
Najlepsze praktyki dostępności wielojęzycznych EPUB-ów
Tworzenie wielojęzycznych EPUB-ów, które są dostępne, zapewnia, że każdy, niezależnie od języka lub niepełnosprawności, może cieszyć się książkami cyfrowymi. Oto jak to zrobić:
- Metadane języka: Użyj
<dc:language>do deklarowania języków podstawowych i dodatkowych w swoim EPUB-ie. Pomaga to czytanikom ekranu i wyświetlaczom brajlowskim załadować prawidłowe ustawienia. - Znaczniki języka: Dodaj znaczniki
xml:langw swojej zawartości, aby zasygnalizować zmiany języka dla dokładnej wymowy i wydajności zamiany tekstu na mowę. - Skrypty spoza łaciny: Osadź odpowiednie czcionki i zapewnij zgodność Unicode, aby uniknąć problemów z wyświetlaniem, takich jak brakujące znaki.
- Standardy dostępności: Postępuj zgodnie ze standardami WCAG 2.x (Poziom AA), EPUB 3.3 i BCP 47, aby spełnić wytyczne dostępności.
- Narzędzia testowania: Zweryfikuj swój EPUB za pomocą narzędzi takich jak EPUBCheck, Ace by DAISY i Thorium Reader, aby potwierdzić, że funkcje dostępności działają zgodnie z przeznaczeniem.
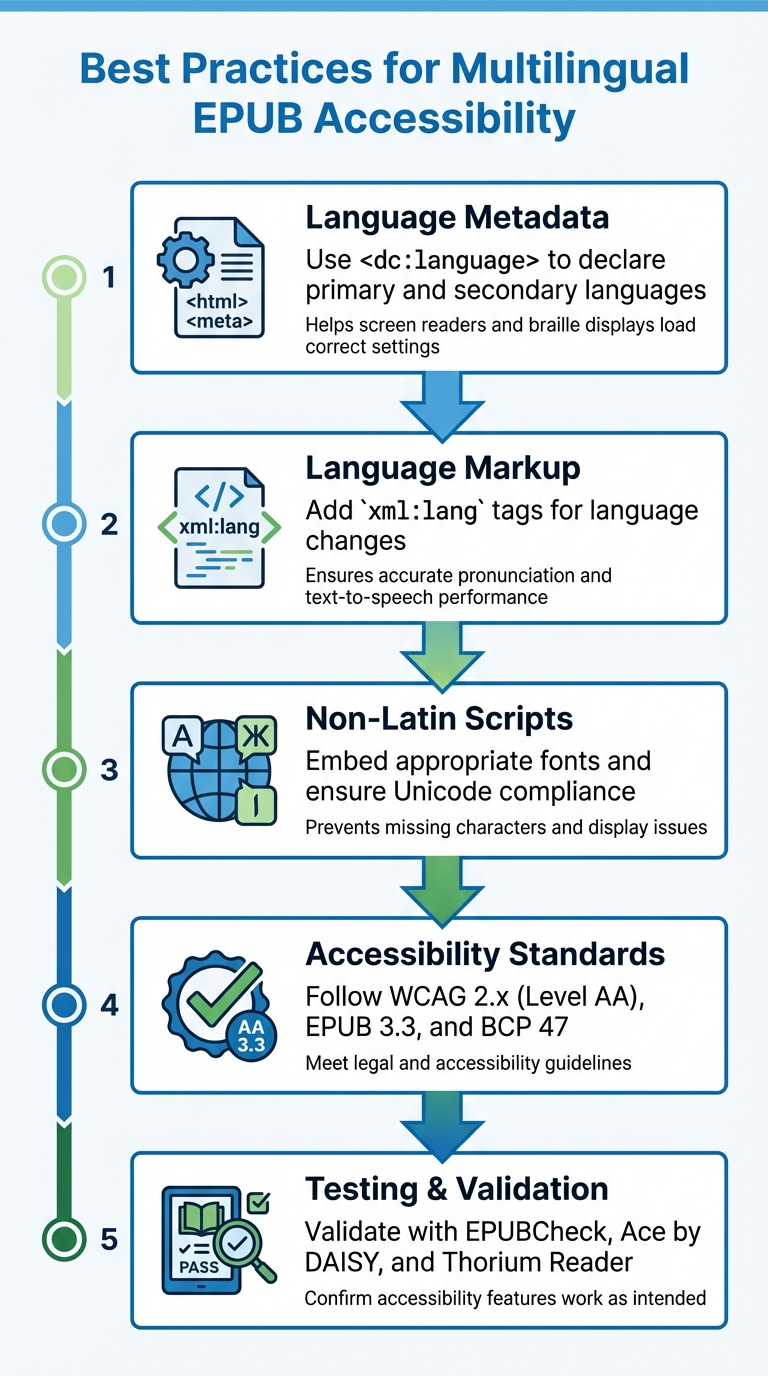
5-krokowy proces tworzenia dostępnych wielojęzycznych EPUB-ów
Dostępność EPUB-ów 101
sbb-itb-0c0385d
Metadane i deklaracja języka
Konfiguracja dokładnych metadanych jest podstawą dostępności wielojęzycznych EPUB-ów. Sekcja <metadata> w dokumencie pakietu EPUB (pliku OPF) komunikuje technologiom wspomagającym, jakie języki zawiera Twoja książka. Zapewnia to, że narzędzia takie jak czytniki ekranu i wyświetlacze brajlowskie załadują prawidłowe ustawienia - takie jak syntezatory mowy lub tabele brajlowskie - od razu. Bez tych informacji technologie wspomagające mogą domyślnie przełączyć się na zły język, tworząc niepotrzebne problemy dla użytkowników, którzy od nich zależą. Deklarowanie języków podstawowych i dodatkowych w EPUB-ie rozpoczyna się od tej konfiguracji metadanych.
Jak deklarować języki podstawowe i dodatkowe
Element Dublin Core <dc:language> jest preferowaną metodą identyfikowania języków w EPUB-ie. W przypadku książek wielojęzycznych musisz dodać wiele znaczników <dc:language> - po jednym dla każdego języka w Twojej zawartości. Zawsze wymień język podstawowy jako pierwszy, ponieważ platformy takie jak Google Play Books używają go do prawidłowej kategoryzacji Twojej książki. Monika Zarczuk-Engelsma z Polskiej Fundacji Niewidomych i Niedowidzących „Trakt" podkreśla ten punkt:
