
Kiedyś myślałeś o tym, aby wziąć fizyczną książkę z półki i zamienić ją w doskonale przetłumaczoną cyfrową kopię? To jest magia procesu OCR i tłumaczenia. Zaczyna się od optycznego rozpoznawania znaków (OCR), aby wyodrębnić tekst ze skanowanych stron, a następnie wykorzystuje maszynowe tłumaczenie, aby przenieść go do nowego języka. Ten przewodnik wykracza daleko poza proste aplikacje, przedstawiając profesjonalny przepływ pracy do obsługi książek i innej zawartości długoformułowej z precyzją, którą zasługują.
Twój nowoczesny przepływ pracy do tłumaczenia książek cyfrowych
Zamiana drukowanej książki w wypolerowany, przetłumaczony plik cyfrowy to prawdziwy projekt. To nie jest sprawa jednego kliknięcia, ale metodiczny proces zaprojektowany, aby zachować oryginalny głos autora, jednocześnie otwierając go dla całkowicie nowej publiczności. Zasadniczo budujesz most od drukowanej strony do ekranu cyfrowego, przekształcając statyczne atrament w dynamiczne, edytowalne i przeszukiwalne dane.
Sukces naprawdę sprowadza się do serii ostrożnych kroków, z których każdy przygotowuje scenę dla następnego. Pomyśl o tym jak o linii produkcyjnej dla twojej książki.
Główne etapy tłumaczenia książki
Podróż ze stosu papieru do gotowego EPUB-a lub PDF-a obejmuje kilka odrębnych faz. Ten diagram daje ci ogólny przegląd całego procesu, od zeskanowania materiału źródłowego do sformatowania ostatecznego pliku.
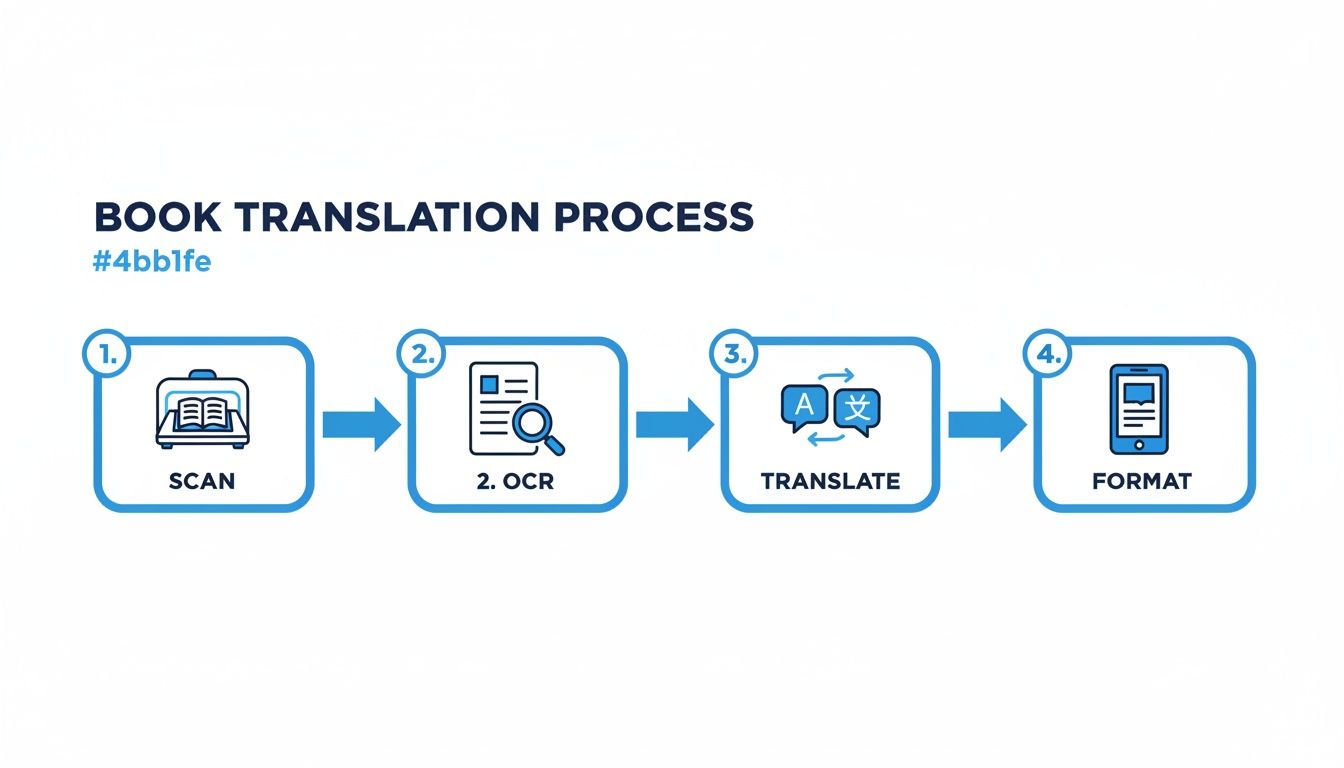
Każdy z tych etapów — Skanowanie, OCR, Tłumaczenie i Formatowanie — jest krytycznym ogniwem. Jakość, którą uzyskasz z jednego etapu, bezpośrednio determinuje jakość, którą możesz włożyć w następny.
