
Undrat du någonsin hur massiva böcker översätts så snabbt samtidigt som perfekt konsekvens bibehålls? Det är inte magi, och det är inte helt och hållet en maskin som gör jobbet. Hemligheten ligger i en process som kallas datorstödd översättning, eller CAT.
Det här handlar inte om att ersätta en skicklig mänsklig översättare med AI. Tänk på det mer som ett kraftfullt partnerskap. CAT-verktyg är sofistikerade assistenter som hanterar repetitiva, minnesbaserade uppgifter, vilket befrias den mänskliga experten att fokusera på det de gör bäst: att fånga nyanser, kulturell kontext och språkets subtila konst.
Förstå datorstödd översättning för PDF-filer

Föreställ dig en mästerkock med en högteknologisk sous chef. Huvudkocken är fortfarande den kreativa kraften, som smakar, justerar och fattar varje kritiskt beslut. Men sous chefen hanterar utan fel det tråkiga förberedelsesarbetet – huggning, mätning och att komma ihåg varje recept perfekt. Det är precis hur CAT fungerar. Det är ett samarbete, inte en automatiserad fabrikslinje.
Programvaran "tänker" inte för översättaren eller gör kreativa val. Det strömlinjeformar bara arbetsflödet genom att ta hand om uppgifter som människor tycker är uttömmande men datorer kan göra på ett ögonblick.
CAT-programvarans kärnkomponenter
Detta mänsklig-och-maskin-lag får sin kraft från två huvudsakliga funktioner som är grunden för varje seriöst översättningsprojekt:
- Översättningsminne (TM): Det här är en levande databas som sparar allt en översättare någonsin har arbetat med – varje mening, fras och stycke. Nästa gång en liknande mening dyker upp föreslår TM omedelbar den tidigare översättningen. Detta sparar en otrolig mängd tid och håller språket konsekvent från kapitel ett till bilagan.
- Terminologidatabaser (Termbase): Tänk på en termbase som en anpassad ordlista för ditt specifika projekt. Det är en lista över kritiska termer som måste översättas på exakt samma sätt varje enda gång. För en fantasyroman kan detta inkludera karaktärsnamn, magiska trollformler eller fiktiva platser. Det är verktyget som säkerställer konsekvens.
Detta kraftfulla duo är en stor anledning till branschens tillväxt. Maskintranslationsmarknaden, som ofta är integrerad i CAT-system, värderades till USD 153,8 miljoner redan 2020 och är på väg att nå USD 230,67 miljoner år 2026. Effektivitet är spelet, särskilt när du hanterar de massiva ordräkningarna i böcker.
Det viktigaste att komma ihåg är att CAT handlar om förstärkning, inte automatisering. Det förbättrar mänsklig skicklighet, vilket befrias översättare att fokusera på den kreativa och kulturella finessen som gör en översättning verkligt bra.
Men här är fällan när du kastar en PDF i blandningen. Innan detta fantastiska system kan fungera måste programvaran kunna läsa dokumentet. En PDF är ofta som ett fotografi av text; du kan se orden, men du kan inte enkelt ta tag i dem för att arbeta med.
Det betyder att det finns ett avgörande första steg innan någon översättningsmagik kan hända. Teknologin bakom detta, som tillåter maskiner att förstå mänskligt språk, är fascinerande. Om du är nyfiken på hur det fungerar kan du få en bra överblick genom att utforska Natural Language Processing (NLP).
Den unika utmaningen med att översätta PDF-filer
Så, varför är det så mycket svårare att översätta en PDF än, säg, ett enkelt Word-dokument? Här är ett bra sätt att tänka på det: en PDF är som ett fotografi av en bokside. Du kan se orden och bilderna utmärkt, men du kan inte bara klicka och redigera dem som du skulle göra i ett normalt textdokument. Det fasta formatet är hjärtat av problemet.
Denna enda fråga kastar en stor skiftnyckel in i något datorstödd översättning PDF arbetsflöde. Innan ett CAT-verktyg ens kan börja göra sitt jobb med översättningsminne eller ordlistor behöver det ren, redigerbar text. En PDF, enligt sin mycket design, kämpar emot dig på varje steg.