Uwzględnij wszystkie języki książki w metadanych EPUB-u.
Dzięki temu wyświetlacze brajlowskie mogą automatycznie dostosować się do prawidłowej tabeli brajlowskiej, co jest niezbędne dla niewidomych czytelników, aby dokładnie interpretować pisownię i interpunkcję w różnych językach. W przypadku zawartości wielojęzycznej EPUB 3 jest wysoce zalecany zamiast EPUB 2, ponieważ starsza wersja nie posiada atrybutu refines, co może prowadzić do zamieszania w sposobie przetwarzania metadanych przez technologie wspomagające.
Używanie prawidłowych kodów języków
Aby zapewnić zgodność z systemami odczytu i narzędziami wspomagającymi, używaj kodów ISO 639-1 (dwuliterowych kodów, np. „en" dla angielskiego, „es" dla hiszpańskiego). Poniżej znajduje się krótkie odniesienie dla popularnych języków i prawidłowego formatu metadanych:
| Język | Kod ISO 639-1 | Przykład metadanych |
|---|---|---|
| Angielski | en | <dc:language>en</dc:language> |
| Hiszpański | es | <dc:language>es</dc:language> |
| Francuski | fr | <dc:language>fr</dc:language> |
| Japoński | ja | <dc:language>ja</dc:language> |
| Polski | pl | <dc:language>pl</dc:language> |
| Niemiecki | de | <dc:language>de</dc:language> |
Konsekwencja jest kluczowa. Kody języków w Twoich metadanych powinny odpowiadać znacznikom języka w Twojej zawartości HTML, które są definiowane za pomocą atrybutu xml:lang. To wyrównanie pozwala czytanikom ekranu bezproblemowo przełączać języki, gdy użytkownicy poruszają się po Twojej książce, unikając problemów takich jak błędna wymowa.
Znaczniki języka w dokumentach zawartości
Po skonfigurowaniu dokładnych metadanych języka dla książki następnym krokiem jest zapewnienie precyzyjnego znacznika języka w tekście. Obejmuje to oznaczenie zmian języka w zawartości za pomocą atrybutu xml:lang. Dlaczego jest to ważne? Pomaga to czytanikom ekranu i narzędziom zamiany tekstu na mowę dokładnie wiedzieć, kiedy przełączyć języki. Zapewnia to prawidłową wymowę i zastosowanie prawidłowych reguł fonetycznych. Bez tego czytnik ekranu może błędnie wymówić słowa, stosując zasady niewłaściwego języka, co powoduje zamieszanie.