To już nie jest umiejętność niszowa; popyt eksploduje. Globalny rynek optycznego rozpoznawania znaków osiągnął 13,95 miliarda USD w 2024 roku i ma wzrosnąć ponad 46 miliardów USD do 2033 roku, wszystko dzięki ogromnym wysiłkom na rzecz cyfryzacji na całym świecie.
Kluczowy wniosek: Dla każdego dużego projektu ustrukturyzowany przepływ pracy jest niezbędny. Jeśli pospieszy się podczas skanowania lub oszczędzać będziesz na czyszczeniu wyodrębnionego tekstu, tworzysz sobie ogromne problemy na przyszłość, szczególnie podczas tłumaczenia i formatowania.
Jako część każdego nowoczesnego, profesjonalnego przepływu pracy, ważne jest również zapewnienie integracji sztucznej inteligencji zgodnej z RODO, szczególnie gdy masz do czynienia z treścią całych książek. Ten przewodnik da ci kompletny plan projektu, aby pewnie zarządzać dużymi projektami OCR i tłumaczenia od początku do końca.
Przygotowywanie książki do bezflawowego skanowania
Cały projekt OCR i tłumaczenia zależy od jednej rzeczy: jakości początkowych skanów. Długo zanim pomyślisz o uruchomieniu oprogramowania do rozpoznawania tekstu, musisz zrobić ten pierwszy krok dobrze. Rozmyte, krzywe lub słabo oświetlone skanowanie spowoduje kaskadę błędów, pozostawiając cię z zniekształconym tekstem i koszmarem tłumaczenia.
Pomyśl o tym jak o gotowaniu. Najlepszy szef kuchni na świecie nie może przygotować wspaniałego posiłku ze zepsutymi składnikami. Twoje skany to twoje składniki.

To jest miejsce, gdzie twój skaner staje się twoim najważniejszym narzędziem. Zapomnij o używaniu aplikacji mobilnej do całej książki; nigdy nie uzyskasz spójności, której potrzebujesz. Dla projektu tej skali tylko skaner płaski daje ci kontrolę i jakość, której potrzebujesz.
Dostrojenie ustawień skanera
Prawidłowe ustawienie skanera to nie tylko sugestia — to absolutnie krytyczne dla uzyskania czystego, dokładnego tekstu. Kilka zmian tutaj może zaoszczędzić ci niezliczonych godzin bolesnych ręcznych poprawek w przyszłości.
Skanowałem setki książek, od nowoczesnych broszur do wiekownych tomów, a prawidłowe ustawienia robią ogromną różnicę. Aby ci pomóc w rozpoczęciu, oto szybki przewodnik dotyczący tego, co używać i dlaczego.
