
Übersetzungsgenauigkeitsmetriken: Erklärt
Übersetzungsgenauigkeitsmetriken helfen zu bewerten, wie gut maschinelle Übersetzungen mit von Menschen erstellten Referenzen übereinstimmen. Diese Tools sind entscheidend für die Beurteilung der Übersetzungsqualität, besonders bei großen Projekten oder hochsensiblen Inhalten. Metriken fallen in drei Kategorien:
- String-basierte Metriken: BLEU, METEOR und TER konzentrieren sich auf Wort- oder Zeichenübereinstimmungen.
- Neuronale Metriken: COMET und BERTScore analysieren semantische Ähnlichkeit mithilfe von KI-Modellen.
- Menschliche Bewertungen: Direkte Bewertungen wie MQM konzentrieren sich auf Angemessenheit und Flüssigkeit.
Wichtigste Erkenntnisse:
- BLEU: Schnell und einfach, aber schwierig bei Synonymen und tieferer Bedeutung.
- METEOR: Berücksichtigt Synonyme und sprachliche Nuancen; besser für literarische Werke.
- TER: Misst Bearbeitungsaufwand, ignoriert aber semantische Qualität.
- COMET & BERTScore: Fortgeschrittene KI-Modelle, die eng mit menschlichem Urteil übereinstimmen, großartig für nuancierte Texte.
Bei Buchübersetzungen stellt die Kombination automatisierter Tools mit menschlichen Bewertungen Genauigkeit sicher und bewahrt den ursprünglichen Stil. Plattformen wie BookTranslator.ai verwenden diesen hybriden Ansatz, um zuverlässige Ergebnisse in über 99 Sprachen zu liefern.
Gängige Übersetzungsgenauigkeitsmetriken
BLEU-Score
BLEU (Bilingual Evaluation Understudy) wurde 2002 eingeführt und bleibt eine bevorzugte Metrik zur Bewertung von maschinellen Übersetzungen [4]. Es funktioniert durch den Vergleich von N-Gramm-Genauigkeit, was bedeutet, dass analysiert wird, wie Wortsequenzen in der Ausgabe der Maschine mit Referenzübersetzungen übereinstimmen. BLEU-Scores reichen von 0 bis 1, wobei höhere Zahlen bessere Qualität signalisieren. Seine größte Stärke? Geschwindigkeit und Einfachheit - BLEU kann Tausende von Übersetzungen schnell verarbeiten, was es äußerst praktisch macht. Diese Effizienz brachte ihm sogar den NAACL 2018 Test-of-Time Award ein.
Wie Papineni et al. erklärten: „Die Hauptidee besteht darin, einen gewichteten Durchschnitt von N-Gramm-Übereinstimmungen variabler Länge zwischen der Systemübersetzung und einer Reihe von menschlichen Referenzübersetzungen zu verwenden" [4].
BLEU hat jedoch eine bemerkenswerte Einschränkung: Es bevorzugt exakte Wortübereinstimmungen. Das bedeutet, dass es Übersetzungen, die die gleiche Bedeutung vermitteln, aber andere Formulierungen verwenden, möglicherweise unterbewertet. Um dies zu beheben, zielen Metriken wie METEOR darauf ab, sprachliche Nuancen zu erfassen.
