
Best Practices für mehrsprachige EPUB-Barrierefreiheit
Die Erstellung mehrsprachiger EPUBs, die barrierefrei sind, stellt sicher, dass jeder, unabhängig von Sprache oder Behinderung, digitale Bücher genießen kann. So funktioniert es:
- Sprachen-Metadaten: Verwenden Sie
<dc:language>, um primäre und sekundäre Sprachen in Ihrem EPUB zu deklarieren. Dies hilft Bildschirmleseprogrammen und Braille-Displays, die richtigen Einstellungen zu laden. - Sprach-Markup: Fügen Sie
xml:lang-Tags in Ihrem Inhalt hinzu, um Sprachwechsel für genaue Aussprache und Text-to-Speech-Leistung zu signalisieren. - Nicht-lateinische Schriften: Betten Sie geeignete Schriftarten ein und stellen Sie Unicode-Kompatibilität sicher, um Anzeigeprobleme wie fehlende Zeichen zu vermeiden.
- Barrierefreiheitsstandards: Befolgen Sie WCAG 2.x (Level AA), EPUB 3.3 und BCP 47-Standards, um Barrierefreiheitsrichtlinien zu erfüllen.
- Test-Tools: Validieren Sie Ihr EPUB mit Tools wie EPUBCheck, Ace by DAISY und Thorium Reader, um zu bestätigen, dass Barrierefreiheitsfunktionen wie beabsichtigt funktionieren.
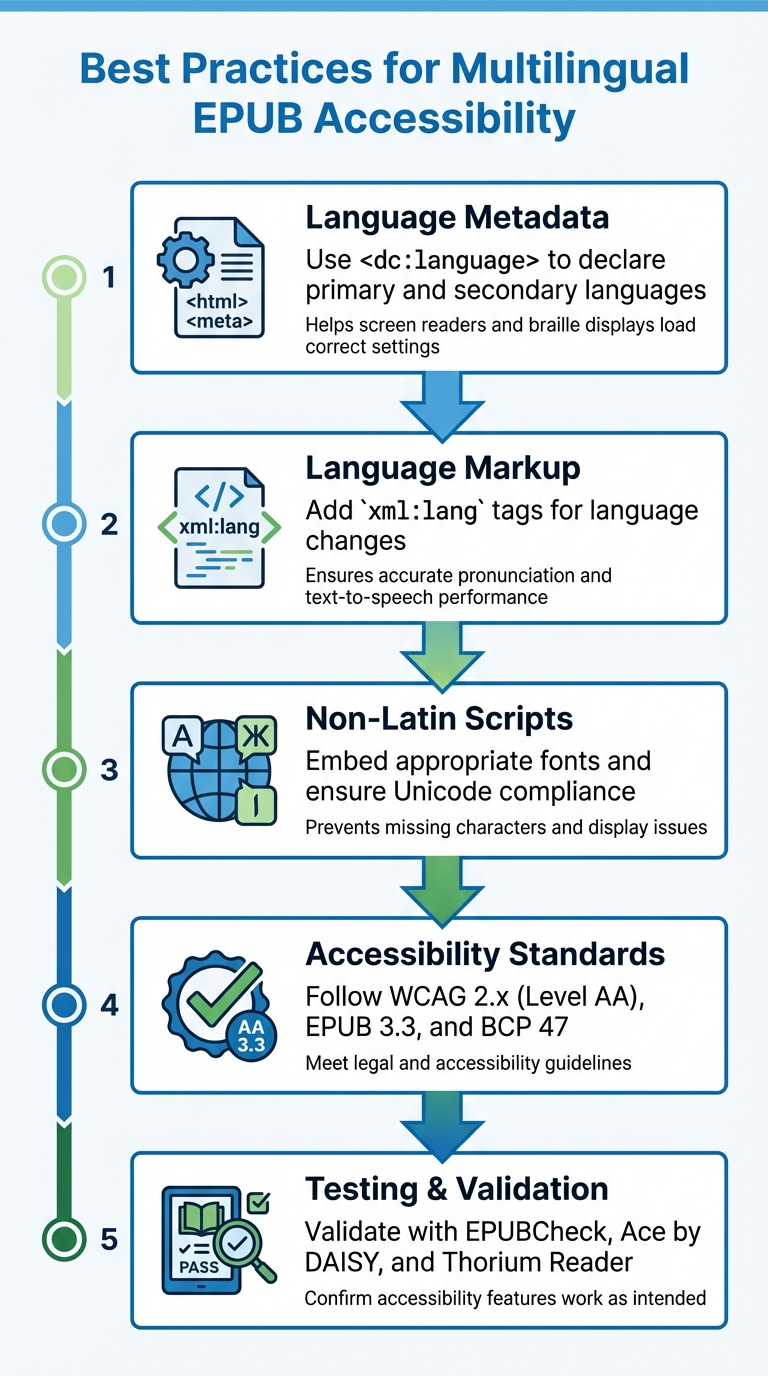
5-Schritt-Prozess zur Erstellung barrierefreier mehrsprachiger EPUBs
EPUB-Barrierefreiheit 101
sbb-itb-0c0385d
Metadaten und Sprachendeklaration
Die Einrichtung genauer Metadaten ist das Fundament für die Barrierefreiheit mehrsprachiger EPUBs. Der <metadata>-Bereich in Ihrem EPUB-Paketdokument (OPF-Datei) teilt Hilfstechnologien mit, welche Sprachen Ihr Buch enthält. Dies stellt sicher, dass Tools wie Bildschirmleseprogramme und Braille-Displays sofort die richtigen Einstellungen laden - wie Sprachsynthesizer oder Braille-Tabellen. Ohne diese Informationen könnten Hilfstechnologien auf die falsche Sprache zurückgreifen und unnötige Herausforderungen für Benutzer schaffen, die auf sie angewiesen sind. Die Deklaration von primären und sekundären Sprachen in Ihrem EPUB beginnt mit diesem Metadaten-Setup.
Primäre und sekundäre Sprachen deklarieren
