
想知道大部分书籍是如何快速翻译并保持完美一致性的吗?这不是魔法,也不是纯粹由机器完成的工作。秘密在于一个称为计算机辅助翻译或CAT的过程。
这不是用人工智能替代熟练的人类翻译。可以把它看作是一种强大的合作关系。CAT工具是复杂的助手,处理重复的、基于记忆的任务,让人类专家可以专注于他们最擅长的事情:捕捉细微差别、文化背景和语言的微妙艺术。
了解PDF的计算机辅助翻译

想象一位大厨与一位高科技的副主厨。主厨仍然是创意的驱动力,品尝、调整并做出每一个关键决定。但副主厨完美地处理繁琐的准备工作——切割、测量和完美记住每个食谱。这正是CAT的工作方式。这是一种合作,而不是自动化的工厂流水线。
该软件不会为翻译"思考"或做出创意选择。它只是通过处理人类觉得疲劳但计算机可以快速完成的任务来简化工作流程。
CAT软件的核心组件
这个人机团队从两个主要功能中获得力量,这两个功能是任何严肃翻译项目的基础:
- 翻译记忆库(TM):这是一个活动数据库,保存翻译人员所做过的一切工作——每个句子、短语和段落。下一次出现类似的句子时,TM会立即建议之前的翻译。这节省了大量时间,并保持了从第一章到附录的语言一致性。
- 术语数据库(术语库):将术语库看作是特定项目的自定义词汇表。这是一个关键术语列表,必须始终以相同的方式翻译。对于奇幻小说,这可能包括人物名称、魔法咒语或虚构地点。这是确保一致性的工具。
这个强大的组合是该行业增长的主要原因。机器翻译市场(通常集成在CAT系统中)在2020年的价值为1.538亿美元,预计到2026年将达到2.3067亿美元。效率是关键,特别是当你处理大量文字内容的书籍时。
最重要的是要记住CAT是关于增强,而不是自动化。它增强了人类的技能,让翻译人员可以专注于创意和文化的微调,这是使翻译真正优秀的原因。
但这里有个问题,当你涉及PDF时。在这个神奇的系统能够工作之前,软件必须能够读取文档。PDF通常就像文本的图片;你可以看到文字,但你不能轻易地抓住它们来使用。
这意味着在任何翻译魔法发生之前,有一个关键的第一步。使机器能够理解人类语言的技术是令人着迷的。如果你对它如何工作感到好奇,你可以通过探索自然语言处理(NLP)来获得很好的概述。
翻译PDF文件的独特挑战
那么,为什么翻译PDF比简单的Word文档要困难得多呢?这里有个很好的思考方式:PDF就像书页的照片。你可以很好地看到文字和图像,但你不能像在普通文本文档中那样点击并编辑它们。这种固定的格式是问题的核心。
这个单一的问题给任何计算机辅助翻译PDF工作流程造成了巨大的障碍。在CAT工具甚至能开始使用翻译记忆库或词汇表之前,它需要干净、可编辑的文本。PDF从本质上讲,在每一步都与你对抗。
数字原生版本与扫描PDF
你通常会遇到两种类型的PDF,每一种都给这个表格带来了自己的难度。弄清楚你在处理哪种类型是第一步。
- 数字原生PDF:这些是直接从Microsoft Word或Adobe InDesign等程序创建的文件。文本技术上是存在的,但它通常被锁定在原位。试图将其拉出来就像砸猪罐——当然,你会得到硬币,但你会留下一堆破碎的格式和断裂的段落。
