
Pourquoi METEOR est important pour la traduction de livres par l'IA
METEOR, acronyme de « Metric for Evaluation of Translation with Explicit ORdering », est un outil d'évaluation de traduction qui privilégie le sens et la fluidité des phrases plutôt que les correspondances de mots exacts. Contrairement à BLEU, qui repose sur un alignement strict mot par mot, METEOR utilise des techniques telles que la racinisation, la correspondance de synonymes et la paraphrase pour mieux évaluer la qualité des traductions. Cela le rend particulièrement efficace pour traduire des livres, où capturer la voix de l'auteur, le ton et la fluidité narrative est essentiel.
Points clés :
- Pourquoi BLEU est insuffisant : L'accent strict de BLEU sur les correspondances de mots exacts pénalise les alternatives valides, a du mal avec les synonymes et ne parvient pas à évaluer la cohérence narrative, ce qui le rend inadapté à la littérature.
- Comment fonctionne METEOR : METEOR aligne les traductions en utilisant des correspondances exactes, des racines de mots, des synonymes et des paraphrases. Il privilégie le rappel (couverture du sens) plutôt que la précision et applique des pénalités pour un mauvais ordre des mots.
- Performance : METEOR atteint une corrélation de 0,964 avec le jugement humain au niveau du corpus, surpassant le 0,817 de BLEU.
- Impact sur les traductions de livres : En se concentrant sur le sens et la fluidité, METEOR garantit que les traductions conservent la profondeur et la lisibilité du texte original, ce qui en fait l'idéal pour les traductions littéraires pilotées par l'IA.
Pour des plateformes comme BookTranslator.ai, METEOR permet des traductions de haute qualité dans plus de 99 langues pour aussi peu que 5,99 $ pour 100 000 mots, rendant la littérature accessible à un public mondial.
Problèmes d'évaluation des traductions de livres par l'IA
Pourquoi BLEU échoue pour les traductions de long format
BLEU (Bilingual Evaluation Understudy), une métrique introduite en 2002, repose sur une correspondance stricte des n-grammes, ce qui échoue souvent à capturer les subtilités de la traduction littéraire.
Le cœur du problème réside dans l'approche de BLEU : il évalue la qualité en faisant correspondre des séquences de 1 à 4 mots exactement comme elles apparaissent dans une référence humaine. Cette méthode rigide a du mal avec la flexibilité créative requise pour traduire la littérature. Comme l'explique l'équipe NLLB :
"BLEU pénalise les traductions alternatives valides. Si la référence dit « la voiture est rouge » et le système produit « l'automobile est rouge », BLEU pénalise l'inadéquation même si le sens est identique" [4].
Cette incapacité à reconnaître les synonymes est particulièrement problématique pour les livres, où le choix des mots porte souvent un poids important. Par exemple, BLEU traite « grand » et « large » comme des mots complètement différents, même s'ils signifient la même chose. De même, il ne tient pas compte de variations comme « courir », « court » et « courait », pénalisant souvent les traductions qui sont à la fois exactes et créatives.
Une autre limitation fondamentale est la conception au niveau du corpus de BLEU. Il a été développé à l'origine pour traiter de grands ensembles de données, et non la précision au niveau des phrases critique pour la littérature. BLEU manque également de la capacité à évaluer la fluidité des phrases ou la cohérence narrative. Comme le note NLLB :
"BLEU ne tient pas compte directement de la fluidité ou de la préservation du sens - c'est purement une mesure de chevauchement d'n-grammes" [4].
Cela signifie qu'une traduction pourrait techniquement inclure tous les mots corrects mais les arranger dans un ordre confus et maladroit - et obtenir quand même un bon score. Ces lacunes soulignent le besoin de méthodes d'évaluation qui privilégient le contexte, la cohérence et l'expérience narrative globale.
Pourquoi le contexte et le sens sont importants dans les livres
Les livres sont plus que de simples collections de phrases - ce sont des récits complexes où chaque mot, structure de phrase et choix stylistique joue un rôle dans la formation de l'expérience du lecteur. L'accent étroit de BLEU sur les correspondances de mots exacts manque cette vue d'ensemble, en particulier quand il s'agit de maintenir la fluidité et la cohérence narrative.