Das Dublin Core-Element <dc:language> ist die bevorzugte Methode zur Identifizierung von Sprachen in Ihrem EPUB. Für mehrsprachige Bücher müssen Sie mehrere <dc:language>-Tags hinzufügen – eines für jede Sprache in Ihrem Inhalt. Listet die primäre Sprache immer zuerst auf, da Plattformen wie Google Play Books dies zur korrekten Kategorisierung Ihres Buches verwenden. Monika Zarczuk-Engelsma von der Polnischen Stiftung für Blinde und Sehbehinderte „Trakt" hebt diesen Punkt hervor:
Fügen Sie alle Buchsprachen in die EPUB-Metadaten ein.
Dies stellt sicher, dass aktualisierbare Braille-Displays automatisch zur richtigen Braille-Tabelle wechseln, was für blinde Leser essentiell ist, um Rechtschreibung und Satzzeichen in verschiedenen Sprachen korrekt zu interpretieren. Für mehrsprachige Inhalte wird EPUB 3 dringend empfohlen gegenüber EPUB 2, da die ältere Version das refines-Attribut fehlt, was zu Verwirrung führen kann, wie Hilfstechnologien Metadaten verarbeiten.
Verwenden der richtigen Sprachcodes
Um Kompatibilität mit Lesesystemen und Hilfsmitteln sicherzustellen, verwenden Sie ISO 639-1 zwei-Buchstaben-Codes (z. B. „en" für Englisch, „es" für Spanisch). Nachfolgend finden Sie eine Kurzreferenz für häufige Sprachen und ihr korrektes Metadaten-Format:
| Sprache | ISO 639-1 Code | Metadaten-Beispiel |
|---|---|---|
| Englisch | en | <dc:language>en</dc:language> |
| Spanisch | es | <dc:language>es</dc:language> |
| Französisch | fr | <dc:language>fr</dc:language> |
| Japanisch | ja | <dc:language>ja</dc:language> |
| Polnisch | pl | <dc:language>pl</dc:language> |
| Deutsch | de | <dc:language>de</dc:language> |
Konsistenz ist entscheidend. Die Sprachcodes in Ihren Metadaten sollten mit den Sprach-Tags in Ihrem HTML-Inhalt übereinstimmen, die mit dem xml:lang-Attribut definiert sind. Diese Ausrichtung ermöglicht es Bildschirmleseprogrammen, nahtlos zwischen Sprachen zu wechseln, während Benutzer durch Ihr Buch navigieren, und vermeidet Probleme wie Mispronunziationen.