Digitalt-ursprungliga kontra skannade PDF-filer
Du stöter vanligtvis på två typer av PDF-filer, och var och en för sin egen typ av svårighet till bordet. Att räkna ut vilken typ du har att göra med är det första steget.
- Digitalt-ursprungliga PDF-filer: Det här är filerna som skapas direkt från program som Microsoft Word eller Adobe InDesign. Texten är tekniskt där, men den är ofta låst på plats. Att försöka dra ut den kan kännas som att krossa en spargris – visst får du mynten ut, men du lämnas med ett röra av krossad formatering och brustna stycken.
- Skannade PDF-filer: Dessa är ännu tuffare. En skannad PDF är i princip bara en bild, vilket betyder att "texten" inte är mer än ett mönster av pixlar. För att göra det något en dator kan förstå måste du köra det genom optisk teckenigenkänning (OCR), en process som skannar bilden och konverterar dessa pixlar tillbaka till digital text.
En stor del av PDF-översättning är bara att kämpa med dessa skannade dokument. Att få kontroll på hur man extraherar texten rent är en kritisk färdighet. För att få en bättre känsla för denna komplexa process är det värt att lära sig hur man översätter skannade PDF-filer.
Vanliga fallgropar för författare
Utan rätt verktyg och process stöter författare som försöker översätta en PDF ofta på en vägg av frustrerade, tidskrävande problem som förstör den slutliga kvaliteten på deras bok. För en djupare titt på att navigera dessa utmaningar är vår guide om hur man översätter en skannad PDF en bra resurs.
Grundproblemet med en PDF är att den utformades för visning, inte redigering. Hela dess syfte är att bevara en statisk visuell layout på alla enheter, vilket är det exakta motsatsen till vad ett översättningsarbetsflöde behöver: flexibelt, tillgängligt innehål.
Denna grundläggande konflikt är vad som leder till alla klassiska huvudvärk:
- Krossad formatering: När du slutligen river ut texten kan dessa rena kolumner och snyggt organiserade stycken förvandlas till en kaotisk röra.
- Oredigerbar grafik: All text som är en del av en bild, som i ett diagram eller diagram, förblir låst. Det är oöversättbart utan någon seriös bildredigering.
- Felaktig textextraktion: OCR är en kraftfull teknik, men den är inte felfri. Det kan misstolka tecken, introducera stavfel eller bara misslyckas helt på låg kvalitet skanningar. Det betyder att någon måste noggrant korrekturläsa hela texten innan översättningen ens kan börja.
Dessa problem är exakt varför en professionell, verktygsdriven metod inte bara är en fin-att-ha; det är väsentligt för att få ett högkvalitativt resultat.
Ditt steg-för-steg PDF-översättningsarbetsflöde
Att hoppa in i ett datorstödd översättning PDF projekt, särskilt för något så komplext som en bok, kan kännas överväldigande. Men när du bryter ner det i ett tydligt, metodiskt arbetsflöde blir processen mycket mer hanterbar. Den här färdplanen kommer att vägleda dig genom hela resan, från den låsta PDF-filen till en perfekt översatt, redo-att-publicera bok.
Det verkliga arbetet börjar långt innan det första ordet översätts. Den första, och utan tvekan viktigaste, fasen handlar helt om förberedelse. Tänk på det som att lägga grunden för ett hus – om du inte får denna del rätt, kommer allt du bygger på det att vara instabilt. Målet här är att få din statiska PDF in i ett format som översättningsprogramvara faktiskt kan läsa.
Fas 1: Förberedelse och textextraktion
Ditt första jobb är att få texten fri från PDF:ens stela struktur. Hur du gör detta beror helt på vilken typ av PDF du hanterar: en som födddes digital eller en som är en skanning av ett fysiskt dokument.
Vägen du tar från början ändras baserat på PDF:ens ursprung.