L'écart de compréhension sémantique est particulièrement flagrant. Michael Brenndoerfer le souligne :
"Deux traductions sémantiquement équivalentes pourraient recevoir des scores BLEU très différents selon leurs choix de mots spécifiques" [5].
Cela crée une incitation problématique pour les systèmes d'IA à poursuivre les correspondances de mots exacts au lieu de s'efforcer pour l'exactitude sémantique ou la fluidité naturelle.
La traduction littéraire exige un équilibre entre la précision et le rappel - non seulement éviter les erreurs mais aussi préserver la profondeur, le ton et la résonance émotionnelle du texte original. BLEU met fortement l'accent sur la précision, mais les livres nécessitent des métriques qui mesurent si la traduction capture l'intention de l'auteur et la fluidité narrative. Des outils comme METEOR, qui privilégient le sens et la fluidité en pondérant le rappel neuf fois plus que la précision, offrent une approche plus appropriée pour évaluer les traductions littéraires [1].
sbb-itb-0c0385d
METEOR : Une métrique pour la traduction automatique
Qu'est-ce que METEOR et comment fonctionne-t-il ?
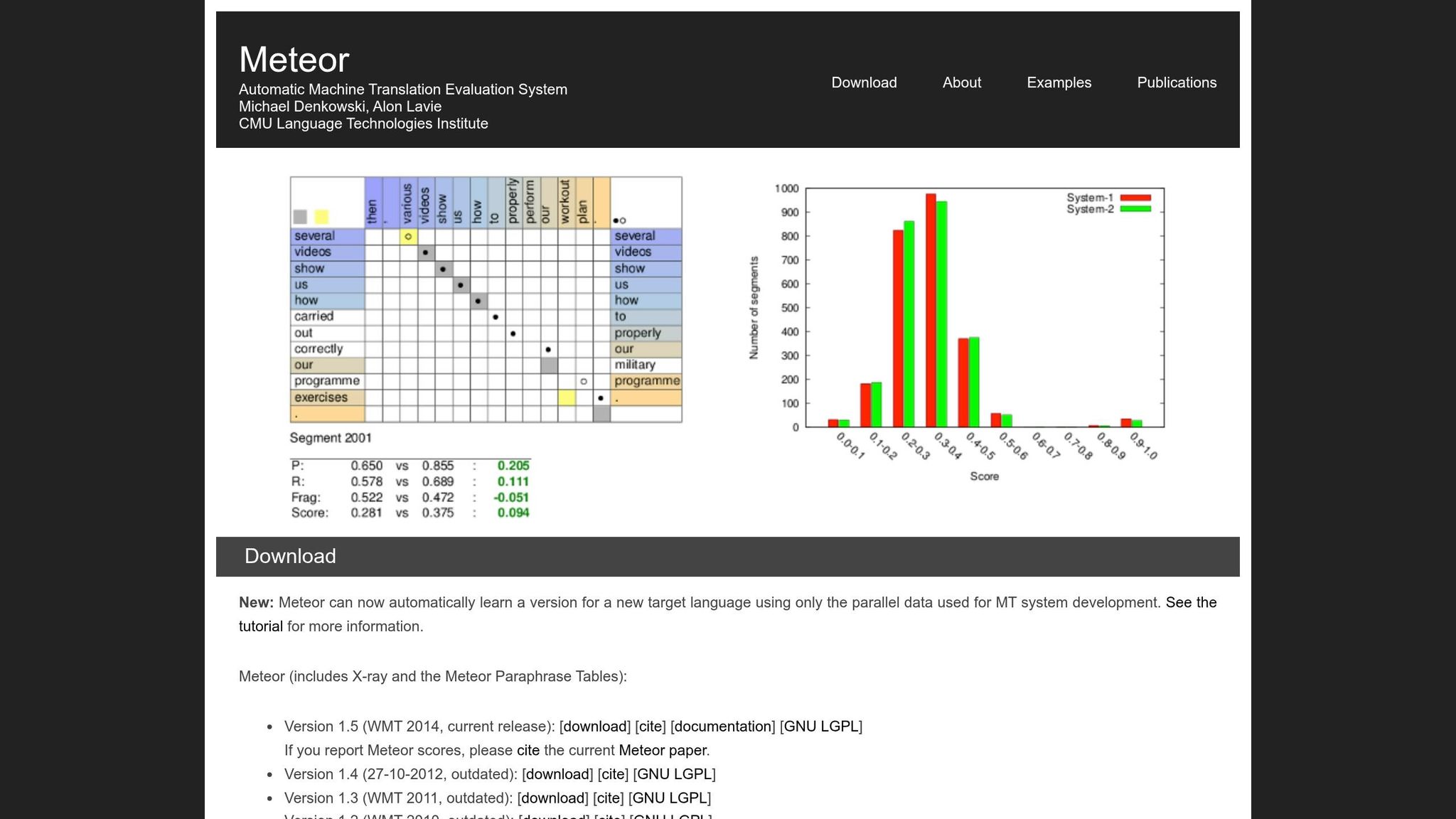
METEOR, acronyme de « Metric for Evaluation of Translation with Explicit ORdering », a été introduit en 2005 par les chercheurs Satanjeev Banerjee et Alon Lavie de l'Université Carnegie Mellon. Il a été développé pour résoudre certaines des limitations de BLEU, en particulier sa correspondance rigide mot par mot. METEOR se concentre sur la préservation du sens et de l'ordre naturel des mots, ce qui le rend particulièrement utile pour évaluer les traductions qui doivent maintenir la fluidité narrative - comme les traductions de livres.