Optymalne ustawienia skanera do OCR książki
| Ustawienie | Rekomendacja dla nowoczesnych książek | Rekomendacja dla starszych/złożonych książek | Uzasadnienie |
|---|---|---|---|
| Rozdzielczość (DPI) | 300-400 DPI | 400-600 DPI | 300 to minimum dla przejrzystości. Podwyższ dla małych czcionek, wygasłego atramentu lub złożonych układów, aby uchwycić więcej szczegółów bez powiększania rozmiaru pliku. |
| Tryb koloru | Skala szarości | Skala szarości | Skala szarości lepiej oddaje niuanse tekstu niż ostry tryb czarno-biały i unika ogromnych rozmiarów plików i szumu kolorów pełnokolorowych skanów. |
| Format pliku | TIFF | TIFF | TIFF to format bezstratny. Zachowuje każdy pojedynczy piksel doskonale, zapobiegając artefaktom kompresji, które tworzą JPEG-i i mogą zniszczyć dokładność OCR. |
Te ustawienia to twój najlepszy zakład na uchwycenie ostrego tekstu. Pamiętaj, celem jest danie oprogramowaniu OCR możliwie czystych danych do pracy od samego początku.
Moja osobista zasada: Nigdy, przenigdy nie używaj JPEG-a do skanów archiwalnych. Jego kompresja „stratna" dosłownie wyrzuca dane, aby zmniejszyć rozmiar plików, tworząc rozmyte artefakty wokół liter. To skrót, który zawsze kosztuje cię więcej czasu na poprawki.
Przetwarzanie wstępne: etap czyszczenia
Po cyfryzacji stron nie jesteś jeszcze gotów do silnika OCR. Trochę przetwarzania wstępnego wyczyści surowe skany i dramatycznie zwiększy twoje wyniki. Większość przyzwoitego oprogramowania do skanowania zawiera te narzędzia, ale darmowy edytor obrazów działa równie dobrze.
Oto co zawsze sprawdzam i naprawiam:
- Deskew: To najważniejszy krok. Automatycznie wyprostowuje każdą stronę, która została zeskanowana pod lekkim kątem. Nawet mały skos 1 stopnia może zmylić oprogramowanie, więc uruchom to na każdej stronie.
- Przycinanie: Pozbądź się czarnych obramowań i jakiejkolwiek części pokrywy skanera, która znalazła się na obrazie. Chcesz, aby oprogramowanie skupiało się tylko na zawartości strony, a nie na śmieci wokół niej.
- Kontrast/Jasność: Dostroić te poziomy, aby tekst był jak najciemniejszy, a tło jak najjaśniejsze. Bądź ostrożny, aby nie zmyć litery. To ratownik dla starych książek ze żółtymi stronami lub wygasłym atramentem.
Ta ostrożna praca przygotowawcza to to, co odróżnia frustrujący projekt od udanego.
Gdy już masz wyodrębniony nienaganny tekst, możesz pomyśleć o ostatecznym formacie. Jeśli zastanawiasz się, jak zapakować swoją przetłumaczoną książkę, mamy pomocny przewodnik, który rozbija zalety i wady EPUB vs. PDF do tłumaczenia AI.
Wybór odpowiednich narzędzi OCR do czystego wyodrębniania tekstu
Mając gotowe nienaganne skany, czas przejść do serca cyfrowej konwersji: wybrania odpowiedniego silnika optycznego rozpoznawania znaków (OCR). Narzędzie, które wybierzesz teraz, bezpośrednio wpływa na jakość surowego tekstu, co z kolei stanowi podstawę całego procesu tłumaczenia. Gdy zajmujesz się całą książką, a nie tylko fragmentem, żadne oprogramowanie OCR nie wystarczy.
Generalnie patrzysz na dwie ścieżki: potężne aplikacje komputerowe lub wysoce skalowalne usługi oparte na chmurze. Każda ma swoje miejsce, a najlepszy wybór naprawdę zależy od specyfiki twojego projektu.

Ten interfejs z ABBYY FineReader pokazuje niezbędną funkcję do poważnej pracy OCR — możliwość zobaczenia oryginalnego skanowania i rozpoznanego tekstu obok siebie. To sprawia, że spotykanie i naprawianie błędów jest łatwe.