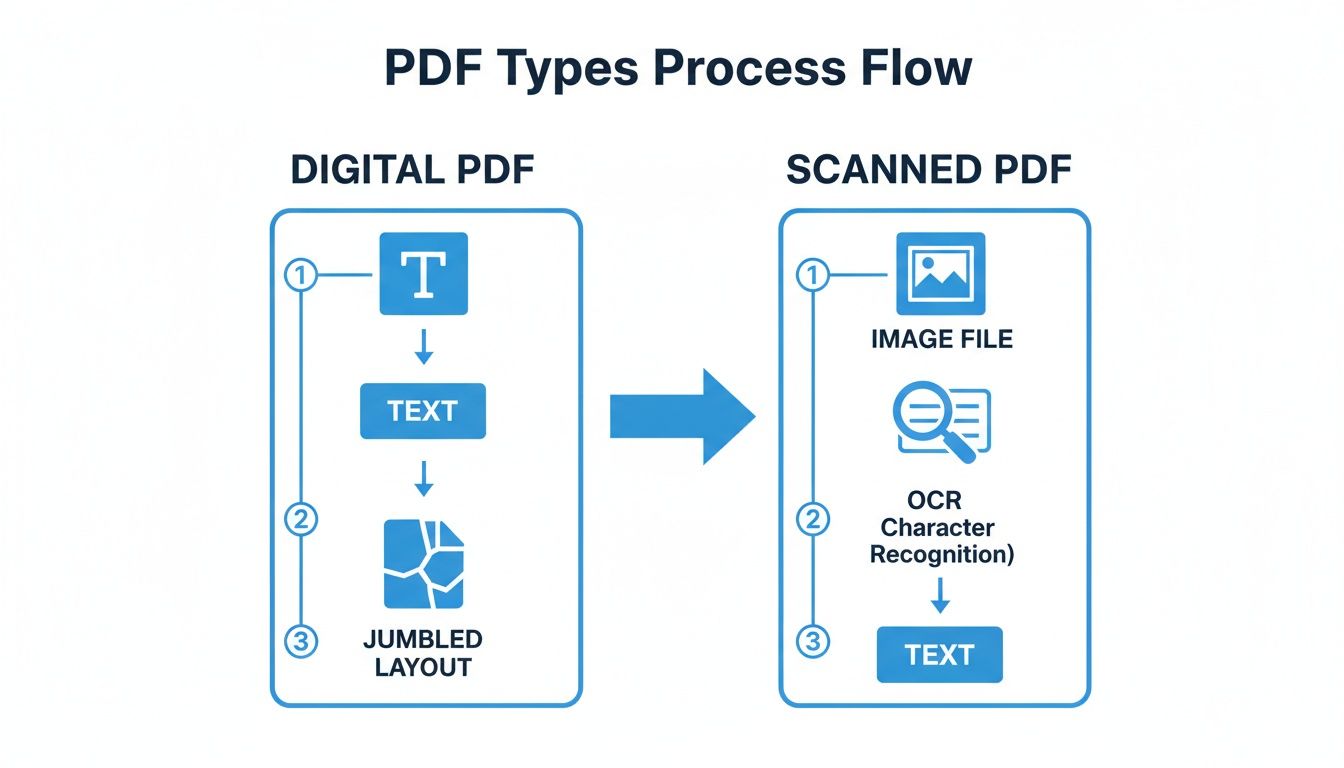
Som du kan se leder båda vägarna till extraherad text, men den skannade PDF-filen lägger till ett knepigt extra steg: OCR.
För skannade böcker betyder det att köra sidorna genom optisk teckenigenkänning (OCR) programvara. Varning: denna process är sällan felfri. Det spotterar ofta fel som misstolkade bokstäver ("l" istället för "1") eller konstigt sammanslagna ord. Det är därför en noggrann rengöring och korrekturläsning av den extraherade texten är absolut väsentlig innan du gör något annat.
För att ge dig en tydligare bild, här är en uppdelning av hela arbetsflödet från början till slut.