La métrique fonctionne en alignant les mots individuels dans la traduction candidate avec ceux de la traduction de référence. Quand il y a plusieurs façons d'aligner les mots, METEOR choisit celle avec le moins de « croisements » (intersections entre les lignes de mappage). Cette approche aide à maintenir un ordre des mots plus naturel dans le processus d'évaluation [1].
Caractéristiques principales de METEOR
METEOR se distingue par son approche de correspondance en couches, qui va au-delà de la simple correspondance de mots exacts. Il utilise quatre modules séquentiels pour évaluer les traductions :
- Correspondance exacte : Correspond aux formes de mots identiques.
- Racinisation : Correspond aux mots qui partagent la même racine, comme « courir » et « court ».
- Synonymie : Reconnaît les mots avec des sens similaires en utilisant WordNet.
- Correspondance de paraphrase : Correspond aux phrases avec un contenu sémantique similaire.
Cette approche en couches résout la difficulté de BLEU à tenir compte des variations de mots valides et des expressions alternatives [1][2][6].
Le système de notation de METEOR combine deux éléments clés. Tout d'abord, il calcule une moyenne F pondérée de la précision et du rappel, le rappel étant pondéré neuf fois plus lourdement que la précision. Cela reflète la façon dont les humains ont tendance à évaluer la qualité de la traduction, en privilégiant la couverture du sens original plutôt que les correspondances exactes [1]. Deuxièmement, il applique une pénalité de fragmentation pour décourager les traductions où les mots appariés sont dispersés ou désordonnés. Si les mots appariés sont divisés en trop de « chunks », le score peut être pénalisé jusqu'à 50%. Cela garantit que les traductions avec des mots corrects mais une mauvaise structure - souvent appelées « salade de mots » - reçoivent des scores plus bas [1].
Comment METEOR s'aligne avec le jugement humain
Les études montrent que METEOR se corrèle avec le jugement humain mieux que BLEU, atteignant des coefficients de corrélation entre 0,60 et 0,75, comparé à la plage de 0,45 à 0,60 de BLEU [6].
Cet alignement plus fort est largement dû au focus au niveau des phrases de METEOR. Tandis que BLEU est conçu pour évaluer les traductions au niveau du corpus, METEOR évalue les phrases ou segments individuels. Cela le rend particulièrement efficace pour évaluer la fluidité et la cohérence nécessaires dans les traductions de livres [1]. De plus, METEOR peut traiter jusqu'à 500 segments par seconde par cœur CPU, ce qui le rend à la fois efficace et fiable pour un usage pratique [2]. Sa capacité à correspondre étroitement au jugement humain a solidifié son rôle dans l'amélioration des traductions de livres pilotées par l'IA.
METEOR vs BLEU : Pourquoi METEOR fonctionne mieux pour la traduction de livres par l'IA

Comparaison des métriques de traduction METEOR vs BLEU
Avantages clés de METEOR pour la traduction de livres
Quand il s'agit de traduire des œuvres littéraires, METEOR se démarque comme une métrique d'évaluation plus efficace que BLEU. Ses méthodes d'alignement uniques et son accent sur le sens la rendent particulièrement adaptée aux nuances de la traduction de livres.
