
Warum METEOR für die KI-Buchübersetzung wichtig ist
METEOR, kurz für Metric for Evaluation of Translation with Explicit ORdering, ist ein Übersetzungsbewertungstool, das Bedeutung und Satzfluss vor exakte Wortübereinstimmungen priorisiert. Im Gegensatz zu BLEU, das sich auf strikte Wort-für-Wort-Ausrichtung verlässt, verwendet METEOR Techniken wie Stemming, Synonymabgleich und Umformulierung, um die Qualität von Übersetzungen besser zu bewerten. Dies macht es besonders effektiv für die Übersetzung von Büchern, bei denen es entscheidend ist, die Stimme, den Ton und den Erzählfluss des Autors zu erfassen.
Wichtigste Erkenntnisse:
- Warum BLEU unzureichend ist: BLEUs strikte Fokussierung auf exakte Wortübereinstimmungen bestraft gültige Alternativen, hat Schwierigkeiten mit Synonymen und kann narrative Kohärenz nicht bewerten, was es für Literatur ungeeignet macht.
- Wie METEOR funktioniert: METEOR richtet Übersetzungen mit exakten Übereinstimmungen, Wort-Stämmen, Synonymen und Umformulierungen aus. Es priorisiert Recall (Bedeutungsabdeckung) vor Präzision und wendet Strafen für schlechte Wortfolge an.
- Leistung: METEOR erreicht auf Corpus-Ebene eine Korrelation von 0,964 mit menschlichem Urteil und übertrifft BLEUs 0,817.
- Auswirkungen auf Buchübersetzungen: Durch die Fokussierung auf Bedeutung und Fluss stellt METEOR sicher, dass Übersetzungen die Tiefe und Lesbarkeit des Originaltextes bewahren, was es ideal für KI-gesteuerte literarische Übersetzungen macht.
Für Plattformen wie BookTranslator.ai ermöglicht METEOR hochwertige Übersetzungen in über 99 Sprachen für nur 5,99 USD pro 100.000 Wörter, was Literatur einem globalen Publikum zugänglich macht.
Probleme bei der Bewertung von KI-Buchübersetzungen
Warum BLEU bei längeren Übersetzungen versagt
BLEU (Bilingual Evaluation Understudy), eine 2002 eingeführte Metrik, basiert auf striktem N-Gramm-Abgleich, der oft die Subtilität literarischer Übersetzungen nicht erfasst.
Das Kernproblem liegt in BLEUs Ansatz: Es bewertet die Qualität durch Abgleich von 1- bis 4-Wort-Sequenzen, die genau so erscheinen wie in einer menschlichen Referenz. Diese starre Methode hat Schwierigkeiten mit der kreativen Flexibilität, die für die Übersetzung von Literatur erforderlich ist. Wie das NLLB-Team erklärt:
"BLEU bestraft gültige alternative Übersetzungen. Wenn die Referenz „the car is red" sagt und das System „the automobile is red" produziert, bestraft BLEU die Nichtübereinstimmung, obwohl die Bedeutung identisch ist" [4].
Diese Unfähigkeit, Synonyme zu erkennen, ist besonders problematisch für Bücher, wo die Wortewahl oft große Bedeutung hat. Zum Beispiel behandelt BLEU „big" und „large" als völlig unterschiedliche Wörter, obwohl sie das Gleiche bedeuten. Ebenso berücksichtigt es keine Variationen wie „running", „runs" und „ran" und bestraft oft Übersetzungen, die sowohl genau als auch kreativ sind.
Eine weitere Kernbeschränkung ist BLEUs Corpus-Ebenen-Design. Es wurde ursprünglich entwickelt, um große Datensätze zu verarbeiten, nicht die Satz-Ebenen-Präzision, die für Literatur entscheidend ist. BLEU hat auch nicht die Möglichkeit, Satzfluss oder narrative Kohärenz zu bewerten. Wie NLLB anmerkt:
"BLEU berücksichtigt nicht direkt Flüssigkeit oder Bedeutungsbewahrung – es ist rein ein N-Gramm-Überlappungsmaß" [4].
Das bedeutet, eine Übersetzung könnte technisch alle richtigen Wörter enthalten, aber in einer ungeordneten, unbeholfenen Reihenfolge anordnen – und würde immer noch gut abschneiden. Diese Mängel verdeutlichen die Notwendigkeit von Bewertungsmethoden, die Kontext, Kohärenz und das Gesamtnarrative-Erlebnis priorisieren.