Sprach-Markup in Inhaltsdokumenten
Nachdem Sie genaue Sprachen-Metadaten für ein Buch eingerichtet haben, besteht der nächste Schritt darin, präzises Sprach-Markup im Text zu gewährleisten. Dies beinhaltet das Markieren von Sprachwechseln im Inhalt mit dem xml:lang-Attribut. Warum ist das wichtig? Es hilft Bildschirmleseprogrammen und Text-to-Speech-Tools zu wissen, wann genau sie die Sprache wechseln sollen. Dies stellt sicher, dass korrekte Aussprache und ordnungsgemäße phonetische Regeln angewendet werden. Ohne dies könnte ein Bildschirmleseprogramm Wörter mispronunzieren, indem es die falschen Sprachregeln anwendet, was Verwirrung verursacht.
xml:lang für Sprachwechsel verwenden
Das xml:lang-Attribut ist essentiell zum Markieren von Sprachwechseln in EPUB 3-Inhalten. Sie können es auf Inline-Elementen wie <span> für kurze Phrasen oder auf Block-Level-Elementen wie <p> oder <div> für längere Abschnitte verwenden. Wenn Ihr englisches Buch beispielsweise ein französisches Zitat enthält, würden Sie es so markieren:
<span xml:lang="fr">Bonjour</span>
Dies signalisiert Bildschirmleseprogrammen, zu einem französischen Sprachsynthesizer zu wechseln und stellt sicher, dass aktualisierbare Braille-Displays die korrekte Braille-Tabelle verwenden.
Monika Zarczuk-Engelsma von der Polnischen Stiftung für Blinde und Sehbehinderte „Trakt" hebt seine Bedeutung hervor:
Das xml:lang-Attribut kann in einem Text verwendet werden, um Teile zu markieren, die in einer anderen Sprache geschrieben sind... Auf diese Weise können Bildschirmleseprogramme zum Sprachsynthesizer der entsprechenden Sprache wechseln.
Für Sprachen, die von rechts nach links gelesen werden, wie Arabisch oder Hebräisch, fügen Sie dir="rtl" neben xml:lang auf dem relevanten Element ein. Dies erhält ordnungsgemäße Darstellung und Lesereihenfolge. Verwenden Sie immer zwei-Buchstaben-ISO-Codes (z. B. en, es, fr), um Kompatibilität über verschiedene Bildschirmleseprogramme hinweg sicherzustellen.
Danach ist es wichtig zu entscheiden, welche Instanzen wirklich von einem Sprachwechsel profitieren, um ein reibungsloses Leseerlebnis zu erhalten.
Wann und wie Sprachen wechseln
Nicht jedes Fremdwort braucht ein Sprach-Tag. Wörter wie Eigennamen, technische Begriffe oder solche, die häufig im Englischen verwendet werden – wie „piñata" oder „Los Angeles" – werden normalerweise im Kontext verstanden und erfordern keine Ausspracheänderungen. Jedoch sollten vollständige Phrasen, Sätze oder Passagen in einer anderen Sprache immer markiert werden, um WCAG Level AA-Standards zu erfüllen.
Vermeiden Sie das Tagging kurzer Fremdwörter wie Namen, da dies unnötige und störende Sprachwechsel für Braille-Display-Benutzer verursachen kann. Wenn möglich, wenden Sie xml:lang auf Block-Level-Elemente wie <p> statt auf Inline-<span>-Tags an, da dies die Kompatibilität mit Hilfsmitteln verbessert. Für nicht-sprachliche Inhalte wie ISBNs oder Teilenummern verwenden Sie den Code zxx, um anzuzeigen, dass der Inhalt in keiner menschlichen Sprache ist.
Nicht-lateinische Schriften und Zeichensätze
Die Behandlung nicht-lateinischer Schriften ist essentiell, um genaue Anzeige und Funktionalität in digitalen Publikationen sicherzustellen. Sprachen wie Arabisch, Chinesisch, Hebräisch und Kyrillisch erfordern präzise technische Setups, um Anzeigeprobleme zu vermeiden. Fehlende Schriftarten oder falsche Sprachcodes können zu „Tofu"-Zeichen führen – diese frustrierenden weißen Quadrate oder Fragezeichen, die erscheinen, wenn Geräten die notwendigen Schriftarten fehlen. Um dies zu beheben, ist EPUB 3 oft eine Anforderung für diese Sprachen. Große Einzelhandelsketten, einschließlich Apple Books, schreiben diesen Standard für Sprachen wie Chinesisch, Japanisch, Arabisch, Hebräisch, Dari, Kurdisch, Paschtu, Punjabi, Sindhi, Tadschikisch, Uigurisch und Usbekisch vor [3]. Die native Unicode-Unterstützung von EPUB 3 ist essentiell für die genaue Darstellung dieser Schriftsysteme.