CAT arbetsflödesstadier för PDF-översättning
Denna tabell visar de väsentliga stadierna i ett datorstödd översättningsarbetsflöde för en PDF-fil, och visar vad som händer vid varje steg och de verktyg som är inblandade.
| Stadium | Mål | Vanliga verktyg eller tekniker |
|---|---|---|
| 1. Textextraktion | Konvertera PDF-filen till ett redigerbart textformat som ett CAT-verktyg kan bearbeta. | Adobe Acrobat Pro, Abbyy FineReader (för OCR), olika onlinekonverterare. |
| 2. CAT-import | Importera den rena texten till en CAT-miljö och dela upp den i segment. | Trados Studio, MemoQ, Phrase, Smartling. |
| 3. Översättning | Översätt texten segment-för-segment, med hjälp av TM och Termbase-tillgångar. | Mänsklig lingvist som arbetar inom CAT-verktygets editor. |
| 4. Kvalitetssäkring | Kör automatiserade och manuella kontroller för att fånga inkonsekvenser, fel och formateringsproblem. | Inbyggda QA-kontroller i CAT-verktyg (t.ex. Xbench), manuell korrekturläsning. |
| 5. Layout (DTP) | Återskapa den ursprungliga bokens layout med den översatta texten och grafiken. | Adobe InDesign, QuarkXPress, Affinity Publisher. |
Varje stadium bygger på det förra, vilket säkerställer att den slutliga översatta boken är korrekt, konsekvent och professionellt formaterad.
Fas 2: CAT-miljö och översättning
Med din rena, redigerbara text redo att gå är det dags att flytta in i CAT-miljön. Det här är där magin händer, med kraftfulla programvarufunktioner som hjälper till att säkerställa konsekvens och snabba upp arbetet.
- Import och segmentering: Du börjar med att importera texten till ditt CAT-verktyg. Programvaran karverar sedan automatiskt texten i mindre bitar kallade segment, som vanligtvis är meningar eller fraser.
- Att utnyttja tillgångar: När översättaren arbetar genom varje segment föreslår verktyget aktivt matchningar från översättningsminnet (TM). Samtidigt flaggar termbas (din projektordlista) nyckeltermer för att säkerställa att de översätts på samma sätt varje gång de dyker upp.
- Mänsklig översättning och granskning: Det här är där den mänskliga experten tar över. En professionell översättare kommer att acceptera, avvisa eller justera programvarans förslag, med hjälp av sina lingvistiska färdigheter för att fånga rätt ton, kulturella nyanser och exakt betydelse. Detta steg är det som skiljer en högkvalitativ översättning från en klumpig, maskinell.
Påverkan av AI i detta område är omöjlig att ignorera. Marknaden för AI-språköversättning exploderade från USD 1,88 miljarder år 2023 till USD 2,34 miljarder år 2024, ett tydligt tecken på den massiva efterfrågan på dessa verktyg. Det förändrar också hur professionella arbetar, med 70% av europeiska språkprofessionella som nu använder maskintranslation som en del av sitt dagliga arbetsflöde. Du kan läsa mer om ökningen av AI i översättning på sonix.ai.
CAT-miljön är hjärtat av arbetsflödet. Det är där teknik och mänsklig expertis sammansmälter, med lagrad kunskap (TM och ordlistor) för att bygga ett konsekvent, högkvalitativt översättningslager lager för lager.
Fas 3: Kvalitetssäkring och slutlig layout
När varje mening har översatts skiftar fokus till polering och presentation. Det här är mållinjen.
Först kör du en serie automatiserade kvalitetssäkringskontroller (QA). Dessa verktyg är utformade för att jaga den typ av misstag som ett mänskligt öga lätt kan missa, som inkonsekvent terminologi, nummerfelsformatering eller extra mellanslag. Tänk på det som ett digitalt säkerhetsnät.
Slutligen övergår den översatta texten till skrivbordspublicering (DTP) stadiet. Här öppnar en professionell designer ett program som Adobe InDesign och bygger noggrant om din boks ursprungliga layout. De infogar bilder igen, formaterar den nya texten för att passa och ser till att den slutliga översatta boken är en perfekt visuell matchning med originalet. Det är ett mödosamt men absolut kritiskt sista steg.
Väsentliga verktyg för datorstödd PDF-översättning

För att framgångsrikt översätta en PDF med datorstödd metod behöver du mer än bara en programvara. Det handlar om att samla en specialiserad digital verktygslåda. Varje verktyg har ett mycket specifikt jobb: att försiktigt dra texten ut ur PDF-filen, hjälpa dig att översätta den och sedan sätta allt tillbaka tillsammans på ett nytt språk, vilket gör det ser precis ut som originalet.
