
Metryki dokładności tłumaczenia: wyjaśnienie
Metryki dokładności tłumaczenia pomagają ocenić, jak dobrze tłumaczenia maszynowe odpowiadają referencjom utworzonym przez człowieka. Narzędzia te są kluczowe dla oceny jakości tłumaczenia, zwłaszcza podczas pracy z projektami na dużą skalę lub treściami o wysokiej stawce. Metryki dzielą się na trzy kategorie:
- Metryki oparte na ciągach znaków: BLEU, METEOR i TER skupiają się na nakładaniu się słów lub znaków.
- Metryki oparte na sieciach neuronowych: COMET i BERTScore analizują podobieństwo semantyczne za pomocą modeli AI.
- Oceny człowieka: Bezpośrednie oceny, takie jak MQM, skupiają się na adekwatności i płynności.
Kluczowe wnioski:
- BLEU: Szybki i prosty, ale ma trudności z synonimami i głębszym znaczeniem.
- METEOR: Uwzględnia synonimy i niuanse lingwistyczne; lepszy dla dzieł literackich.
- TER: Mierzy nakład pracy redakcyjnej, ale ignoruje jakość semantyczną.
- COMET i BERTScore: Zaawansowane modele AI, które dobrze pokrywają się z oceną człowieka, świetne dla tekstów o niuansach.
W przypadku tłumaczeń książek połączenie zautomatyzowanych narzędzi z oceną człowieka zapewnia dokładność i zachowuje oryginalny styl. Platformy takie jak BookTranslator.ai stosują to hybrydowe podejście, aby dostarczać niezawodne wyniki w ponad 99 językach.
Popularne metryki dokładności tłumaczenia
BLEU Score
Wprowadzony w 2002 roku, BLEU (Bilingual Evaluation Understudy) pozostaje popularną metryką oceny tłumaczenia maszynowego [4]. Działa poprzez porównanie precyzji n-gramów, co oznacza analizę, w jaki sposób sekwencje słów w wyniku maszyny są wyrównane z tłumaczeniami referencyjnymi. Wyniki BLEU wahają się od 0 do 1, gdzie wyższe liczby sygnalizują lepszą jakość. Jego największą siłą? Szybkość i prostota - BLEU może przetwarzać tysiące tłumaczeń szybko, co czyni go wysoce praktycznym. Ta wydajność sprawiła, że otrzymał nagrodę NAACL 2018 Test-of-Time.
Jak wyjaśnili Papineni i współautorzy: „Główną ideą jest użycie średniej ważonej dopasowań n-gramów o zmiennej długości między tłumaczeniem systemu a zestawem tłumaczeń referencyjnych człowieka" [4].
Jednak BLEU ma zauważalne ograniczenie: priorytetyzuje dokładne dopasowania słów. Oznacza to, że może niedoceniać tłumaczenia, które przekazują to samo znaczenie, ale używają innego sformułowania. Aby to rozwiązać, metryki takie jak METEOR mają na celu uchwycenie niuansów lingwistycznych.
