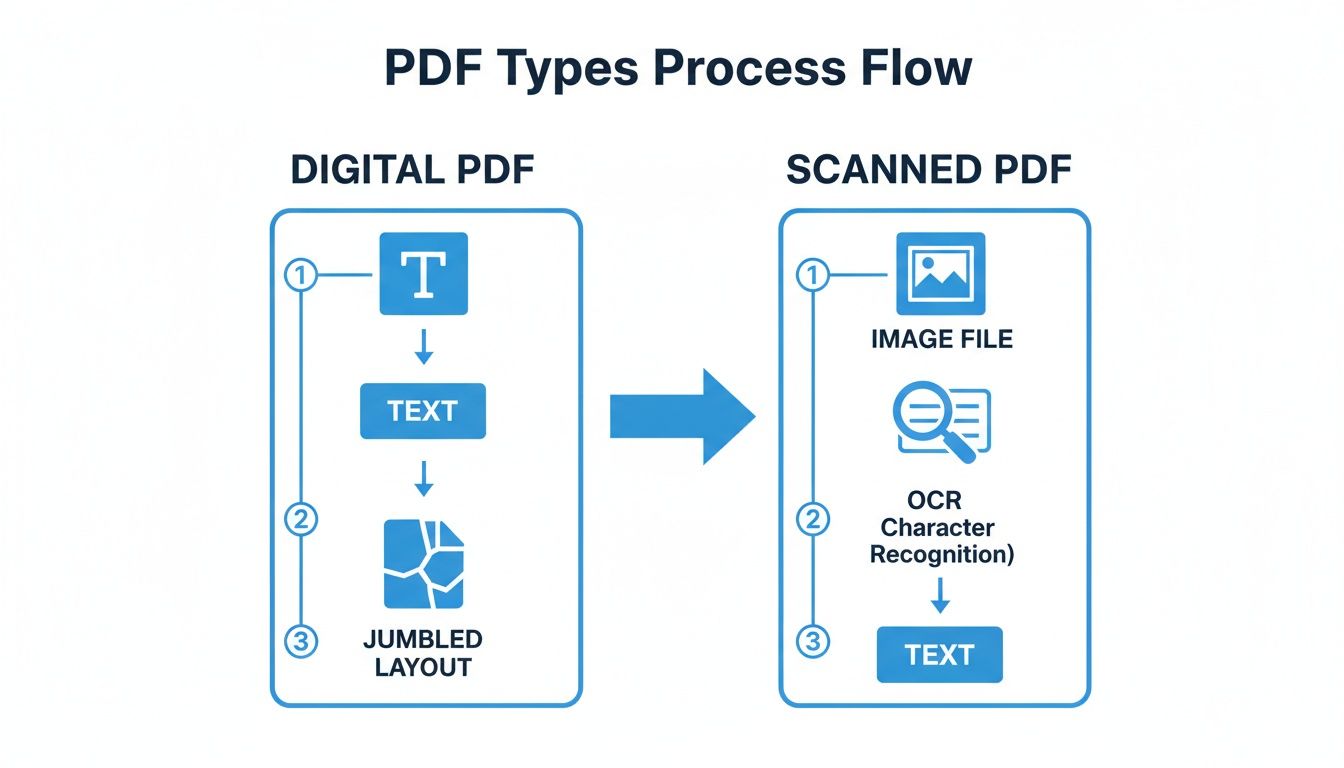
Jak widać, obie ścieżki prowadzą do wyodrębnionego tekstu, ale zeskanowany plik PDF dodaje niebezpieczny dodatkowy krok: OCR.
W przypadku zeskanowanych książek oznacza to uruchomienie stron przez oprogramowanie Optical Character Recognition (OCR). Ostrzeżenie: proces ten jest rzadko bezbłędny. Często wyrzuca błędy, takie jak źle czytane litery („l" zamiast „1") lub dziwnie połączone słowa. Dlatego dokładne oczyszczenie i korekta wyodrębnionego tekstu są absolutnie niezbędne, zanim cokolwiek innego zrobisz.
Aby dać Ci jaśniejszy obraz, oto zestawienie całego przepływu pracy od początku do końca.