Schriftarten für nicht-lateinische Schriften einbetten
Das Einbetten von Schriftarten stellt eine konsistente Anzeige auf allen Geräten sicher. Tools wie Sigil und Calibre vereinfachen diesen Prozess. Für Sigil folgen Sie diesen Schritten:
-
Fügen Sie Ihre Schriftdatei (vorzugsweise im
.ttf-Format) zum Ordner „Fonts" hinzu. -
Deklarieren Sie die Schriftart in Ihrem CSS-Stylesheet mit der
@font-face-Regel:@font-face { src: url(../Fonts/yourfont.ttf); font-family: "YourFontName"; } -
Ersetzen Sie alle
font-family-Referenzen in Ihrem Stylesheet mit dem Namen, den Sie definiert haben.
In Calibre können Sie dies automatisieren, indem Sie das Tool „Manage fonts" verwenden und „Embed all fonts" auswählen. Für zweisprachige Publikationen fügen Sie mindestens eine lateinische Schriftart und eine nicht-lateinische Schriftart ein. Testen Sie Ihr EPUB immer in Industriestandard-Readern wie Adobe Digital Editions (Versionen 3 oder 4.5), um zu bestätigen, dass Zeichen korrekt dargestellt werden.
Es ist auch wichtig, nicht-lateinischen Text nicht in Bilder umzuwandeln. Dies macht Ihren Inhalt für Bildschirmleseprogramme unzugänglich und verhindert, dass Benutzer Text vergrößern können, was die Barrierefreiheit beeinträchtigen kann.
Eine Anmerkung zur Schriftarten-Verschleierung: Der SHA-1-Algorithmus, der derzeit für Schriftarten-Verschleierung in EPUBs verwendet wird, wird auslaufen. Nach der W3C Publishing Maintenance Working Group:
Das NIST rät dazu, die Verwendung des SHA-1-Algorithmus [fips-180-4] bis Ende 2030 auslaufen zu lassen. Die Publishing Maintenance Working Group beabsichtigt nicht, Schriftarten-Verschleierung in EPUB-Publikationen nach diesem Datum zu unterstützen, da sie sich auf SHA-1 stützt [4].
Nachdem Schriftarten eingebettet sind, besteht der nächste Schritt darin, universelle Unicode-Unterstützung sicherzustellen.
Unicode-Kompatibilität
EPUB 3 erfordert universelle Unicode-Unterstützung, um genaue Zeichendaten über alle Lesesysteme hinweg zu erhalten. Dies beseitigt die Notwendigkeit für Text-Bilder und stellt Barrierefreiheit sicher. Um diese Anforderung zu erfüllen, kodieren Sie alle XHTML- und CSS-Dateien in UTF-8.
Für von rechts nach links verlaufende Schriften wie Arabisch und Hebräisch verwenden Sie das dir-Attribut (z. B. dir="rtl"), um die Textrichtung zu steuern. Das Setzen von dir="auto" ermöglicht Lesesystemen, den Unicode-Bidirektionalen Algorithmus anzuwenden, um ordnungsgemäßen Textfluss sicherzustellen.
| Schrift/Sprache | Häufige veraltete Kodierungen | Unicode-Standard |
|---|---|---|
| Arabisch | ISO-8859-6, Windows-1256 | UTF-8 / UTF-16 |
| Kyrillisch | ISO-8859-5, Windows-1251 | UTF-8 / UTF-16 |
| Hebräisch | ISO-8859-8, Windows-1255 | UTF-8 / UTF-16 |
| Chinesisch (Vereinfacht) | GB2312, GB18030 | UTF-8 / UTF-16 |
| Chinesisch (Traditionell) | Big5 | UTF-8 / UTF-16 |
Verwenden Sie Unicode-Zeichen statt Bilder, um Barrierefreiheit und Text-Umfluss zu bewahren. Für gemischte Inhalte, wie arabische Phrasen in englischen Sätzen, nutzen Sie Unicode-Bidirektionale Steuerzeichen oder entsprechendes HTML-Markup, um ordnungsgemäße Darstellung sicherzustellen. Dieser Ansatz behält sowohl Funktionalität als auch Lesbarkeit über verschiedene Sprachen und Schriften hinweg.
Testen und Validieren mehrsprachiger EPUBs
Nach dem Einbetten von Schriftarten und der Sicherung von Unicode-Kompatibilität besteht der nächste Schritt darin, die Barrierefreiheit Ihres mehrsprachigen EPUB zu überprüfen. Dieser Prozess stellt sicher, dass Ihr Inhalt nahtlos für alle Leser funktioniert, einschließlich derjenigen, die auf Hilfstechnologien wie Bildschirmleseprogramme oder Text-to-Speech-Engines angewiesen sind. Tests helfen dabei, Barrieren zu identifizieren und zu beheben, die den Zugang einschränken könnten.