- 扫描PDF:这些更困难。扫描PDF本质上只是一个图像,这意味着"文本"只不过是像素的模式。要使其成为计算机能理解的东西,你必须通过光学字符识别(OCR)来运行它,这是一个扫描图像并将这些像素转换回数字文本的过程。
PDF翻译的很大一部分就是与这些扫描文档搏斗。掌握如何干净地提取文本是一项关键技能。要更好地理解这个复杂的过程,值得学习如何翻译扫描PDF文件。
作者常见的陷阱
没有正确的工具和流程,试图翻译PDF的作者经常会遇到一堵令人沮丧、耗时的问题之墙,这会破坏他们书籍的最终质量。要更深入地了解如何应对这些挑战,我们关于如何翻译扫描PDF的指南是一个很好的资源。
PDF的根本问题是它是为查看而设计的,而不是为编辑。它的整个目的是在任何设备上保留静态的视觉布局,这正好与翻译工作流程所需的相反:灵活的、可访问的内容。
这种基本的冲突导致了所有经典的麻烦:
- 格式破碎:当你最终把文本撕出来时,那些干净的栏和整齐组织的段落可能会变成混乱的混乱。
- 不可编辑的图形:作为图像一部分的任何文本,比如在图表或图表中,都会被锁定。没有一些严肃的图像编辑,它是无法翻译的。
- 不准确的文本提取:OCR是一项强大的技术,但它并不完美。它可能会误读字符、引入打字错误,或在低质量扫描上完全失败。这意味着在翻译甚至能够开始之前,必须有人痛苦地逐字逐句地校对整个文本。
这些问题正是为什么专业的、工具驱动的方法不仅仅是一个不错的选择;它对获得高质量的结果是必不可少的。
你的PDF翻译工作流程逐步指南
跳入计算机辅助翻译PDF项目,特别是对于像书籍这样复杂的东西,可能会感到不知所措。但当你将其分解为清晰、有条不紊的工作流程时,该过程变得更加易于管理。这个路线图将引导你完成整个旅程,从那个被锁定的PDF到完美翻译、准备发布的书籍。
真正的工作在翻译第一个单词之前就开始了。第一个,也许是最重要的阶段,完全是关于准备。把它想象成为房子奠定基础——如果你在这部分做得不对,你在它上面建造的一切都会不稳定。这里的目标是将你的静态PDF转换成翻译软件实际上能读的格式。
第1阶段:准备和文本提取
你的第一项工作是从PDF的严格结构中解放文本。你如何做这完全取决于你处理的是什么样的PDF:一个出生于数字的,还是一个物理文档的扫描。
你在最开始采取的路径根据PDF的来源而改变。
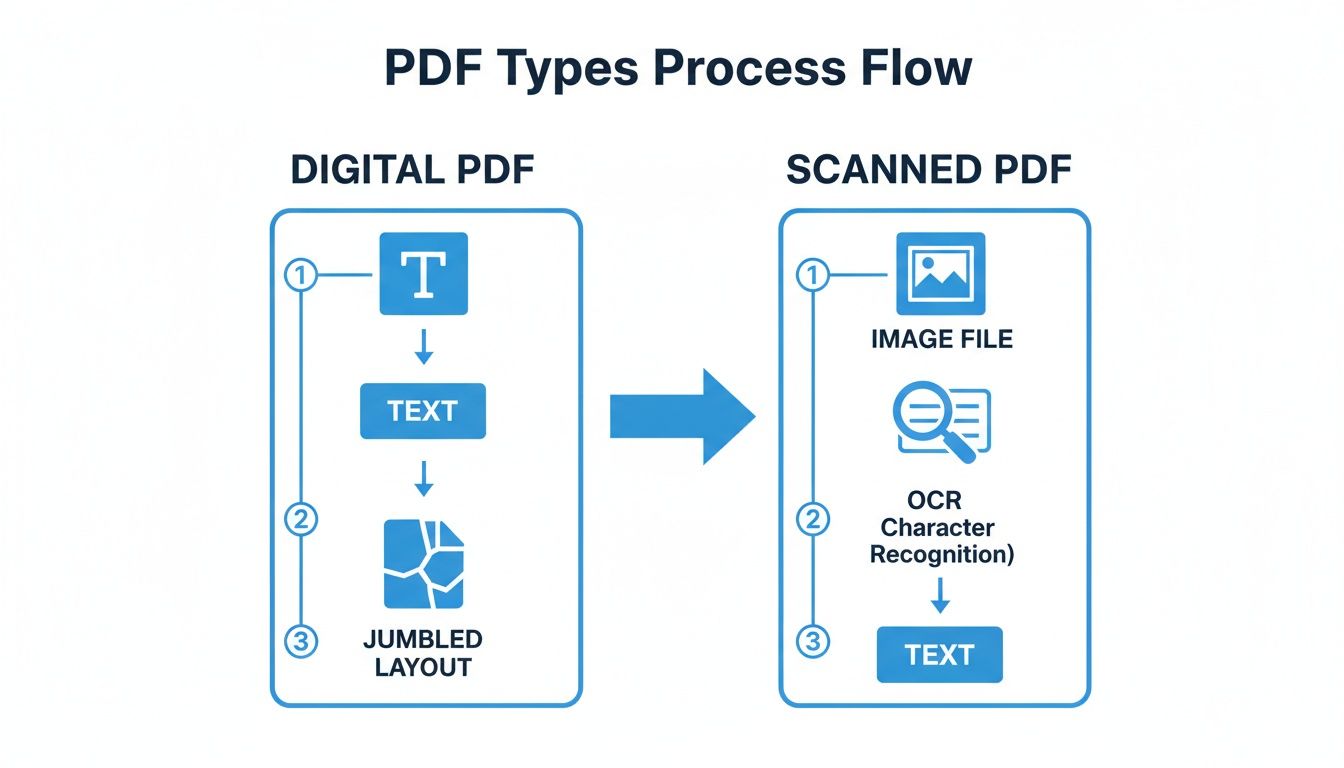
正如你所看到的,两条路径都导致提取的文本,但扫描PDF添加了一个棘手的额外步骤:OCR。
对于扫描的书籍,这意味着通过光学字符识别(OCR)软件运行页面。请注意:这个过程很少是完美的。它经常吐出错误,比如误读的字母("l"代替"1")或奇怪的合并词。这就是为什么在做任何其他事情之前,对提取的文本进行细致的清理和校对是绝对必要的。
为了给你一个更清晰的图片,这是从开始到结束的整个工作流程的分解。
PDF翻译的CAT工作流程阶段