Używanie xml:lang do przełączania języków
Atrybut xml:lang jest niezbędny do oznaczenia zmian języka w zawartości EPUB 3. Możesz go używać na elementach wbudowanych, takich jak <span> dla krótkich fraz, lub na elementach na poziomie bloku, takich jak <p> lub <div> dla dłuższych sekcji. Na przykład, jeśli Twoja angielska książka zawiera cytat francuski, oznaczysz go w taki sposób:
<span xml:lang="fr">Bonjour</span>
To sygnalizuje czytanikom ekranu przełączenie się na francuski syntezator mowy i zapewnia, że wyświetlacze brajlowskie używają prawidłowej tabeli brajlowskiej.
Monika Zarczuk-Engelsma z Polskiej Fundacji Niewidomych i Niedowidzących „Trakt" podkreśla jego znaczenie:
Atrybut xml:lang można użyć w tekście do oznaczenia części napisanych w innym języku... W ten sposób czytniki ekranu mogą przełączyć się na syntezator mowy odpowiadający danemu językowi.
W przypadku języków czytanych od prawej do lewej, takich jak arabski lub hebrajski, dołącz dir="rtl" obok xml:lang na odpowiednim elemencie. To zachowuje prawidłowe renderowanie i kolejność odczytu. Zawsze używaj dwuliterowych kodów ISO (np. en, es, fr), aby zapewnić kompatybilność z różnymi czytnikami ekranu.
Następnie ważne jest zdecydowanie, które instancje naprawdę korzystają z przełączenia języka, aby zachować płynne doświadczenie czytania.
Kiedy i jak przełączać języki
Nie każde słowo obcojęzyczne wymaga znacznika języka. Słowa takie jak nazwy własne, terminy techniczne lub te powszechnie używane w angielskim - takie jak „piñata" lub „Los Angeles" - są zwykle rozumiane w kontekście i nie wymagają zmian wymowy. Jednak pełne frazy, zdania lub fragmenty w innym języku powinny być zawsze oznaczone, aby spełnić standardy WCAG Poziom AA.
Unikaj oznaczania krótkich słów obcojęzycznych, takich jak nazwy, ponieważ może to spowodować niepotrzebne i uciążliwe przełączenia języka dla użytkowników wyświetlaczy brajlowskich. Jeśli to możliwe, zastosuj xml:lang do elementów na poziomie bloku, takich jak <p>, zamiast wbudowanych znaczników <span>, ponieważ poprawia to kompatybilność z narzędziami wspomagającymi. W przypadku zawartości nielingwistycznej, takiej jak numery ISBN lub numery części, użyj kodu zxx, aby wskazać, że zawartość nie jest w żadnym języku ludzkim.
Skrypty spoza łaciny i zestawy znaków
Obsługa skryptów spoza łaciny jest niezbędna, aby zapewnić dokładne wyświetlanie i funkcjonalność publikacji cyfrowych. Języki takie jak arabski, chiński, hebrajski i cyrylica wymagają precyzyjnych konfiguracji technicznych, aby uniknąć problemów z wyświetlaniem. Brakujące czcionki lub nieprawidłowe kody języków mogą prowadzić do znaków „tofu" - tych frustrujących białych kwadratów lub znaków zapytania, które pojawiają się, gdy urządzeniom brakuje niezbędnych czcionek. Aby to rozwiązać, EPUB 3 jest często wymagany dla tych języków. Główne sprzedawcy, w tym Apple Books, nakazują ten standard dla języków takich jak chiński, japoński, arabski, hebrajski, dari, kurdyjski, paszto, pendżabski, sindhi, tadżycki, ujgurski i uzbecki [3]. Natywna obsługa Unicode w EPUB 3 jest niezbędna do prawidłowego prezentowania tych systemów pisma.