Warum Kontext und Bedeutung in Büchern wichtig sind
Bücher sind mehr als nur Satzsammlungen – sie sind komplexe Narrative, in denen jedes Wort, jede Satzstruktur und stilistische Wahl eine Rolle bei der Gestaltung des Leseerlebnisses spielt. BLEUs enger Fokus auf exakte Wortübereinstimmungen verfehlt dieses größere Bild, besonders wenn es um die Erhaltung von Erzählfluss und Kohärenz geht.
Die semantische Verständnislücke ist besonders auffällig. Michael Brenndoerfer weist darauf hin:
"Zwei semantisch äquivalente Übersetzungen könnten je nach ihren spezifischen Wortwahlmöglichkeiten sehr unterschiedliche BLEU-Scores erhalten" [5].
Dies schafft einen problematischen Anreiz für KI-Systeme, nach exakten Wortübereinstimmungen zu streben, anstatt semantische Genauigkeit oder natürliche Flüssigkeit anzustreben.
Literarische Übersetzung erfordert ein Gleichgewicht zwischen Präzision und Recall – nicht nur Fehler vermeiden, sondern auch die Tiefe, den Ton und die emotionale Resonanz des Originaltextes bewahren. BLEU betont stark die Präzision, aber Bücher erfordern Metriken, die messen, ob die Übersetzung die Absicht des Autors und den Erzählfluss erfasst. Tools wie METEOR, die Bedeutung und Fluss priorisieren, indem sie Recall neunmal höher gewichten als Präzision, bieten einen passenderen Ansatz für die Bewertung literarischer Übersetzungen [1].
sbb-itb-0c0385d
METEOR : Eine Metrik für maschinelle Übersetzung
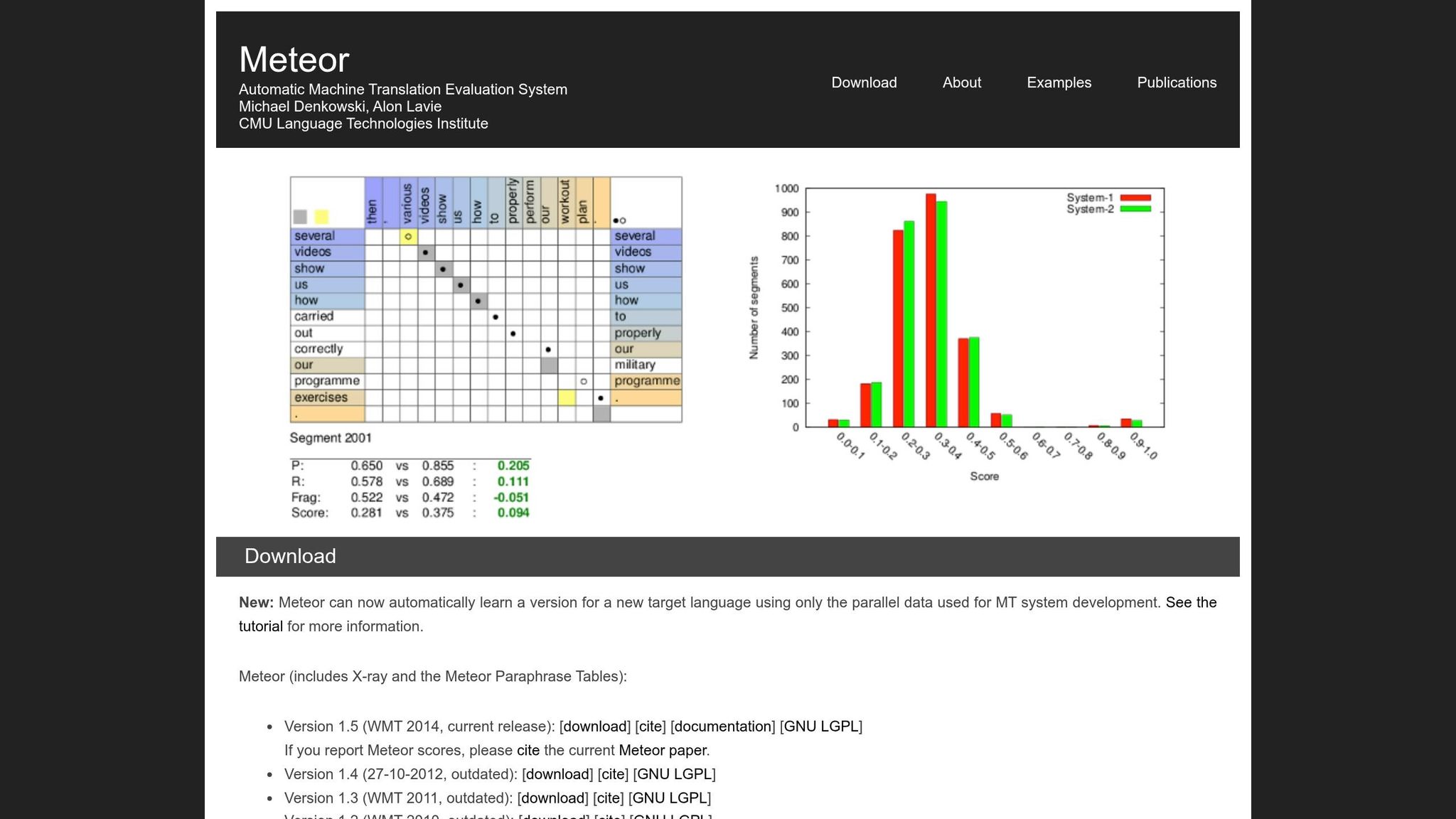
Was ist METEOR und wie funktioniert es?