METEOR-Metrik
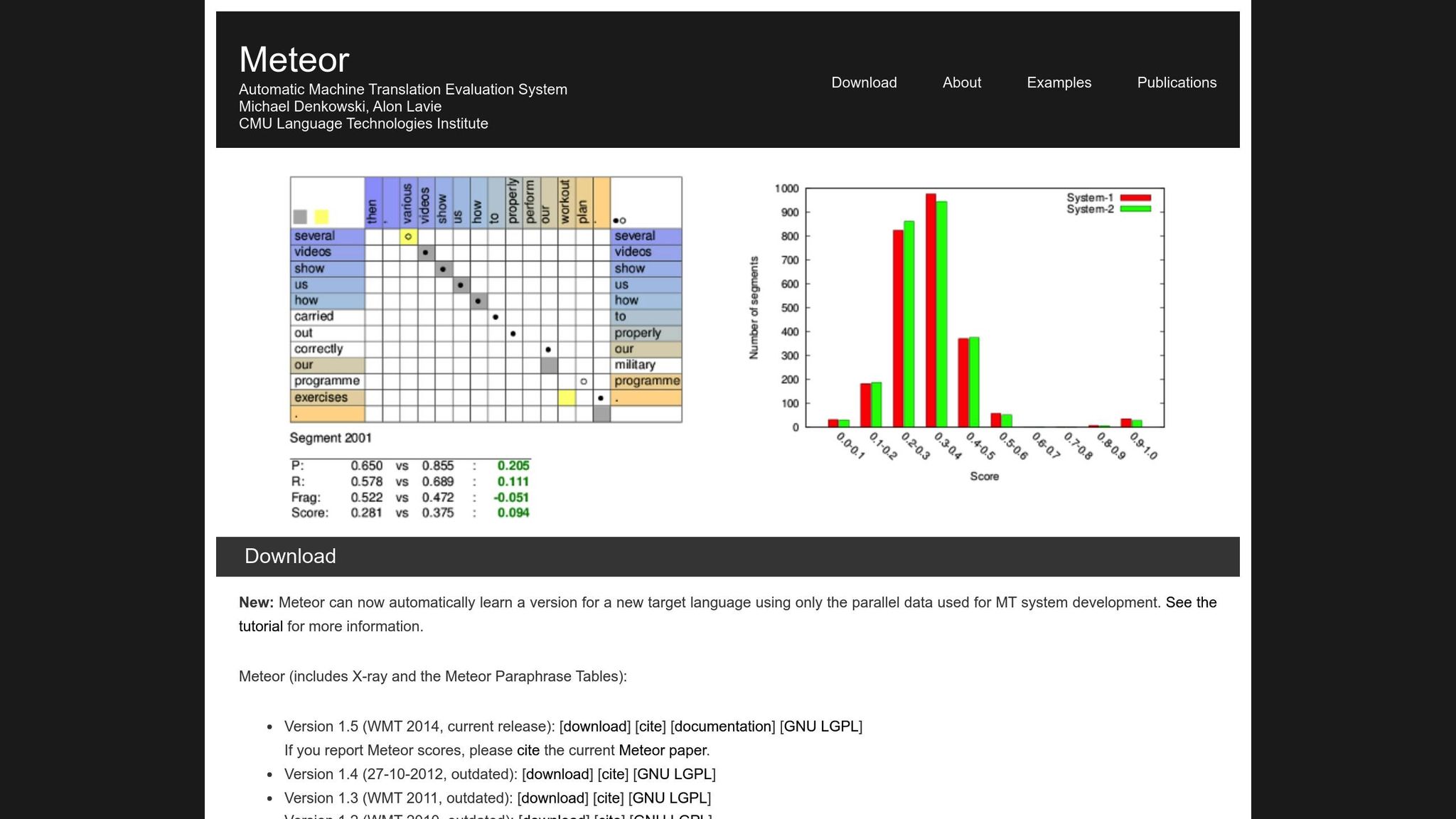
METEOR (Metric for Evaluation of Translation with Explicit ORdering) verbessert BLEU, indem es Genauigkeit, Rückruf, Synonyme, Stammformreduktion und Wortordnungsstrafen berücksichtigt [1]. Es handhabt Variationen wie „laufen" vs. „rannte" oder „glücklich" vs. „freudig", was es besser für Übersetzungen geeignet macht, bei denen Bedeutung am wichtigsten ist. Zum Beispiel erreichte METEOR-next-rank während der NIST MetricsMaTr10-Herausforderung eine Spearman-Rho-Korrelation von 0,92 mit menschlichen Urteilen auf Systemebene und 0,84 auf Dokumentebene [1].