Etapy przepływu pracy CAT do tłumaczenia plików PDF
Ta tabela przedstawia istotne etapy przepływu pracy computer-assisted translation dla pliku PDF, pokazując, co dzieje się na każdym etapie i jakie narzędzia są zaangażowane.
| Etap | Cel | Typowe narzędzia lub techniki |
|---|---|---|
| 1. Wyodrębnianie tekstu | Konwertuj plik PDF na edytowalny format tekstowy, który może przetwarzać narzędzie CAT. | Adobe Acrobat Pro, Abbyy FineReader (dla OCR), różne konwertery online. |
| 2. Import CAT | Zaimportuj czysty tekst do środowiska CAT i podziel go na segmenty. | Trados Studio, MemoQ, Phrase, Smartling. |
| 3. Tłumaczenie | Tłumacz tekst segment po segmencie, wykorzystując zasoby TM i Termbase. | Człowiek lingwista pracujący w edytorze narzędzia CAT. |
| 4. Zapewnienie jakości | Uruchom zautomatyzowane i ręczne kontrole, aby wychwycić niespójności, błędy i problemy z formatowaniem. | Wbudowane sprawdzanie QA w narzędziach CAT (np. Xbench), ręczna korekta. |
| 5. Układ (DTP) | Odtwórz oryginalny układ książki z przetłumaczonym tekstem i grafiką. | Adobe InDesign, QuarkXPress, Affinity Publisher. |
Każdy z tych etapów buduje się na poprzednim, zapewniając, że ostateczna przetłumaczona książka jest dokładna, spójna i profesjonalnie sformatowana.
Faza 2: Środowisko CAT i tłumaczenie
Mając czysty, edytowalny tekst gotowy do pracy, czas przejść do środowiska CAT. To jest miejsce, gdzie dzieje się magia, z potężnymi funkcjami oprogramowania pomagającymi zapewnić spójność i przyspieszenie pracy.
- Import i segmentacja: Zaczniesz od zaimportowania tekstu do narzędzia CAT. Oprogramowanie następnie automatycznie dzieli tekst na mniejsze fragmenty zwane segmentami, które są zwykle zdaniami lub zwrotami.
- Wykorzystanie zasobów: Gdy tłumacz pracuje przez każdy segment, narzędzie aktywnie sugeruje dopasowania z Translation Memory (TM). Jednocześnie Termbase (słownik Twojego projektu) oznacza kluczowe terminy, aby upewnić się, że są tłumaczone w ten sam sposób za każdym razem, gdy się pojawiają.
- Tłumaczenie i przegląd człowieka: To jest miejsce, gdzie przejmuje człowiek-ekspert. Profesjonalny tłumacz zaakceptuje, odrzuci lub zmieni sugestie oprogramowania, używając swoich umiejętności lingwistycznych, aby uchwycić właściwy ton, niuanse kulturowe i precyzyjne znaczenie. Ten krok to to, co odróżnia wysokiej jakości tłumaczenie od niezdarnego, wygenerowanego maszynowo.
Wpływ sztucznej inteligencji w tej przestrzeni jest niemożliwy do zignorowania. Rynek tłumaczenia języka AI eksplodował z 1,88 miliarda USD w 2023 roku do 2,34 miliarda USD w 2024 roku, wyraźny znak ogromnego popytu na te narzędzia. Zmienia to również sposób, w jaki pracują profesjonaliści, przy czym 70% europejskich specjalistów ds. języka teraz używa tłumaczenia maszynowego jako część swojego codziennego przepływu pracy. Możesz dowiedzieć się więcej o wzroście sztucznej inteligencji w tłumaczeniu na sonix.ai.
Środowisko CAT to serce przepływu pracy. To miejsce, gdzie technologia i człowiecza wiedza się łączą, wykorzystując zapisaną wiedzę (TM i słowniki) do budowania spójnej, wysokiej jakości warstwy tłumaczenia krok po kroku.
Faza 3: Zapewnienie jakości i ostateczny układ
Kiedy każde zdanie zostało przetłumaczone, fokus przesuwuje się na polerowanie i prezentację. To jest ostatnia prosta.