Oprogramowanie komputerowe a usługi w chmurze
Dla tych, którzy chcą pełnej, szczegółowej kontroli nad procesem, aplikacja komputerowa, taka jak ABBYY FineReader, to długoletni faworyt branży. Świetnie sobie radzi ze złożonymi układami strony, rozpoznaje ogromną listę języków i daje ci narzędzia do ręcznego rysowania pól wokół dokładnego tekstu, który chcesz przechwycić. To ratownik dla powiedzenia oprogramowaniu, aby zignorować uciążliwe nagłówki, stopki i numery stron.
Z drugiej strony masz potęgi chmury, takie jak Google Cloud Vision OCR i Amazon Textract. Te usługi są zbudowane na skalę. Zamiast wiązać własny komputer na godziny, możesz wysłać im setki, a nawet tysiące stron naraz i zapłacić tylko za to, co przetworzysz. Ich modele AI są stale udoskonalane, więc dokładność, którą uzyskasz od razu z pudełka, jest często imponująca.
Moje dwa grosze: Jeśli pracuję nad jedną książką z naprawdę dziwanym projektem, będę się trzymać narzędzia komputerowego dla tej dokładnej kontroli. Ale jeśli celem jest cyfryzacja całej półki książek ze standardowymi układami, czysty szybkość i moc przetwarzania wsadowego usługi chmury to jedyna droga.
Dostrojenie ustawień OCR dla maksymalnej dokładności
Niezależnie od tego, które narzędzie wybierzesz, nie po prostu naciśnij przycisk „Przejdź". Poświęcenie kilku minut na skonfigurowanie ustawień z góry zaoszczędzą ci świata ręcznych czyszczenia później.
Oto rzeczy, które są niezbędne:
- Ustaw język rozpoznawania: To wydaje się oczywiste, ale to najkrytyczniejszy krok. Wyraźne powiedzenie oprogramowaniu języka źródłowego (np. niemiecki, japoński, hiszpański) ładuje prawidłowe zestawy znaków i słowniki, drastycznie zmniejszając wskaźnik błędów.
- Zdefiniuj strefy rozpoznawania: Poświęć minutę na kilku przykładowych stronach rysując pola wokół głównej części tekstu. To jak trenować OCR, aby ignorować numery stron, nagłówki biegu i ozdobne obramowania, które tylko zanieczyścą ostateczny plik tekstowy.
- Włącz słowniki: Jeśli oprogramowanie ma tę funkcję, włącz ją. Pozwala narzędziu na sprawdzenie rozpoznanych słów w stosunku do znanego słownika, co pomaga mu samocorrect typowych błędów, takich jak pomylenie „rn" z „m".
Ta początkowa konfiguracja to twoja pierwsza linia obrony przed brudnym, pełnym błędów plikiem tekstowym.
Wiele z najlepszych rozwiązań OCR i tłumaczenia jest teraz napędzanych zaawansowaną sztuczną inteligencją; warto sprawdzić różne narzędzia AI dla twórców zawartości, aby zobaczyć, co innego może uzupełnić twój przepływ pracy. Ten nacisk na inteligentniejszą technologię jest ogromnym czynnikiem rosnącego rynku usług tłumaczeniowych, który wyceniony był na 26,7 miliarda dolarów w 2024 roku i ma osiągnąć 34,24 miliarda dolarów do 2029 roku. Szybki wzrost pokazuje po prostu, ile popytu jest na wysokiej jakości, efektywną lokalizację na całym świecie.
Tłumaczenie treści bez utraty głosu autora
Uzyskanie czystego tekstu z procesu OCR to ogromny krok, ale teraz przychodzi prawdziwe wyzwanie: tłumaczenie. Jeśli po prostu wrzucisz tekst do standardowego narzędzia tłumaczeniowego, otrzymasz słowa, ale dusza autora będzie poza tym. Wynik jest często technicznie poprawny, ale emocjonalnie płaski, pozbawiony osobowości, która sprawiła, że książka była fascynująca.
Celem nie jest po prostu zamiana słów z jednego języka na drugi. Chodzi o wierny transfer znaczenia, stylu i tonu. Najlepszym sposobem na to jest hybrydowe podejście — takie, które łączy surową moc AI z niezastąpioną subtelnością ekspertów.