Testen von Sprach-Markup mit Validierungstools
Beginnen Sie, indem Sie EPUBCheck ausführen, den offiziellen Konformitätsprüfer für EPUB 2 und 3. Dieses Tool identifiziert strukturelle Fehler, die das Rendern stören könnten [7]. Wenn Sie eine grafische Benutzeroberfläche bevorzugen, erwägen Sie die Verwendung von Pagina EPUB-Checker für einfachere Navigation [9].
Nachdem EPUBCheck bestätigt hat, dass Ihre Datei fehlerfrei ist, fahren Sie mit Ace by DAISY fort. Dieses Tool bewertet die Barrierefreiheit basierend auf der EPUB Accessibility Specification. Simon Collinson, Content Sales Manager bei Kobo, hebt seine Bedeutung hervor:
Das wirklich Wichtige an Ace ist, dass es die Barrierefreiheit zu einem konkreten Ziel mit klaren Schritten und einer Schweregrad-Hierarchie macht [5].
Ace ist vielseitig – es kann als Desktop-Anwendung verwendet oder über seine Befehlszeilenversion in automatisierte Workflows integriert werden [5].
Um ordnungsgemäße Behandlung von Sprachwechsel und Text-to-Speech (TTS) -Leistung sicherzustellen, testen Sie Ihr EPUB mit Thorium Reader. Diese Anwendung, die auf epubtest.org eine perfekte Punktzahl für nicht-visuelles Lesen erhielt [8], ist besonders effektiv für diese Überprüfungen. Aktivieren Sie die Einstellung „Enhance Screen Reader Experience" auf der Registerkarte „General", um zu überprüfen, dass Bildschirmleseprogramme wie JAWS, NVDA oder VoiceOver korrekt zwischen Stimmen für verschiedene Sprach-Tags wechseln [6]. Testen Sie zusätzlich die Funktion „Read Aloud", um ordnungsgemäße Pausen und genaue Aussprache sicherzustellen, besonders für nicht-lateinische Schriften. Diese Schritte bestätigen, dass Ihre Sprach-Tags und Metadaten Hilfstechnologien korrekt leiten.
Nachdem diese technischen und Barrierefreiheitstests abgeschlossen sind, fahren Sie mit einer detaillierteren Überprüfung der WCAG-Konformität fort.
WCAG-Konformität prüfen
Während automatisierte Tools wie Ace by DAISY eine starke Grundlage bieten, können sie WCAG-Konformität nicht vollständig bewerten. Eine manuelle Überprüfung ist essentiell [5]. Beginnen Sie, indem Sie systematisch alle in Aces Bericht gekennzeichneten Probleme adressieren, mit Fokus auf Bereiche wie doppelte IDs, die ARIA-Attributreferenzen und Tabellenkopfzeilen stören können – beide sind entscheidend für Hilfstechnologien.
Inspizieren Sie danach visuell Ihr EPUB in Thorium Reader, um zu bestätigen, dass das Layout, die Schriftarten und die Navigation WCAG-Standards erfüllen [6][10]. Für mehrsprachige technische Dokumente achten Sie besonders auf MathML-Darstellung und Navigation, da diese für die Barrierefreiheit von EPUB 3-Publikationen entscheidend sind [8]. Beachten Sie, dass EPUBCheck Grenzen hat – es validiert CSS nicht vollständig oder erkennt JavaScript-Probleme nicht, die die Benutzerfreundlichkeit beeinträchtigen könnten [9].
BookTranslator.ai für mehrsprachige EPUBs verwenden
BookTranslator.ai vereinfacht die Übersetzung von EPUB-Dateien, während Barrierefreiheit niemals beeinträchtigt wird. Bei der Erstellung barrierefreier mehrsprachiger EPUBs ist es entscheidend, die ursprüngliche Struktur, Formatierung und Sprach-Markup zu bewahren. Diese Plattform handhabt all das nahtlos und bietet Übersetzungen in über 99 Sprachen, während Layout und Funktionen bewahrt werden, auf die Hilfstechnologien angewiesen sind.
Das Tool hält sich an BCP 47-Standards und stellt konsistente und genaue Sprach-Tagging während Übersetzungen sicher. Es verwendet präzise Codes wie en-US oder en-GB für regionale Variationen und Script-Tags wie zh-Hans und