Najpierw uruchomisz serię zautomatyzowanych kontroli Quality Assurance (QA). Te narzędzia są zaprojektowane do wyszukiwania rodzajów błędów, które ludzkie oko może łatwo przeoczyć, takich jak niespójna terminologia, błędy formatowania liczb lub dodatkowe spacje. Pomyśl o tym jako cyfrowej sieci bezpieczeństwa.
Wreszcie, przetłumaczony tekst jest przekazywany do etapu Desktop Publishing (DTP). Tutaj profesjonalny projektant otwiera program taki jak Adobe InDesign i żmudnie odbudowuje oryginalny układ Twojej książki. Ponownie wstawia obrazy, formatuje nowy tekst, aby się zmieścił, i upewnia się, że ostateczna przetłumaczona książka jest doskonałym wizualnym dopasowaniem do oryginału. To żmudny, ale absolutnie krytyczny ostatni krok.
Niezbędne narzędzia do Computer Assisted PDF Translation

Aby pomyślnie przetłumaczyć plik PDF przy użyciu metod wspomaganego komputerem, potrzebujesz więcej niż jednego oprogramowania. Chodzi o zgromadzenie wyspecjalizowanego cyfrowego zestawu narzędzi. Każde narzędzie ma bardzo specyficzne zadanie: ostrożnie wyciągnąć tekst z pliku PDF, pomóc Ci go przetłumaczyć, a następnie włożyć wszystko z powrotem w nowy język, sprawiając, że wygląda dokładnie jak oryginał.
Myśl o tym jak o trzystopniowej pracowni dla Twojej książki. Najpierw musisz ostrożnie zdemontować oryginał. Po drugie, odbudujesz komponenty rdzenia – same słowa – w języku docelowym. Wreszcie, zajmujesz się ostatecznym montażem i ostatnimi szlifami. Każdy etap wymaga odpowiedniego narzędzia do pracy.
Odblokowywanie tekstu za pomocą konwerterów i OCR
Bardzo pierwszy krok jest często najtrudniejszy. Potrzebujesz sposobu na odblokowywanie tekstu z ustalonego, „płaskiego" formatu PDF. Do tłumaczenia całych książek, uzyskanie tego początkowego etapu jest absolutnie krytyczne.
Twoje główne narzędzia do tego to:
- Konwertery PDF: Jeśli Twój plik PDF został pierwotnie utworzony z programu takiego jak Word, dobry konwerter, taki jak Adobe Acrobat Pro, może często wyeksportować go z powrotem do edytowalnego formatu czyszczenia. To zawsze najlepszy scenariusz.
- Oprogramowanie OCR: W przypadku zeskanowanych książek lub plików PDF, które są zasadniczo tylko obrazami tekstu, potrzebujesz Optical Character Recognition (OCR). Potężne narzędzie, takie jak ABBYY FineReader, jest zaprojektowane do „czytania" obrazu każdej strony i konwersji kształtów liter z powrotem na rzeczywisty, edytowalny tekst.
Bez jednego z tych narzędzi Twój plik PDF jest zamkniętą skrzynią. To są strażnicy Twojej zawartości, czyniący ją dostępną dla narzędzi tłumaczeniowych, które następują.
Silnik tłumaczeniowy: narzędzia CAT
Kiedy tekst jest wolny, przechodzi do serca operacji: narzędzia CAT. To jest miejsce, gdzie umiejętności tłumacza spotykają się z potężnym oprogramowaniem, aby wytworzyć dokładne i, co najważniejsze, spójne tłumaczenie.
Profesjonalne narzędzia CAT, takie jak Trados Studio lub memoQ, są zbudowane wokół dwóch funkcji, które są absolutnie niezbędne dla projektów o długości książki. Ich całym celem jest zapewnienie spójności od strony pierwszej do ostatniego rozdziału.
Translation Memory (TM): Pomyśl o tym jako o osobistej pamięci projektu. Zapisuje każde zdanie, które tłumaczysz. Kiedy to samo zdanie – lub bardzo podobne – pojawia się ponownie, TM natychmiast sugeruje poprzednie tłumaczenie.
Terminology Management (Termbase): To niestandardowy słownik dla Twojej książki. Zapewnia, że kluczowe terminy, takie jak imiona postaci, miejsca lub unikalne koncepcje, są zawsze tłumaczone dokładnie w ten sam sposób za każdym razem, gdy się pojawiają.