Tänk på det som en trefasverkstad för din bok. Först måste du försiktigt demontera originalet. För det andra bygger du om kärnkomponenterna – orden själva – på målspråket. Slutligen hanterar du slutmonteringen och de sista retoucherna. Varje stadium behöver rätt verktyg för jobbet.
Låsa upp texten med konverterare och OCR
Det första steget är ofta det knepigaste. Du behöver ett sätt att låsa upp texten från det fasta, "platta" PDF-formatet. För att översätta hela böcker är det att få detta initiala stadium rätt absolut kritiskt.
Dina huvudsakliga verktyg för detta är:
- PDF-konverterare: Om din PDF ursprungligen skapades från ett program som Word kan en bra konverterare som Adobe Acrobat Pro ofta exportera den tillbaka till ett redigerbart format rent. Det här är alltid det bästa scenariot.
- OCR-programvara: För skannade böcker eller PDF-filer som i princip bara är bilder av text behöver du optisk teckenigenkänning (OCR). Ett kraftfullt verktyg som ABBYY FineReader är utformat för att "läsa" bilden av varje sida och konvertera formerna på bokstäverna tillbaka till faktisk, redigerbar text.
Utan ett av dessa verktyg är din PDF en låst låda. De är väktarna till ditt innehål, vilket gör det tillgängligt för de översättningsverktyg som kommer härnäst.
Översättningsmotorn: CAT-verktyg
När texten är fri flyttas den till hjärtat av operationen: CAT-verktyget. Det här är där översättarens skicklighet möter kraftfull programvara för att producera en korrekt och, viktigast av allt, konsekvent översättning.
Professionella CAT-verktyg som Trados Studio eller memoQ är byggda omkring två funktioner som är absolut väsentliga för bokstora projekt. Deras hela syfte är att säkerställa konsekvens från sida ett till det slutliga kapitlet.
Översättningsminne (TM): Tänk på detta som ditt projekts personliga minne. Det sparar varje mening du översätter. När samma mening – eller en mycket likartad – dyker upp igen föreslår TM omedelbar den tidigare översättningen.
Terminologihantering (Termbase): Det här är en anpassad ordlista för din bok. Det säkerställer att nyckeltermer, som karaktärsnamn, platser eller unika begrepp, alltid översätts på exakt samma sätt varje gång de dyker upp.
Denna programvara blir central för global kommunikation. Marknaden för språköversättningsprogramvara, värderad till USD 10,72 miljarder år 2024, förväntas växa till USD 18,26 miljarder år 2033, med dokumentöversättning som dess största del. Denna tillväxt visar bara hur vitala dessa verktyg har blivit. Du kan läsa mer om dessa marknadstrender på researchnester.com.
Återuppbyggnad av visuella effekter med DTP-programvara
Efter att översättningen är klar lämnas du med ett block av ren text. Det sista, kritiska steget är att få den texten tillbaka in i bokens ursprungliga layout, kompletta med bilder och professionell formatering. Det här är jobbet för skrivbordspublicering (DTP) programvara.
Industristandardprogram som Adobe InDesign används för denna fas. En skicklig designer tar den översatta texten och placerar den försiktigt tillbaka i layouten, infogar bilder igen, justerar mellanslag för att ta hänsyn till textexpansion och säkerställer att den färdiga boken är en perfekt spegelbild av originalet. Det här är en praktisk process som kräver en designers öga, inte ett automatiserat steg. Vår guide till dokumentöversättningsprogramvara dyker djupare in i dessa typer av verktyg.
Bästa praxis för att översätta din PDF-bok
Att få en bokövrsättning rätt, särskilt när du börjar med en PDF, handlar helt om strategi. Om du dyker in utan en plan kan du lätt hamna i en frustrerad, dyr röra. Men genom att följa några beprövade bästa praxis kan du navigera processen smidigt och få ett resultat som gör ditt originalverk rättvisa.