这个表格概述了PDF文件的计算机辅助翻译工作流程中的基本阶段,显示了每个步骤发生的事情和涉及的工具。
| 阶段 | 目标 | 常见工具或技术 |
|---|---|---|
| 1. 文本提取 | 将PDF转换为CAT工具可以处理的可编辑文本格式。 | Adobe Acrobat Pro、Abbyy FineReader(用于OCR)、各种在线转换器。 |
| 2. CAT导入 | 将干净的文本导入CAT环境并将其分解为片段。 | Trados Studio、MemoQ、Phrase、Smartling。 |
| 3. 翻译 | 逐段翻译文本,利用TM和术语库资产。 | 在CAT工具编辑器中工作的人类语言学家。 |
| 4. 质量保证 | 运行自动和手动检查以捕捉不一致、错误和格式问题。 | CAT工具中的内置QA检查器(例如Xbench)、手动校对。 |
| 5. 布局(DTP) | 用翻译的文本和图形重新创建原始书籍布局。 | Adobe InDesign、QuarkXPress、Affinity Publisher。 |
这些阶段中的每一个都建立在最后一个之上,确保最终的翻译书籍是准确的、一致的和专业格式化的。
第2阶段:CAT环境和翻译
准备好干净、可编辑的文本后,是时候进入CAT环境了。这是魔法发生的地方,强大的软件功能帮助确保一致性并加快工作。
- 导入和分段:你将从将文本导入CAT工具开始。软件然后自动将文本分割成称为片段的较小块,通常是句子或短语。
- 利用资产:当翻译人员逐段工作时,该工具积极建议来自翻译记忆库(TM)的匹配。同时,术语库(你的项目词汇表)标记关键术语以确保它们每次出现时都以相同的方式翻译。
- 人类翻译和审查:这是人类专家接管的地方。专业翻译人员将接受、拒绝或调整软件的建议,使用他们的语言技能来捕捉正确的语气、文化细微差别和精确的含义。这一步是将高质量翻译与笨拙的机器生成翻译区分开来的原因。
人工智能在这个领域的影响是不可能忽视的。AI语言翻译市场从2023年的18.8亿美元爆炸式增长到2024年的23.4亿美元,这清楚地表明了这些工具的巨大需求。它也在改变专业人士的工作方式,70%的欧洲语言专业人士现在在他们的日常工作流程中使用机器翻译。你可以在sonix.ai上了解更多关于AI在翻译中的崛起。
CAT环境是工作流程的核心。这是技术和人类专业知识融合的地方,使用存储的知识(TM和词汇表)来逐层建立一个一致的、高质量的翻译层。
第3阶段:质量保证和最终布局
一旦每个句子都被翻译,焦点就转向抛光和呈现。这是最后的冲刺。
首先,你将运行一系列自动质量保证(QA)检查。这些工具旨在追捕人眼容易忽略的那种错误,比如术语不一致、数字格式错误或多余的空格。把它看作是一个数字安全网。
最后,翻译的文本被移交给桌面出版(DTP)阶段。在这里,专业设计师打开Adobe InDesign等程序,精心重建你书籍的原始布局。他们重新插入图像、格式化新文本以适应,并确保最终翻译的书籍在视觉上完全匹配原始书籍。这是一个费力但绝对关键的最后一步。