Łączenie szybkości AI z ludzkim wglądem
Nowoczesne platformy tłumaczeniowe, takie jak DeepL, całkowicie zmieniły grę. Są niezwykle dobre w rozumieniu kontekstu i struktury zdania, tworząc tłumaczenia, które czują się o wiele bardziej naturalne niż niezgrabne, dosłowne wyniki starszych systemów. To daje ci fantastyczny pierwszy projekt, często załatwiając w minutach to, co zajęłoby człowiekowi tłumaczowi tygodnie.
Ale dla całej swojej zaawansowania, AI nadal potyka się o subtelności. Nie do końca rozumie idiomatyczne wyrażenia, kulturalne wewnętrzne żarty lub unikalne cechy stylistyczne, które definiują głos autora. Zabawny zwrot frazy w języku hiszpańskim, na przykład, może łatwo stać się sztywny i zbyt formalny w angielszczyźnie, jeśli tłumaczony dosłownie.
To dokładnie dlatego ostateczna ocena człowieka jest absolutnie niezbędna dla wysokiej jakości wyniku. Idealny przepływ pracy to partnerstwo:
- Uzyskaj pierwszy projekt AI: Zacznij od uruchomienia czystego, wyodrębnionego tekstu OCR przez najwyższej klasy silnik tłumaczenia maszynowego.
- Sprowadź eksperta człowieka: Płynnie mówiący osoba następnie ostrożnie czyta przetłumaczony tekst, porównując go z oryginałem, aby złapać to, co maszyna przegapiła.
- Udoskonalić i wypolerować: Recenzent wygładza niezgrabne zwroty, poprawia błędy kulturowe tłumaczenia i dostrajnia ton, aż idealnie pasuje do intencji autora.
Ten jeden-dwa punch daje ci niesamowitą wydajność AI bez poświęcania serca oryginalnej pracy. Faktycznie zagłębiamy się znacznie głębiej w ten temat w naszym artykule o AI versus tłumaczach ludzi i zachowaniu stylu literackiego.
Korzystanie ze słowników i przewodników stylu dla spójności
Gdy pracujesz nad projektem tak dużym jak książka, spójność jest wszystkim. Nic nie wyciąga czytelnika z historii szybciej niż zobaczenie imienia głównego bohatera lub fikcyjnego miasta napisanego inaczej z rozdziału na rozdział. Po prostu wygląda na niedbałe.
Na szczęście nowoczesne narzędzia CAT (Computer-Assisted Translation) dają ci sposób na egzekwowanie spójności. Pozwalają ci budować zasoby specyficzne dla projektu, które kierują całym tłumaczeniem, niezależnie od tego, czy pracuje AI czy człowiek.
- Słowniki tłumaczeniowe: Pomyśl o tym jako o niestandardowym słowniku dla twojej książki. Możesz zdefiniować dokładnie, jak kluczowe terminy, imiona postaci i określone frazy muszą być tłumaczone za każdym razem, gdy się pojawiają.
- Przewodniki stylu: To jest miejsce, gdzie ustanawiasz prawo dotyczące tonu i formalności. Czy proza powinna być rozmowna czy akademicka? Czy są określone frazy, których chcesz uniknąć? Przewodnik stylu zapewnia, że książka czyta się jak spójna całość, a nie zbiór rozłącznych rozdziałów.
Budując prosty słownik, egzekwujesz spójność i dramatycznie zmniejszasz czas spędzony na ręcznych poprawkach. Zapewnia, że „El Bosque de las Sombras" jest zawsze tłumaczony jako „The Forest of Shadows", a nigdy „The Woods of Shade".
Silnik napędzający wszystko to, tłumaczenie maszynowe (MT), to dziedzina, która rośnie niesamowicie szybko. Wyceniony na 1,12 miliarda USD w 2025 roku, rynek ma prawie podwoić się do 2 miliardów USD do 2030 roku. Ten boom jest napędzany neuronowym tłumaczeniem maszynowym (NMT), które utrzymuje dominujący 48,67% udział w rynku dzięki jego wyższej dokładności. Jak widać z wzrostu technologii MT z Global Growth Insights, ta technologia sprawia, że zaawansowane przepływy pracy ocr i translate są potężniejsze niż kiedykolwiek. Przyjęcie tego mądrego, hybrydowego podejścia to twój najlepszy zakład na stworzenie ostatecznego produktu, który naprawdę honoruje oryginalną pracę.