Den första, och långt den viktigaste, regeln är denna: sök alltid efter originalfilen först. Innan du ens tänker på att ta itu med PDF-filen, gör allt du kan för att hitta filen den skapades från, oavsett om det är ett Adobe InDesign-projekt, ett Microsoft Word-dokument eller något liknande. Detta enda steg kan spara dig en värld av bekymmer, vilket kringgår den knepiga och tidskrävande processen att extrahera text och återuppbygga layouten från grunden.
Bedöm din utgångspunkt
Okej, så du har provat allt och PDF-filen är allt du har. Vad nu? Ditt nästa drag är att räkna ut exakt vilken typ av PDF du hanterar. En ren, digitalt skapad PDF är en helt annan sak än en suddig, skannad.
Ett snabbt sätt att testa detta är att öppna dokumentet och försöka markera texten med markören. Om du kan välja enskilda ord och meningar är du i bra skick. Det betyder att texten är "live" och kan förmodligen extraheras rent.
Om du inte kan välja något har du en bildbaserad PDF på händerna, vilket betyder att du är på väg för OCR-steget. Framgången för den processen beror helt på kvaliteten på skanningen.
- Kontrollera klarhet och upplösning: Är bokstäverna skarpa och vassa, eller ser de något suddig ut? Högupplösta skanningar ger OCR-programvara mycket bättre chans att få saker rätt.
- Leta efter komplexa layouter: Håll utkik efter knepig formatering. Saker som flera kolumner, text som lindas runt bilder och massor av tabeller kan lätt förvirra extraheringsverktyg.
- Identifiera handskrivna anteckningar: OCR-teknik är notoriskt dålig på att läsa handskrift. Alla skruvade anteckningar eller märken kommer nästan säkert att behöva transkriberas manuellt.
Förbered för konsekvens och planera för design
Innan ett enda ord översätts måste du tänka på konsekvens. Det här är där en ordlista, eller termbase, kommer in. Det här är helt enkelt en lista över din boks nyckeltermer – tänk på karaktärsnamn, unika begrepp eller varumärkesfraser – tillsammans med deras förgodkända översättningar. Att lämna detta till din översättare är avgörande för att bibehålla konsekvens över alla 400+ sidor, vilket är en av de största tecknen på ett professionellt jobb.
En vanlig fallgrop är att tro att jobbet är gjort när översättningen är klar. I verkligheten är det bara halva kampen. Att återuppbygga bokens design och layout är en separat, och ofta lika intensiv, uppgift.
Slutligen, glöm inte att budgetera tid och resurser för vad som kallas skrivbordspublicering (DTP). Språk tar sällan upp samma mängd utrymme. En översättning från engelska till tyska kan till exempel ofta vara upp till 30% längre. En professionell designer måste gå tillbaka in, justera layouten för att passa den nya texten, infoga alla grafiken igen och se till att den slutliga boken ser lika polerad ut som originalet. Planering för DTP från dag ett sparar dig från obehagliga överraskningar på vägen och säkerställer att din översatta bok är något du kan vara stolt över.
Varför EPUB är det smartare valet för bokövrsättning
Efter att ha kämpat med den knepiga, ofta frustrerade världen av datorstödd översättning PDF arbetsflöden blir det helt uppenbart att det måste finnas ett bättre sätt. Och lyckligtvis finns det. Lösningen är att börja med en EPUB-fil från början, vilket undviker nästan alla de smärtsamma manuella stegen vi just täckte.
Tänk på det så här: en PDF är i princip ett digitalt fotografi av en sida. Texten är tillplattad in i bilden, vilket gör det verkligt besvärligt att extrahera eller ändra. En EPUB är å andra sidan mer som ett dynamiskt Word-dokument. Det är byggt för att vara flexibelt, vilket tillåter text och bilder att reflöda och anpassa sig till vilken skärm som helst – eller vilket språk som helst.
Denna inbyggda anpassningsförmåga är en massiv vinst för författare och översättare. När du använder en EPUB kan du glömma klumpig textextraktion eller rörig OCR-konvertering. Hela strukturen på din bok – varje kapitel, varje rubrik – är redan perfekt bevarad.