Allerdings hat METEOR auch seine eigenen Herausforderungen. Es erfordert zusätzliche Ressourcen wie Synonymdatenbanken und Stammformreduktionsalgorithmen, die die Rechenlast erhöhen. Dennoch bietet es oft eine nuanciertere und zuverlässigere Bewertung, besonders beim Erfassen semantischer Genauigkeit.
Translation Edit Rate (TER)
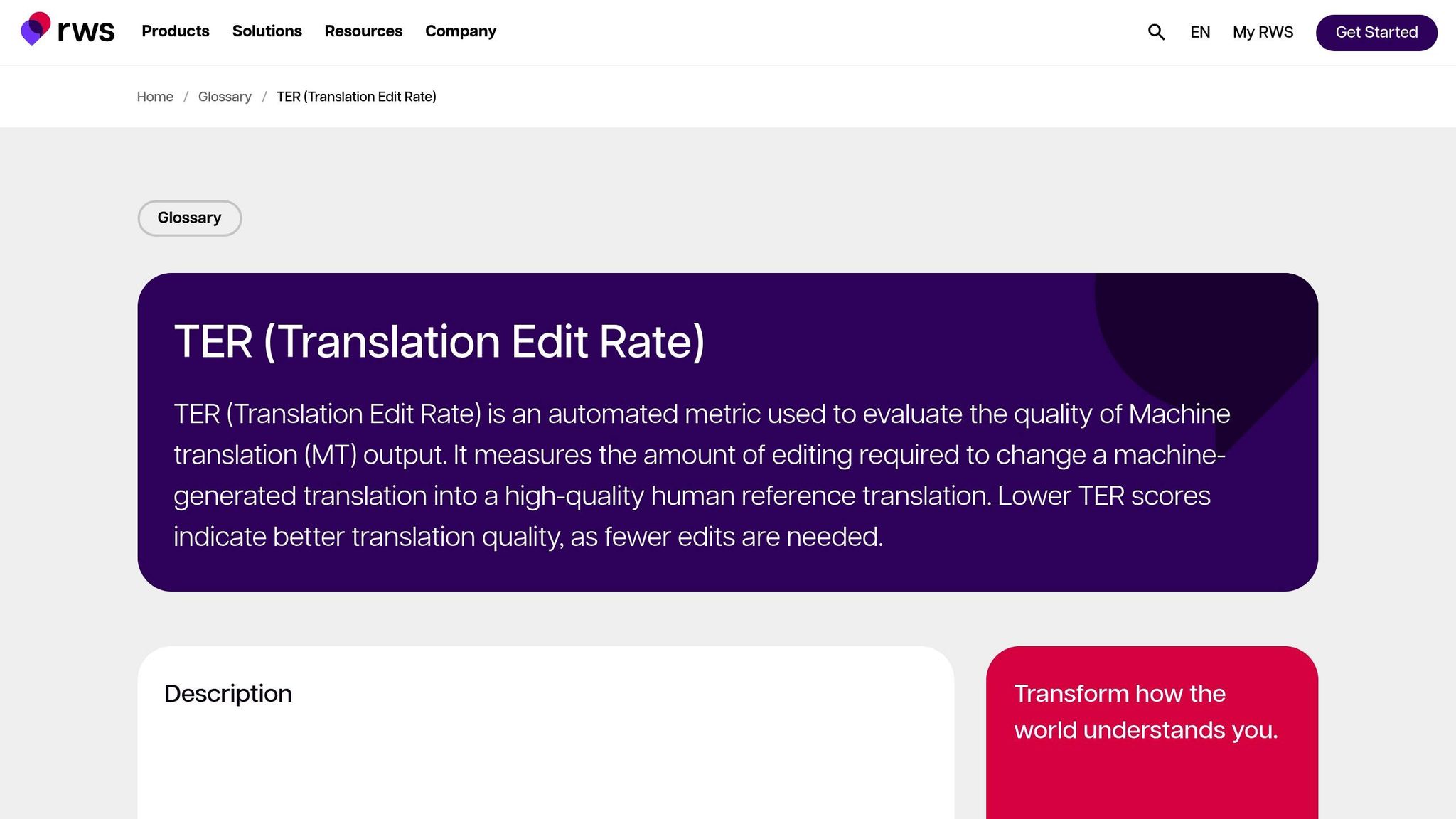
TER bewertet die Übersetzungsqualität, indem es die Anzahl der Bearbeitungen berechnet – Einfügungen, Löschungen, Ersetzungen und Verschiebungen – die erforderlich sind, um die maschinelle Ausgabe in die Referenz umzuwandeln. Dies macht es besonders nützlich, um den Bearbeitungsaufwand zu messen, der erforderlich ist, um die Ausgabe mit dem gewünschten Ergebnis abzustimmen. In den MetricsMaTr10-Bewertungen zeigte TER-v0.7.25 eine Systemebenen-Korrelation von 0,89 mit menschlichen Bewertungen der semantischen Angemessenheit, während TERp eine Segmentebenen-Korrelation von 0,68 zeigte [1].