METEOR, kurz für Metric for Evaluation of Translation with Explicit ORdering, wurde 2005 von den Forschern Satanjeev Banerjee und Alon Lavie an der Carnegie Mellon University eingeführt. Es wurde entwickelt, um einige der Einschränkungen von BLEU zu beheben, insbesondere sein starres Wort-für-Wort-Matching. METEOR konzentriert sich auf die Bewahrung von Bedeutung und natürlicher Wortfolge, was es besonders nützlich für die Bewertung von Übersetzungen macht, die den Erzählfluss beibehalten müssen – wie Buchübersetzungen.
Die Metrik funktioniert durch die Ausrichtung einzelner Wörter in der Kandidatenübersetzung mit denen in der Referenzübersetzung. Wenn es mehrere Möglichkeiten gibt, die Wörter auszurichten, wählt METEOR diejenige mit der geringsten Anzahl von „Kreuzungen" (Schnittpunkten zwischen Zuordnungslinien). Dieser Ansatz hilft, eine natürlichere Wortfolge im Bewertungsprozess beizubehalten [1].
Kernfunktionen von METEOR
METEOR zeichnet sich durch seinen gestuften Abgleichansatz aus, der über exakte Wortübereinstimmungen hinausgeht. Es verwendet vier sequenzielle Module zur Bewertung von Übersetzungen:
- Exakter Abgleich: Stimmt identische Wortformen ab.
- Stemming: Stimmt Wörter ab, die die gleiche Wurzel teilen, wie „running" und „runs".
- Synonymie: Erkennt Wörter mit ähnlichen Bedeutungen mit WordNet.
- Umformulierungsabgleich: Stimmt Phrasen mit ähnlichem semantischem Inhalt ab.
Dieser geschichtete Ansatz behebt BLEUs Schwierigkeiten, gültige Wortvariation und alternative Ausdrücke zu berücksichtigen [1][2][6].
METEORs Bewertungssystem kombiniert zwei Schlüsselelemente. Erstens berechnet es einen gewichteten F-Mittelwert von Präzision und Recall, wobei Recall neunmal höher gewichtet wird als Präzision. Dies spiegelt wider, wie Menschen die Übersetzungsqualität bewerten, indem sie die Abdeckung der ursprünglichen Bedeutung vor exakten Übereinstimmungen priorisieren [1]. Zweitens wendet es eine Fragmentierungsstrafe an, um Übersetzungen zu entmutigen, bei denen übereinstimmende Wörter verstreut oder außer Reihenfolge sind. Wenn die übereinstimmenden Wörter in zu viele „Chunks" unterbrochen werden, kann die Punktzahl um bis zu 50% bestraft werden. Dies stellt sicher, dass Übersetzungen mit korrekten Wörtern, aber schlechter Struktur – oft als „Wort-Salat" bezeichnet – niedrigere Punktzahlen erhalten [1].
Wie METEOR mit menschlichem Urteil übereinstimmt
Studien zeigen, dass METEOR besser mit menschlichem Urteil korreliert als BLEU, mit Korrelationskoeffizienten zwischen 0,60 und 0,75, im Vergleich zu BLEUs Bereich von 0,45 bis 0,60 [6].
Diese stärkere Übereinstimmung ist größtenteils auf METEORs Satz-Ebenen-Fokus zurückzuführen. Während BLEU für die Bewertung von Übersetzungen auf Corpus-Ebene ausgelegt ist, bewertet METEOR einzelne Sätze oder Segmente. Dies macht es besonders effektiv für die Bewertung des Flusses und der Kohärenz, die in Buchübersetzungen erforderlich sind [1]. Darüber hinaus kann METEOR bis zu 500 Segmente pro Sekunde pro CPU-Kern verarbeiten, was es sowohl effizient als auch zuverlässig für den praktischen Gebrauch macht [2]. Seine Fähigkeit, menschliche Urteile genau zu treffen, hat seine Rolle bei der Verbesserung von KI-gesteuerten Buchübersetzungen gefestigt.