Złożenie wszystkiego z powrotem: tworzenie ostatecznej cyfrowej książki
Dotarłeś. Skanowanie, czyszczenie OCR i ostrożne tłumaczenie są gotowe. Teraz masz czysty, przetłumaczony rękopis i czas na najwzruszającą część procesu: przebudowę go w wypolerowaną, profesjonalną cyfrową książkę.
To jest miejsce, gdzie cała ta drobiazgowa praca przygotowawcza się opłaca. Zasadniczo jesteś cyfrowym składaczem, biorąc surowy tekst i przekształcając go w elegancki EPUB lub czysty PDF, który czytelnicy będą kochać. To ostateczne złożenie to to, co podnosi prosty plik tekstowy do naprawdę wysokiej jakości doświadczenia czytania.
Od zwykłego tekstu do ustrukturyzowanej e-książki
Najpierw rzeczy pierwsze, musisz wnieść przetłumaczony tekst do narzędzia do tworzenia e-booków. Do tworzenia reflowable EPUB-ów — standardu dla większości czytników e-książek, takich jak Kindle i Kobo — nie możesz się mylić z potężnymi, bezpłatnymi opcjami, takimi jak Calibre lub Sigil. Jeśli twój projekt wymaga stałego układu, który naśladuje drukowaną książkę, wówczas Adobe InDesign jest standardowym narzędziem branżowym do tego zadania.
Mając zaimportowany tekst, zaczyna się prawdziwa rzemiosło. To nie jest prosta praca kopiuj-wklej; metodycznie przebudowujesz architekturę książki, aby zapewnić czytanie i nawigację.
- Podziały rozdziałów: Musisz wstawić czyste podziały, aby poprowadzić czytelnika przez narrację.
- Nagłówki i podtytułu: Zastosowanie prawidłowych tagów H1, H2 i H3 tworzy logiczną hierarchię i funkcjonalną tabelę zawartości.
- Styl tekstu: Czas przywrócić intencję oryginalnego autora, przywracając kursywę, tekst pogrubiony i wszelkie charakterystyczne cytaty blokowe.
- Umieszczanie obrazów: Ostrożnie ponownie zintegruj oryginalne ilustracje, wykresy lub diagramy w przepływ tekstu.

Narzędzia takie jak Calibre dają ci niesamowitą ilość kontroli, pozwalając ci na dostrojenie wszystkiego od obrazu okładki i metadanych do leżącego u podstaw CSS, które dyktuje wygląd książki. Aby uzyskać głębokie zanurzenie, sprawdź nasz przewodnik dotyczący najlepszych narzędzi do formatowania przyjaznego dla tłumaczenia.
Ostateczna kontrola jakości: walidacja i wypolerowanie
Zanim otworzysz szampana, jest jeszcze jeden ostatni, kluczowy krok: dokładna kontrola jakości (QA). E-book może wyglądać bezbłędnie na komputerze stacjonarnym, ale rozpada się na rzeczywistym czytniku e-książek. Ten ostateczny przebieg zapewnia, że każdy czytelnik otrzyma spójne, profesjonalne doświadczenie, niezależnie od urządzenia.
Rada z doświadczenia: Nawet nie myśl o pominięciu tego. Jeden zepsuty obraz lub pominięty podział rozdziału może całkowicie wyciągnąć czytelnika z historii i podważyć całą twoją ciężką pracę.
Oto jak powinna wyglądać ostateczna lista kontrolna QA:
- Pełny przebieg czytania formatowania: Przejdź przez całą e-książkę z grzebieniem, szukając tylko problemów z formatowaniem. Czy wszystkie nagłówki są spójne? Czy wcięcia akapitów wyglądają dobrze? Czy obrazy są prawidłowo wyrównane i nie przełamują się na stronach?
- Testuj na wielu urządzeniach: To jest niezbędne. Załaduj plik na jak wiele urządzeń i aplikacji, ile możesz. Kindle, Kobo, Apple Books, Google Play Books — zobacz, jak wygląda na wszystkich z nich. Reflowable EPUB-y mogą renderować zaskakująco inaczej z jednej platformy na drugą.
- Uruch