Neuronale Metriken: BERTScore, COMET und GEMBA
Neuronale Metriken bringen die Übersetzungsbewertung auf die nächste Stufe, indem sie sich auf semantische Analyse statt auf exakte Wortübereinstimmungen konzentrieren. Hier ist ein schneller Überblick:
- BERTScore: Verwendet kontextuelle Einbettungen, um die Ähnlichkeit zwischen Übersetzungen zu messen.
- COMET: Integriert Quelltext, Hypothese und Referenzübersetzungen in ein neuronales Framework, das auf menschlichen Annotationen trainiert ist. Es hat einige der höchsten Korrelationen mit menschlichen Qualitätsurteilen erreicht [5].
- GEMBA: Nutzt große Sprachmodelle für Zero-Shot-Qualitätsschätzung und bietet eine nähere Annäherung an menschliche Bewertung.
Während diese Metriken leistungsstark sind, haben sie Kompromisse. Im Gegensatz zu BLEU und TER, die auf Standard-CPUs in Millisekunden ausgeführt werden können, erfordern neuronale Metriken wie BERTScore und COMET oft GPU-Beschleunigung, um große Datensätze effizient zu verarbeiten. GEMBA insbesondere kann hohe API-Kosten und potenzielle Verzerrungen von großen Sprachmodellen mit sich bringen, was es für manche Benutzer weniger zugänglich macht.
Automatische Metriken zur Bewertung von MT-Systemen
Vergleich von Übersetzungsmetriken

Vergleich der Übersetzungsgenauigkeitsmetriken: BLEU, METEOR, TER, BERTScore, COMET und GEMBA
Metrik-Vergleichstabelle
Die Wahl der richtigen Übersetzungsmetrik hängt oft vom Fokus Ihrer Bewertung und den verfügbaren Ressourcen ab. Traditionelle Metriken wie BLEU sind schnell und erfordern minimale Ressourcen, können aber tiefere semantische Bedeutung nicht erfassen. Andererseits sind neuronale Metriken hervorragend darin, Kontext und Bedeutung zu verstehen, erfordern aber mehr Rechenleistung.
Neuere Forschungen deuten darauf hin, sich von Überlappungsmetriken abzuwenden. Beispielsweise empfehlen WMT22-Erkenntnisse, Metriken wie BLEU zugunsten neuronaler Ansätze aufzugeben [6]. Die Studie hebt hervor, dass Überlappungsmetriken wie BLEU, spBLEU und chrF schlecht mit Bewertungen von menschlichen Experten korrelieren.