Osadzanie czcionek dla skryptów spoza łaciny
Osadzanie czcionek zapewnia spójne wyświetlanie na urządzeniach. Narzędzia takie jak Sigil i Calibre upraszczają ten proces. Dla Sigil wykonaj następujące kroki:
-
Dodaj plik czcionki (najlepiej w formacie
.ttf) do folderu „Fonts". -
Zadeklaruj czcionkę w arkuszu stylów CSS za pomocą reguły
@font-face:@font-face { src: url(../Fonts/yourfont.ttf); font-family: "YourFontName"; } -
Zastąp wszystkie odniesienia
font-familyw arkuszu stylów nazwą, którą zdefiniowałeś.
W Calibre możesz zautomatyzować to za pomocą narzędzia „Manage fonts" i wybrania opcji „Embed all fonts". W przypadku publikacji dwujęzycznych uwzględnij co najmniej jedną czcionkę łacińską i jedną czcionkę spoza łaciny. Zawsze testuj swój EPUB w standardowych czytnikach branżowych, takich jak Adobe Digital Editions (wersje 3 lub 4.5), aby potwierdzić, że znaki są renderowane prawidłowo.
Ważne jest również unikanie konwertowania tekstu spoza łaciny na obrazy. Zrobienie tego powoduje, że Twoja zawartość jest niedostępna dla czytników ekranu i uniemożliwia użytkownikom zmianę rozmiaru tekstu, co może utrudnić dostępność.
Uwaga na temat zaciemniania czcionek: Algorytm SHA-1, obecnie używany do zaciemniania czcionek w EPUB-ach, jest wycofywany. Zgodnie z grupą roboczą W3C Publishing Maintenance:
NIST zaleca wycofanie użycia algorytmu SHA-1 [fips-180-4] do końca 2030 roku. Grupa robocza Publishing Maintenance nie zamierza wspierać zaciemniania czcionek w publikacjach EPUB po tej dacie ze względu na zależność od SHA-1 [4].
Po osadzeniu czcionek następnym krokiem jest zapewnienie uniwersalnej obsługi Unicode.
Zgodność z Unicode
EPUB 3 wymaga uniwersalnej obsługi Unicode, aby zachować dokładne dane znakowe we wszystkich systemach odczytu. To eliminuje potrzebę obrazów tekstowych i zapewnia dostępność. Aby spełnić to wymaganie, zakoduj wszystkie pliki XHTML i CSS w UTF-8.
W przypadku skryptów czytanych od prawej do lewej, takich jak arabski i hebrajski, użyj atrybutu dir (np. dir="rtl") do kontrolowania kierunku tekstu. Ustawienie dir="auto" pozwala systemom odczytu zastosować algorytm dwukierunkowy Unicode, zapewniając prawidłowy przepływ tekstu.
| Skrypt/Język | Powszechne starsze kodowania | Standard Unicode |
|---|---|---|
| Arabski | ISO-8859-6, Windows-1256 | UTF-8 / UTF-16 |
| Cyrylica | ISO-8859-5, Windows-1251 | UTF-8 / UTF-16 |
| Hebrajski | ISO-8859-8, Windows-1255 | UTF-8 / UTF-16 |
| Chiński (uproszczony) | GB2312, GB18030 | UTF-8 / UTF-16 |
| Chiński (tradycyjny) | Big5 | UTF-8 / UTF-16 |
Używaj znaków Unicode zamiast obrazów, aby zachować dostępność i możliwość reflow tekstu. W przypadku zawartości o mieszanym kierunku, takiej jak frazy arabskie w zdaniach angielskich, wykorzystaj znaki sterujące dwukierunkowości Unicode lub odpowiednie znaczniki HTML, aby zapewnić prawidłowe renderowanie. To podejście zachowuje zarówno funkcjonalność, jak i czytelność w różnych językach i skryptach.
Testowanie i walidacja wielojęzycznych EPUB-ów
Po osadzeniu czcionek i zapewnieniu zgodności Unicode następnym krokiem jest weryfikacja dostępności wielojęzycznego EPUB-u. Ten proces zapewnia, że Twoja zawartość działa bezproblemowo dla wszystkich czytelników, w tym tych korzystających z technologii wspomagających, takich jak czytniki ekranu lub silniki zamiany tekstu na mowę. Testowanie pomaga zidentyfikować i naprawić wszelkie bariery, które mogą ograniczyć dostęp.
Testowanie znaczników języka za pomocą narzędzi walidacji
Zacznij od uruchomienia EPUBCheck, oficjalnego narzędzia do sprawdzania zgodności EPUB 2 i 3. To narzędzie identyfikuje błędy strukturalne, które mogą zakłócić renderowanie [7]. Jeśli wolisz interfejs graficzny, rozważ użycie Pagina EPUB-Checker dla łatwiejszej nawigacji [9].