METEOR vs. BLEU: Warum METEOR besser für die KI-Buchübersetzung funktioniert

METEOR vs BLEU Übersetzungsmetriken-Vergleich
Wichtigste Vorteile von METEOR für die Buchübersetzung
Wenn es um die Übersetzung literarischer Werke geht, zeichnet sich METEOR als effektivere Bewertungsmetrik als BLEU aus. Seine einzigartigen Ausrichtungsmethoden und sein Fokus auf Bedeutung machen es besonders geeignet für die Nuancen der Buchübersetzung.
Einer der Hauptunterschiede liegt darin, wie jede Metrik semantische Genauigkeit handhabt. BLEU basiert auf exakten Wortübereinstimmungen, die Übersetzungen unfair bestrafen können, die Synonyme oder alternative Wortformen verwenden – selbst wenn die Bedeutung intakt bleibt. METEOR hingegen integriert Stemming und Synonymabgleich. Zum Beispiel erkennt es, dass Wörter wie „good" und „well" oder „runs" und „running" den gleichen semantischen Wert haben. Diese Flexibilität ist für literarische Übersetzungen wesentlich, bei denen vielfältige Vokabeln und kreative Formulierungen oft notwendig sind, um den Stil und die Absicht des Autors zu bewahren.
Ein weiterer wichtiger Unterschied ist METEORs Betonung von Recall gegenüber Präzision. BLEU priorisiert Präzision durch Messung, wie viele Wörter in der KI-generierten Übersetzung mit denen im Referenztext übereinstimmen. METEOR hingegen balanciert Präzision und Recall, wobei Recall neunmal höher gewichtet wird [1]. Dies stellt sicher, dass die Übersetzung die volle Bedeutung des Originaltexts erfasst – ein kritischer Faktor für die genaue Vermittlung komplexer Narrative.
METEOR zeichnet sich auch in der Satz-Ebenen-Bewertung aus. Während BLEU für die Bewertung von Übersetzungen auf Corpus-Ebene ausgelegt ist, ist METEOR darauf ausgelegt, eng mit menschlichem Urteil auf einzelne Sätze oder Segmente abzustimmen. Es erreicht eine maximale Korrelation von etwa 0,403 auf Satz-Ebene [1]. Dies macht es besonders effektiv für die Bewertung des Flusses und der Kohärenz spezifischer Passagen, was für Buchübersetzungen entscheidend ist.
Eine der hervorstechendsten Funktionen von METEOR ist seine Fragmentierungsstrafe, die Wortfolge und Satzstruktur behandelt. Wenn übereinstimmende Wörter in der Übersetzung in zu viele Chunks verstreut sind, kann die Punktzahl um bis zu 50% sinken [1]. Dieser Mechanismus stellt sicher, dass Übersetzungen eine natürliche und kohärente Struktur beibehalten – etwas, das BLEU oft übersieht. Durch Fokussierung auf diese Details hilft METEOR, die nuancierte Bedeutung und Lesbarkeit des Originaltexts zu bewahren.
Vergleichstabelle: METEOR vs. BLEU
| Funktion | BLEU | METEOR |
|---|---|---|
| Primärer Fokus | Präzision (exakte Wortübereinstimmung) | Recall (Bedeutungs- und Inhaltsabdeckung) |
| Abgleichkriterien | Exakter N-Gramm-Abgleich | Exakt, Stemming, Synonyme und Umformulierungen |
| Semantische Genauigkeit | Niedrig (nur exakte Wortübereinstimmungen) | Hoch (einschließlich Synonyme und Stemming) |
| Menschliche Korrelation | Stärker auf Corpus-Ebene | Stark auf Satz- und Corpus-Ebene |
| Satzstruktur | Indirekt (über N-Gramm-Überlappungen) | Direkt (über Fragmentierungsstrafe und Ausrichtung) |
| Flexibilität | Starr; bestraft kreative Formulierung | Flexibel; belohnt semantische Äquivalenz |
| Recall-Handhabung | Indirekt (Kürzestrafe) | Direkt (Recall-Berechnung 9x höher gewichtet) |
Wie METEOR in KI-Buchübersetzungsplattformen verwendet wird
Qualitätssicherung mit METEOR
KI-gestützte Übersetzungsplattformen nutzen METEOR, um semantische Genauigkeit zu wahren und die feinen Nuancen literarischer Werke zu bewahren. Der Prozess beginnt mit Ausrichtungszuordnung, bei der das System Verbindungen zwischen der KI-generierten Übersetzung und einem Referenztext identifiziert. Dies beinhaltet die Erkennung von exakten Übereinstimmungen, Wort-Stämmen, Synonymen und sogar Umformulierungen [2]. Solche detaillierten Zuordnungen stellen sicher, dass die Übersetzung die ursprüngliche Bedeutung widerspiegelt, auch wenn sich die Formulierung unterscheidet.