Hier ist ein schneller Vergleich der wichtigsten Übersetzungsmetriken, der ihre Fokusgebiete, Bewertungsmethoden, Korrelation mit menschlicher Bewertung, Einschränkungen und Eignung für Buchübersetzungen abdeckt:
| Metrik | Fokusgebiet | Bewertungsbereich | Korrelation mit menschlicher Bewertung | Einschränkungen | Eignung für Buchübersetzungen |
|---|---|---|---|---|---|
| BLEU | N-Gramm-Genauigkeit | 0 bis 1 (oder 0-100) | Niedrig bis Moderat | Schwierig bei Synonymen [7][8] | Niedrig; Unfähigkeit, literarischen Stil zu erfassen |
| METEOR | Genauigkeit, Rückruf, Synonyme, Wortordnung | 0 bis 1 | Hoch | Erfordert sprachspezifische Ressourcen [7] | Moderat; nützlich für konsistente Terminologie |
| TER | Bearbeitungsdistanz (Nachbearbeitungsaufwand) | 0 bis 1 (niedriger ist besser) | Moderat | Ignoriert semantische Qualität [7] | Niedrig; konzentriert sich auf Mechanik, nicht auf „Stimme" |
| BERTScore | Semantische Ähnlichkeit über kontextuelle Einbettungen | 0 bis 1 | Hoch | Ressourcenintensiv [7] | Hoch; erfasst tiefere Bedeutung und Kontext |
| COMET | Semantische Ähnlichkeit und Flüssigkeit | 0 bis 1 (0,5-0,8 typisch) | Sehr hoch | Erfordert vortrainierte Modelle [7][8] | Hoch; bewahrt Stil und nuancierte Bedeutung |
| GEMBA | Holistische LLM-basierte Bewertung | Variiert | Hoch | Komplexes Setup; teure APIs [7] | Hoch; bietet eine „menschenähnliche" umfassende Überprüfung |
Diese Tabelle unterstreicht, wie verschiedene Metriken mit spezifischen Übersetzungsanforderungen übereinstimmen. Für technische Übersetzungen bieten Metriken wie BLEU und TER schnelle, grundlegende Benchmarks. Für literarische Übersetzungen jedoch – wo Stil, Ton und nuancierte Bedeutung kritisch sind – funktionieren neuronale Metriken wie BERTScore und COMET viel besser. Diese Tools sind besonders geschickt darin, die Tiefe und Kunstfertigkeit literarischer Texte zu erfassen, was traditionelle Metriken oft übersehen [7].
Zum Beispiel profitieren Plattformen wie BookTranslator.ai, die Effizienz und Qualität ausbalancieren möchten, erheblich von neuronalen Metriken. Tools wie BERTScore und COMET stellen sicher, dass sowohl semantische Genauigkeit als auch literarischer Stil bewahrt werden.
Um die Dinge in Perspektive zu setzen: Ein „guter" BLEU-Score liegt normalerweise zwischen 30 und 40, wobei Scores über 40 als stark angesehen werden, und alles über 50 weist auf hochwertige Übersetzung hin [8]. Für COMET liegen Scores im Allgemeinen zwischen 0,5 und 0,8, wobei Werte näher an 1,0 Übersetzungsqualität auf menschlichem Niveau widerspiegeln [8]. Neuronale Metriken funktionieren nicht nur konsistent über verschiedene Texttypen hinweg, sondern passen sich auch besser an unterschiedliche Kontexte an als domänenempfindliche Metriken wie BLEU [6].
sbb-itb-0c0385d
Menschliche Bewertungsmethoden
Automatisierte Metriken mögen Geschwindigkeit und Konsistenz bieten, aber sie übersehen oft die subtilen Details, die Übersetzungsqualität definieren. Hier kommt menschliche Bewertung als Goldstandard ins Spiel[2]. Obwohl sie langsamer und teurer ist, deckt menschliche Bewertung die tieferen Gründe für Qualitätsprobleme auf – Dinge, die Metriken wie BLEU oder COMET einfach nicht identifizieren können[9].