To oprogramowanie staje się centralne dla globalnej komunikacji. Rynek oprogramowania do tłumaczenia języków, wyceniany na 10,72 miliarda USD w 2024 roku, ma wzrosnąć do 18,26 miliarda USD do 2033 roku, przy czym tłumaczenie dokumentów jest jego największym elementem. Ten wzrost po prostu pokazuje, jak ważne stały się te narzędzia. Możesz przeczytać więcej o tych trendach rynkowych na researchnester.com.
Odbudowanie wizualizacji za pomocą oprogramowania DTP
Po zakończeniu tłumaczenia zostaje Ci blok zwykłego tekstu. Ostateczny, krytyczny krok to wprowadzenie tego tekstu z powrotem do oryginalnego układu książki, wraz z obrazami i profesjonalnym formatowaniem. To zadanie oprogramowania Desktop Publishing (DTP).
Standardowe programy branżowe, takie jak Adobe InDesign, są używane do tej fazy. Wykwalifikowany projektant bierze przetłumaczony tekst i żmudnie umieszcza go z powrotem w układzie, ponownie wstawia obrazy, dostosowuje odstępy, aby uwzględnić rozszerzenie tekstu, i upewnia się, że gotowa książka jest doskonałym lustrem oryginału. To proces praktyczny, który wymaga oka projektanta, a nie zautomatyzowanego kroku. Nasz przewodnik dotyczący oprogramowania do tłumaczenia dokumentów zagłębia się głębiej w tego rodzaju narzędzia.
Najlepsze praktyki tłumaczenia Twojej książki PDF
Prawidłowe wykonanie tłumaczenia książki, szczególnie gdy zaczynasz od pliku PDF, zależy od strategii. Jeśli wskoczysz bez planu, możesz łatwo skończyć z frustrującym, drogim bałaganem. Ale postępując zgodnie z kilkoma sprawdzonymi najlepszymi praktykami, możesz gładko nawigować procesem i uzyskać wynik, który oddaje sprawiedliwość Twojej oryginalnej pracy.
Pierwsza, i zdecydowanie najważniejsza, zasada to ta: zawsze najpierw szukaj oryginalnego pliku źródłowego. Zanim pomyślisz o zajęciu się plikiem PDF, zrób wszystko, co możesz, aby znaleźć plik, z którego został utworzony, czy to projekt Adobe InDesign, dokument Microsoft Word, czy coś podobnego. Ten jeden krok może zaoszczędzić Ci świata bólu, omijając trudny i czasochłonny proces wyodrębniania tekstu i odbudowy układu od zera.
Oceń swój punkt wyjścia
Okej, więc próbowałeś wszystkiego i plik PDF to wszystko, co masz. Co teraz? Twoim następnym krokiem jest ustalenie dokładnie, z jakim rodzajem pliku PDF masz do czynienia. Czysty, cyfrowo utworzony plik PDF to całkowicie inny zwierz niż niewyraźny, zeskanowany.
Szybkim sposobem na przetestowanie tego jest otwarcie dokumentu i spróbowanie wyróżnienia tekstu kursorem. Jeśli możesz wybrać poszczególne słowa i zdania, jesteś w dobrej formie. Oznacza to, że tekst jest „żywy" i może być prawdopodobnie wyodrębniony czyszczenia.
Jeśli nie możesz wybrać nic, masz do czynienia z plikiem PDF opartym na obrazach, co oznacza, że zmierzasz do kroku OCR. Sukces tego procesu zależy całkowicie od jakości skanowania.
- Sprawdź przejrzystość i rozdzielczość: Czy litery są ostre i wyraźne, czy wyglądają trochę rozmycie? Skanowanie o wysokiej rozdzielczości daje oprogramowaniu OCR znacznie lepszą szansę na prawidłowe wykonanie.
- Poszukaj złożonych układów: Bądź czujny na trudne formatowanie. Takie rzeczy jak wiele kolumn, tekst zawijający się wokół obrazów i wiele tabel mogą łatwo zmylić narzędzia do wyodrębniania.