计算机辅助PDF翻译的必要工具

要使用计算机辅助方法成功翻译PDF,你需要的不仅仅是一个软件。这是关于组装一个专门的数字工具箱。每个工具都有一个非常具体的工作:小心地从PDF中拉出文本,帮助你翻译它,然后将所有东西放回一种新语言的布局中,使其看起来就像原始的一样。
把它想象成你书籍的三阶段车间。首先,你必须小心地拆卸原始的。其次,你用目标语言重建核心组件——单词本身。最后,你处理最终的组装和完成的触摸。每个阶段都需要适合工作的正确工具。
用转换器和OCR解锁文本
第一步通常是最棘手的。你需要一种方法来从固定的、"平面"的PDF格式中解锁文本。对于翻译整本书籍,正确处理这个初始阶段是绝对关键的。
你在这方面的主要工具是:
- PDF转换器:如果你的PDF最初是从Word等程序创建的,一个好的转换器如Adobe Acrobat Pro通常可以将其干净地导出回可编辑的格式。这总是最好的情况。
- OCR软件:对于扫描的书籍或本质上只是文本图像的PDF,你需要光学字符识别(OCR)。一个强大的工具如ABBYY FineReader旨在"读取"每页的图像并将字母的形状转换回实际的、可编辑的文本。
没有这些工具之一,你的PDF是一个上锁的盒子。它们是你内容的守门人,使其可以被接下来的翻译工具访问。
翻译引擎:CAT工具
一旦文本释放,它就转向操作的心脏:CAT工具。这是翻译人员的技能与强大的软件相遇以产生准确和最重要的一致翻译的地方。
专业的CAT工具如Trados Studio或memoQ围绕两个功能构建,这两个功能对书籍长度的项目绝对必要。他们的整个目的是确保从第一页到最后一章的一致性。
翻译记忆库(TM):把这看作是你项目的个人记忆。它保存你翻译的每个句子。当相同的句子——或非常相似的句子——再次出现时,TM会立即建议之前的翻译。
术语管理(术语库):这是你书籍的自定义词汇表。它确保关键术语,如人物名称、地点或独特的概念,总是以完全相同的方式翻译,每次它们出现。
这个软件正在成为全球交流的中心。语言翻译软件市场在2024年的价值为107.2亿美元,预计到2033年将增长至182.6亿美元,文件翻译是其最大的部分。这种增长只是表明这些工具已经变得多么至关重要。你可以在researchnester.com上阅读更多关于这些市场趋势。
用DTP软件重建视觉效果
翻译完成后,你留下一块纯文本。最后的关键步骤是将该文本恢复到书籍的原始布局中,完整的图像和专业格式。这是桌面出版(DTP)软件的工作。
行业标准程序如Adobe InDesign用于这个阶段。一位熟练的设计师拿着翻译的文本并精心将其放回布局中,重新插入图像、调整间距以适应文本扩展,并确保最终的书籍是原始的完美镜像。这是一个需要设计师眼光的动手过程,而不是自动化步骤。我们关于文件翻译软件的指南更深入地探讨了这些类型的工具。
翻译你的PDF书籍的最佳实践