L'une des principales différences est la façon dont chaque métrique gère l'exactitude sémantique. BLEU repose sur des correspondances de mots exacts, ce qui peut pénaliser injustement les traductions qui utilisent des synonymes ou des formes de mots alternatives - même quand le sens reste intact. METEOR, en revanche, incorpore la racinisation et la correspondance de synonymes. Par exemple, il reconnaît que des mots comme « bon » et « bien » ou « court » et « courir » partagent la même valeur sémantique. Cette flexibilité est essentielle pour les traductions littéraires, où un vocabulaire diversifié et une formulation créative sont souvent nécessaires pour préserver le style et l'intention de l'auteur.
Une autre distinction importante est l'accent de METEOR sur le rappel plutôt que la précision. BLEU privilégie la précision en mesurant combien de mots dans la traduction générée par l'IA correspondent à ceux du texte de référence. METEOR, cependant, équilibre la précision et le rappel, avec le rappel pondéré neuf fois plus lourdement [1]. Cela garantit que la traduction capture le sens complet du texte original - un facteur critique pour transmettre avec précision des récits complexes.
METEOR excelle aussi dans l'évaluation au niveau des phrases. Tandis que BLEU est adapté pour évaluer les traductions au niveau du corpus, METEOR est conçu pour s'aligner étroitement avec le jugement humain sur les phrases ou segments individuels. Il atteint une corrélation maximale d'environ 0,403 au niveau des phrases [1]. Cela le rend particulièrement efficace pour évaluer la fluidité et la cohérence de passages spécifiques, ce qui est essentiel dans la traduction de livres.
L'une des caractéristiques remarquables de METEOR est sa pénalité de fragmentation, qui traite de l'ordre des mots et de la structure des phrases. Si les mots appariés dans la traduction sont dispersés en trop de chunks, le score peut chuter jusqu'à 50% [1]. Ce mécanisme garantit que les traductions maintiennent une structure naturelle et cohérente - quelque chose que BLEU omet souvent. En se concentrant sur ces détails, METEOR aide à préserver le sens nuancé et la lisibilité du texte original.
Tableau de comparaison : METEOR vs BLEU
| Caractéristique | BLEU | METEOR |
|---|---|---|
| Objectif principal | Précision (chevauchement de mots exacts) | Rappel (couverture du sens et du contenu) |
| Critères de correspondance | Correspondance exacte d'n-grammes | Exact, racinisation, synonymes et paraphrases |
| Exactitude sémantique | Faible (correspondances de mots exacts uniquement) | Élevée (inclut synonymes et racinisation) |
| Corrélation humaine | Plus forte au niveau du corpus | Forte aux niveaux des phrases et du corpus |
| Structure des phrases | Indirecte (via chevauchements d'n-grammes) | Directe (via pénalité de fragmentation et alignement) |
| Flexibilité | Rigide ; pénalise la formulation créative | Flexible ; récompense l'équivalence sémantique |
| Gestion du rappel | Indirecte (pénalité de brièveté) | Directe (calcul du rappel pondéré 9x plus) |
Comment METEOR est utilisé dans les plateformes de traduction de livres par l'IA
Assurer la qualité avec METEOR
Les plateformes de traduction alimentées par l'IA exploitent METEOR pour maintenir l'exactitude sémantique et préserver les nuances délicates des œuvres littéraires. Le processus commence par le mappage d'alignement, où le système identifie les connexions entre la traduction générée par l'IA et un texte de référence. Cela implique de reconnaître les correspondances exactes, les racines de mots, les synonymes et même les paraphrases [2]. Un tel mappage détaillé garantit que la traduction reflète le sens original, même si la formulation diffère.
Pour gérer les complexités des différentes langues, METEOR est configuré avec des outils spécifiques à la langue comme des racineurs et des tables de paraphrase. Par exemple, les plateformes comme BookTranslator.ai, qui prend en charge plus de 99 langues, utilisent ces ressources pour résoudre les structures linguistiques uniques de diverses langues. Qu'il s'agisse de langues romanes comme l'espagnol et le français ou de langues plus complexes comme l'arabe et le tchèque, ces outils sont vitaux pour capturer les variations morphologiques [2].