Po potwierdzeniu przez EPUBCheck, że plik jest wolny od błędów, przejdź do Ace by DAISY. To narzędzie ocenia dostępność na podstawie specyfikacji dostępności EPUB. Simon Collinson, Content Sales Manager w Kobo, podkreśla jego znaczenie:
Naprawdę ważną rzeczą w Ace jest to, że czyni dostępność konkretnym celem z jasnymi krokami i hierarchią ważności [5].
Ace jest uniwersalne - można go używać jako aplikacji desktopowej lub integrować z zautomatyzowanymi przepływami pracy za pośrednictwem jego wersji wiersza poleceń [5].
Aby zapewnić prawidłową obsługę przełączania języka i wydajność zamiany tekstu na mowę (TTS), testuj swój EPUB za pomocą Thorium Reader. Ta aplikacja, która uzyskała doskonałą ocenę dla czytania bez wizualnego na epubtest.org [8], jest szczególnie efektywna dla tych kontroli. Włącz ustawienie „Enhance Screen Reader Experience" na karcie General, aby zweryfikować, że czytniki ekranu, takie jak JAWS, NVDA lub VoiceOver, prawidłowo przełączają głosy dla różnych znaczników języka [6]. Dodatkowo testuj funkcję „Read Aloud", aby zapewnić prawidłowe pauzy i dokładną wymowę, zwłaszcza w przypadku skryptów spoza łaciny. Te kroki potwierdzają, że znaczniki języka i metadane prawidłowo kierują technologie wspomagające.
Po zakończeniu tych testów technicznych i testów dostępności przejdź do bardziej szczegółowego przeglądu zgodności z WCAG.
Sprawdzanie zgodności z WCAG
Chociaż narzędzia zautomatyzowane, takie jak Ace by DAISY, stanowią solidną podstawę, nie mogą w pełni ocenić zgodności z WCAG. Przegląd ręczny jest niezbędny [5]. Zacznij od systematycznego rozwiązywania wszelkich problemów zasygnalizowanych w raporcie Ace, skupiając się na obszarach takich jak zduplikowane identyfikatory, które mogą zakłócić odniesienia atrybutów ARIA i nagłówki tabel - obie krytyczne dla technologii wspomagającej.
Następnie wizualnie sprawdź swój EPUB w Thorium Reader, aby potwierdzić, że układ, czcionki i nawigacja spełniają standardy WCAG [6][10]. W przypadku wielojęzycznych dokumentów technicznych zwróć szczególną uwagę na renderowanie i nawigację MathML, ponieważ są one kluczowe dla dostępności publikacji EPUB 3 [8]. Pamiętaj, że EPUBCheck ma swoje ograniczenia - nie będzie w pełni walidować CSS ani nie wykryje problemów z JavaScriptem, które mogą wpłynąć na użyteczność [9].
Używanie BookTranslator.ai dla wielojęzycznych EPUB-ów
BookTranslator.ai upraszcza tłumaczenie plików EPUB, zapewniając, że dostępność nigdy nie jest zagrożona. Podczas tworzenia dostępnych wielojęzycznych EPUB-ów kluczowe jest zachowanie oryginalnej struktury, formatowania i znaczników języka. Ta platforma obsługuje to wszystko bezproblemowo, oferując tłumaczenia w ponad 99 językach, zachowując jednocześnie układ i funkcje, od których zależy dostępność technologii wspomagających.
Narzędzie przestrzega standardów BCP 47, zapewniając spójne i dokładne tagowanie języka w całych tłumaczeniach. Używa precyzyjnych kodów, takich jak en-US lub en-GB dla wariantów regionalnych i znaczników skryptów, takich jak zh-Hans i zh-Hant dla różnych systemów pisma. Dlaczego to ważne? Prawidłowe tagowanie języka zapewnia, że technologie wspomagające mogą bezproblemowo przełączać języki i prawidłowo wymawniać tekst. Jak wyjaśnia Konsorcjum DAISY:
„Ustawienie języka zapewnia, że technologie wspomagające prawidłowo interpretują i renderują tekst oraz że systemy odczytu mogą udostępniać ulepszenia języka dla użytkowników