Es gibt zwei Hauptansätze zur menschlichen Bewertung. Einer ist Directly Expressed Judgment (DEJ), bei dem Übersetzungen auf Skalen wie Flüssigkeit und Angemessenheit bewertet werden. Der andere umfasst Nicht-DEJ-Methoden, die sich auf das Erkennen und Kategorisieren spezifischer Fehler konzentrieren, oft unter Verwendung von Frameworks wie MQM[12]. Während analytische Methoden einzelne Fehler und deren Schweregrad aufschlüsseln, betrachten holistische Methoden die Gesamtqualität. Zusammen bilden diese Ansätze das Rückgrat von Frameworks wie MQM.
MQM (Multidimensionale Qualitätsmetriken)

Wenn automatisierte Tools nicht ausreichen, bietet MQM eine detailliertere und handlungsorientierte Alternative. Es unterteilt Übersetzungsfehler in Kategorien wie Genauigkeit, Flüssigkeit, Terminologie, Locale-Konventionen und Design/Markup, anstatt Qualität mit einer einzelnen Zahl zusammenzufassen[18, 17].
„Im Gegensatz dazu bieten automatisierte Metriken typischerweise nur eine Zahl ohne Hinweis darauf, wie Ergebnisse verbessert werden können."
– MQM-Komitee[10]
Fehler werden nach Schweregrad bewertet: Neutral (gekennzeichnet aber akzeptabel, keine Strafe), Minor (leicht bemerkenswert, Strafgewicht von 1), Major (beeinträchtigt Verständnis, Strafgewicht von 5) und Critical (macht den Text unbrauchbar, Strafgewicht von 25)[11]. Für kritische Übersetzungen, wie juristische Dokumente, könnten Bestehensschwellen so hoch wie 99,5 auf einer Rohpunkteskala gesetzt werden[11].
Was MQM besonders nützlich macht, ist seine Fähigkeit, spezifische Problembereiche zu identifizieren. Wenn beispielsweise eine literarische Übersetzung schlecht abschneidet, kann MQM offenbaren, ob das Problem in unbeholfenen Formulierungen oder inkonsistenter Terminologie liegt. Dieses Maß an Detail ist besonders wertvoll für Plattformen wie BookTranslator.ai, wo sowohl Bedeutung als auch literarischer Stil erfasst werden müssen.
Angemessenheits- und Flüssigkeitsbewertung
Aufbauend auf strukturierten Frameworks wie MQM konzentrieren sich Bewerter auch auf zwei Schlüsseldimensionen der Übersetzungsqualität: Angemessenheit und Flüssigkeit. Angemessenheit misst, wie gut die Übersetzung die Bedeutung des Quelltexts vermittelt, während Flüssigkeit bewertet, wie natürlich und lesbar sie für Muttersprachler ist. Diese Aspekte werden oft auf Fünf-Punkte-Skalen bewertet[9].
Das Ausbalancieren dieser beiden Dimensionen kann schwierig sein, besonders bei literarischen Übersetzungen. Die Bewahrung der Stimme des ursprünglichen Autors bei gleichzeitiger Sicherstellung, dass der Text in der Zielsprache flüssig läuft, erfordert sorgfältige Aufmerksamkeit.
Um diesen Prozess zu verfeinern, verwenden Bewerter Direct Assessment (DA), das Übersetzungen in einsprachigen, zweisprachigen oder referenzgestützten Formaten bewertet[9]. Die Scalar Quality Metric (SQM) geht noch einen Schritt weiter mit einer siebenstufigen Skala, die es Bewertern ermöglicht, einzelne Segmente im Kontext des gesamten Dokuments zu bewerten. Für Bücher ist dieser Kontextfokus entscheidend – Qualität hängt oft davon ab, wie gut ein Kapitel Charaktere entwickelt oder die Handlungskontinuität beibehält.
Verwendung von Metriken für Buchübersetzungen
Die Übersetzung von Büchern ist eine einzigartige Herausforderung. Im Gegensatz zu Bedienungsanleitungen oder Marketingmaterialien erfordern Bücher ein Gleichgewicht zwischen semantischer