Um die Komplexität verschiedener Sprachen zu bewältigen, wird METEOR mit sprachspezifischen Tools wie Stemmern und Umformulierungstabellen konfiguriert. Zum Beispiel verwenden Plattformen wie BookTranslator.ai, die über 99 Sprachen unterstützen, diese Ressourcen, um die einzigartigen linguistischen Strukturen verschiedener Sprachen zu adressieren. Ob es sich um romanische Sprachen wie Spanisch und Französisch oder komplexere wie Arabisch und Tschechisch handelt, diese Tools sind vital für die Erfassung morphologischer Variationen [2].
Was METEOR auszeichnet, ist seine Fähigkeit, Parameter zu feinabstimmen. Plattformen können diese Einstellungen kalibrieren, um mit spezifischen Bewertungsaufgaben übereinzustimmen, wie z. B. die Messung von Angemessenheit oder die Aufrechterhaltung eines konsistenten Stils. Diese Funktion ist besonders wertvoll in literarischen Übersetzungen, bei denen die Bewahrung der Stimme des Autors und des Rhythmus der Erzählung wesentlich ist. Darüber hinaus stellt die Fragmentierungsstrafe des Systems sicher, dass Sätze natürlich fließen und das unbeholfene, zusammenhanglose Gefühl einer bloßen Reihe korrekter Wörter vermieden wird. Diese Aufmerksamkeit für Satzflüssigkeit ist entscheidend, um Leser über hunderte von Seiten in der Geschichte zu halten.
Über die Verbesserung der Übersetzungsqualität hinaus spielt METEOR auch eine zentrale Rolle dabei, Literatur für ein globales Publikum zugänglicher zu machen.
Verbesserung des mehrsprachigen Zugangs zu Literatur
Durch den Schutz der Bedeutung und Tiefe des Originaltexts verbessert METEOR nicht nur die Übersetzungsqualität, sondern hilft auch, Literatur Lesern in ihren Muttersprachen näher zu bringen. Mit parallelen Daten ermöglicht METEOR Plattformen, ihre Sprachangebote zu erweitern, ohne die Qualität zu beeinträchtigen [2]. Diese Anpassungsfähigkeit ist besonders wichtig für Leser in unterrepräsentierten Sprachmärkten.
Der menschenzentrierte Bewertungsansatz stellt sicher, dass Übersetzungen natürlich und ansprechend wirken. Zum Beispiel bieten Plattformen wie BookTranslator.ai Übersetzungen ab 5,99 USD pro 100.000 Wörter an, was hochwertige Übersetzungen erschwinglich macht, während die narrative Anziehungskraft und kulturelle Subtilität der Geschichte bewahrt werden. Durch die Priorisierung von Recall gegenüber Präzision erfasst METEOR den Reichtum des Quelltexts, einschließlich komplizierter Charakterentwicklungen und thematischer Schichten, die für fesselndes Geschichtenerzählen wesentlich sind.
Fazit
METEOR verändert das Spiel bei der Bewertung von KI-Buchübersetzungen, indem es semantische Genauigkeit und natürliche Lesbarkeit priorisiert. Im Gegensatz zu traditionellen Metriken berücksichtigt METEOR Synonyme, Wort-Stämme und Umformulierungen und erreicht eine beeindruckende Korrelation von 0,964 mit menschlichem Urteil auf Corpus-Ebene – deutlich höher als BLEUs 0,817 [1]. Dies stellt sicher, dass Übersetzungen den Stil des Autors, narrative Konsistenz und subtile kulturelle Elemente bewahren.
Was METEOR auszeichnet, ist seine Recall-gewichtete Bewertung kombiniert mit einer Fragmentierungsstrafe, die sicherstellt, dass Übersetzungen nicht nur die volle Bedeutung des Originaltexts erfassen, sondern auch flüssig lesen. Dies ist besonders entscheidend für längere Inhalte, bei denen die Aufrechterhaltung von Kohärenz und Fluss über eine umfangreiche Erzählung hinweg wesentlich ist.
Für Plattformen wie BookTranslator.ai