正确翻译一本书,特别是当你从PDF开始时,完全是关于策略。如果你没有计划就跳进去,你很容易最终得到一个令人沮丧、昂贵的混乱。但通过遵循一些经过证实的最佳实践,你可以顺利地浏览这个过程,并获得一个对你的原始工作公正的结果。
第一个,也许是最重要的规则是这样的:总是首先寻找原始源文件。在你甚至考虑处理PDF之前,尽一切努力找到它是从什么文件创建的,无论是Adobe InDesign项目、Microsoft Word文档还是其他类似的东西。这一个步骤可以为你节省大量麻烦,绕过从头开始提取文本和重建布局的棘手且耗时的过程。
评估你的起点
好的,所以你已经尽力了,PDF是你仅有的。现在呢?你的下一步是弄清楚你处理的确切是什么样的PDF。一个干净的、数字创建的PDF是一个完全不同的东西,比一个模糊的、扫描的。
一个快速的测试方法是打开文档并尝试用光标突出显示文本。如果你可以选择单个单词和句子,你处于良好的状态。这意味着文本是"活动的",可能可以干净地提取。
如果你不能选择任何东西,你手上有一个基于图像的PDF,这意味着你正在走向OCR步骤。该过程的成功完全取决于扫描的质量。
- 检查清晰度和分辨率:字母是清晰锐利的,还是看起来有点模糊?高分辨率扫描给OCR软件一个更好的机会来正确处理事情。
- 寻找复杂的布局:注意棘手的格式。多个栏、环绕图像的文本和许多表格等事情可以轻易地混淆提取工具。
- 识别手写笔记:OCR技术在读取手写方面臭名昭著。任何涂鸦笔记或标记几乎肯定需要手动转录。
为一致性做准备并规划设计
在翻译一个单词之前,你需要考虑一致性。这是词汇表或术语库的地方。这只是一个你书籍的关键术语列表——想想人物名称、独特的概念或品牌短语——以及他们预先批准的翻译。将这个交给你的翻译人员对于在所有400多页中保持一致性是至关重要的,这是专业工作最大的标志之一。
一个常见的陷阱是认为一旦翻译完成,工作就完成了。实际上,那只是战斗的一半。重建书籍的设计和布局是一个单独的、通常同样密集的任务。
最后,不要忘记为称为桌面出版(DTP)的东西预算时间和资源。语言很少占用相同的空间。比如从英文翻译到德文,通常可以长达30%。专业设计师将需要返回,调整布局以适应新文本,重新插入所有图形,并确保最终书籍看起来与原始书籍一样精美。从第一天开始规划DTP可以让你避免沿途的讨厌的惊喜,并确保你的翻译书籍是你可以为之骄傲的东西。
为什么EPUB是书籍翻译的更聪明的选择
在与棘手、通常令人沮丧的计算机辅助翻译PDF工作流程搏斗后,很明显必然有一个更好的方式。幸运的是,有。解决方案是从一开始就使用EPUB文件,这避免了我们刚才涵盖的几乎所有痛苦的手动步骤。
这样想:PDF基本上是页面的数字照片。文本被压平进图像中,使得提取或改变它成为真正的麻烦。另一方面,EPUB更像一个动态的Word文档。它是为了灵活而构建的,允许文本和图像重新流动并适应任何屏幕——或任何语言。
这种内置的适应性对作者和翻译人员来说是一个巨大的胜利。当你使用EPUB时,你可以忘记笨拙的文本提取或混乱的OCR转换。你书籍的整个结构——每一章、每一个标题——已经完美地保存了。