Ce qui distingue METEOR est sa capacité à affiner les paramètres. Les plateformes peuvent calibrer ces paramètres pour s'aligner avec des tâches d'évaluation spécifiques, telles que la mesure de l'adéquation ou le maintien d'un style cohérent. Cette fonctionnalité est particulièrement précieuse dans les traductions littéraires, où préserver la voix de l'auteur et le rythme du récit est essentiel. De plus, la pénalité de fragmentation du système garantit que les phrases s'écoulent naturellement, évitant le sentiment maladroit et décousu d'une simple série de mots corrects. Cette attention à la fluidité des phrases est critique pour garder les lecteurs absorbés par l'histoire sur des centaines de pages.
Au-delà de l'amélioration de la qualité des traductions, METEOR joue également un rôle crucial dans le rendre la littérature plus accessible à un public mondial.
Améliorer l'accès multilingue à la littérature
En sauvegardant le sens et la profondeur du texte original, METEOR non seulement améliore la qualité de la traduction mais aide aussi à apporter la littérature aux lecteurs dans leurs langues maternelles. En utilisant des données parallèles, METEOR permet aux plateformes d'élargir leurs offres linguistiques sans sacrifier la qualité [2]. Cette capacité à s'adapter est particulièrement importante pour les lecteurs des marchés linguistiques sous-représentés.
L'approche d'évaluation axée sur l'humain garantit que les traductions semblent naturelles et attrayantes. Par exemple, des plateformes comme BookTranslator.ai fournissent des traductions à partir de 5,99 $ pour 100 000 mots, rendant les traductions de haute qualité abordables tout en conservant le charme narratif et les subtilités culturelles de l'histoire. En privilégiant le rappel plutôt que la précision, METEOR capture la richesse du texte source, y compris les arcs de personnages complexes et les couches thématiques qui sont essentiels à un récit captivant.
Conclusion
METEOR change la donne dans l'évaluation de la traduction de livres par l'IA en privilégiant l'exactitude sémantique et la lisibilité naturelle. Contrairement aux métriques traditionnelles, METEOR tient compte des synonymes, des racines de mots et des paraphrases, atteignant une impressionnante corrélation de 0,964 avec le jugement humain au niveau du corpus - significativement plus élevée que le 0,817 de BLEU [1]. Cela garantit que les traductions conservent le style de l'auteur, la cohérence narrative et les éléments culturels subtils.
Ce qui distingue METEOR est sa notation pondérée par rappel combinée à une pénalité de fragmentation, qui garantit que les traductions non seulement capturent le sens complet du texte original mais lisent aussi en douceur. Ceci est particulièrement critique pour le contenu de long format, où maintenir la cohérence et la fluidité sur un récit étendu est essentiel.
Pour des plateformes comme BookTranslator.ai, supportant plus de 99 langues, la capacité de METEOR à reconnaître les variations linguistiques permet des traductions de haute qualité à des tarifs compétitifs - à partir de seulement 5,99 $ pour 100 000 mots. En exploitant les données parallèles pour apprendre de nouvelles langues cibles [2], METEOR ouvre la porte aux lecteurs des régions mal desservies pour accéder à la littérature dans leurs langues maternelles.
"METEOR fonctionne plus comme les systèmes modernes de reconnaissance vocale qui comprennent différentes façons de dire la même chose. Il évalue les traductions avec flexibilité, reflétant le jugement humain." - Iterate.ai [3]
FAQ
METEOR est-il suffisant pour juger la qualité d'une traduction de livre ?
METEOR est un outil utile pour mesurer la qualité de la traduction, en particulier quand il s'agit d'identifier les nuances sémantiques et les détails linguistiques. Cependant, s'y fier seul n'est pas suffisant pour évaluer pleinement la qualité d'une traduction de livre. Associer METEOR aux évaluations humaines offre un moyen plus équilibré et approfondi d'évaluer la qualité de la traduction.
Comment METEOR gère-t-il les idiomes et la formulation créative ?
METEOR aborde les défis des idiomes et de la formulation créative par la correspondance de synonymes, la racinisation et l'évaluation linguistique adaptable. Ces outils lui permettent de saisir les expressions subtiles et non littérales, garantissant que les traductions préservent à la fois le sens