METEOR Metric
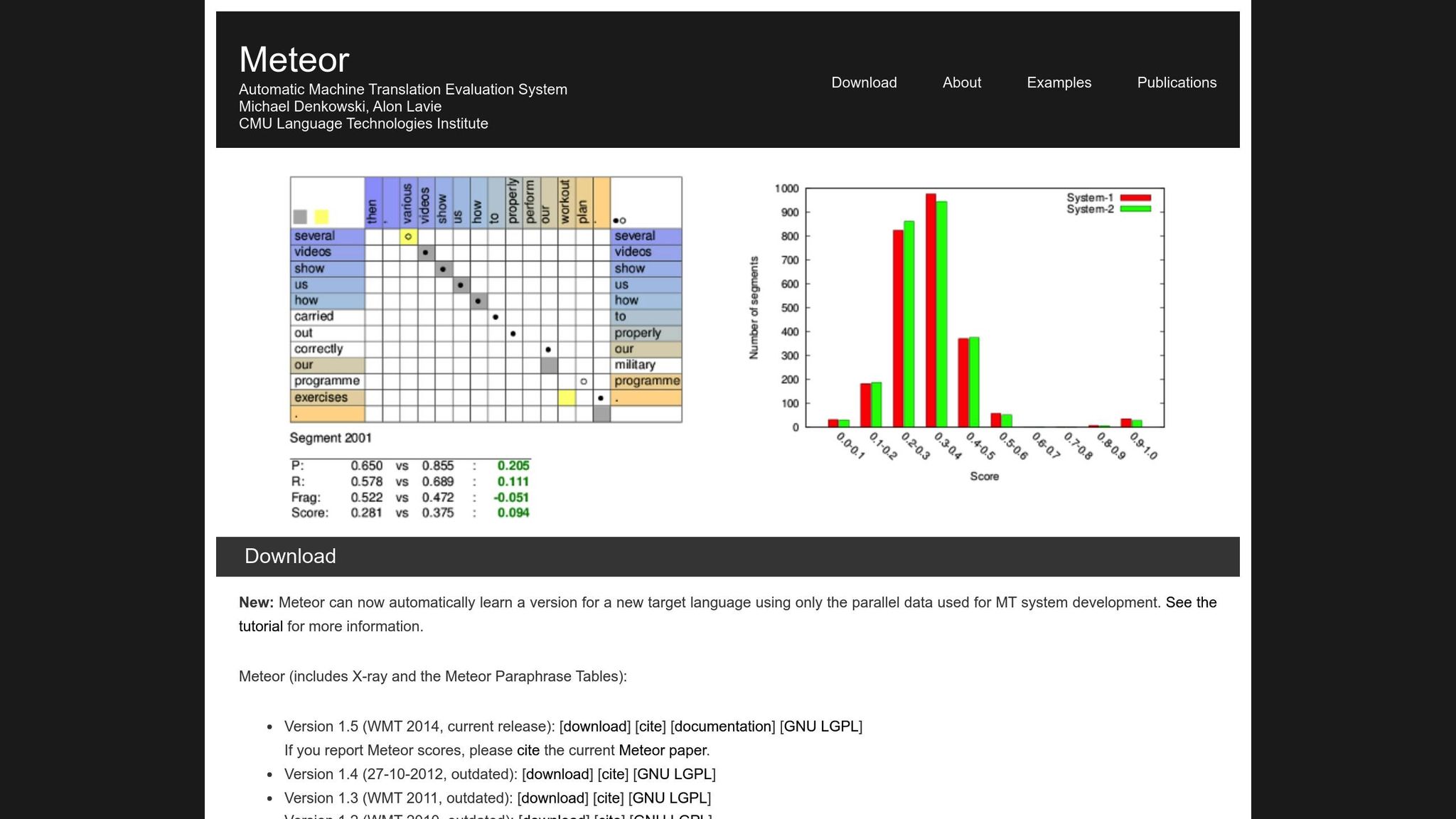
METEOR (Metric for Evaluation of Translation with Explicit ORdering) ulepsza BLEU, biorąc pod uwagę precyzję, wycofanie, synonimy, stemming i kary za kolejność słów [1]. Obsługuje warianty takie jak „biegnie" vs. „biegł" lub „szczęśliwy" vs. „radosny", co czyni go lepiej dostosowanym do tłumaczeń, w których znaczenie jest najważniejsze. Na przykład, podczas konkursu NIST MetricsMaTr10, METEOR‑next‑rank osiągnął korelację Spearmana rho wynoszącą 0,92 z ocenami człowieka na poziomie systemu i 0,84 na poziomie dokumentu [1].
To powiedziawszy, METEOR ma swoje własne wyzwania. Wymaga dodatkowych zasobów, takich jak bazy danych synonimów i algorytmy stemmingu, które zwiększają jego obciążenie obliczeniowe. Mimo tego, często zapewnia bardziej zniuansowaną i niezawodną ocenę, szczególnie w przypadku przechwytywania dokładności semantycznej.
Translation Edit Rate (TER)
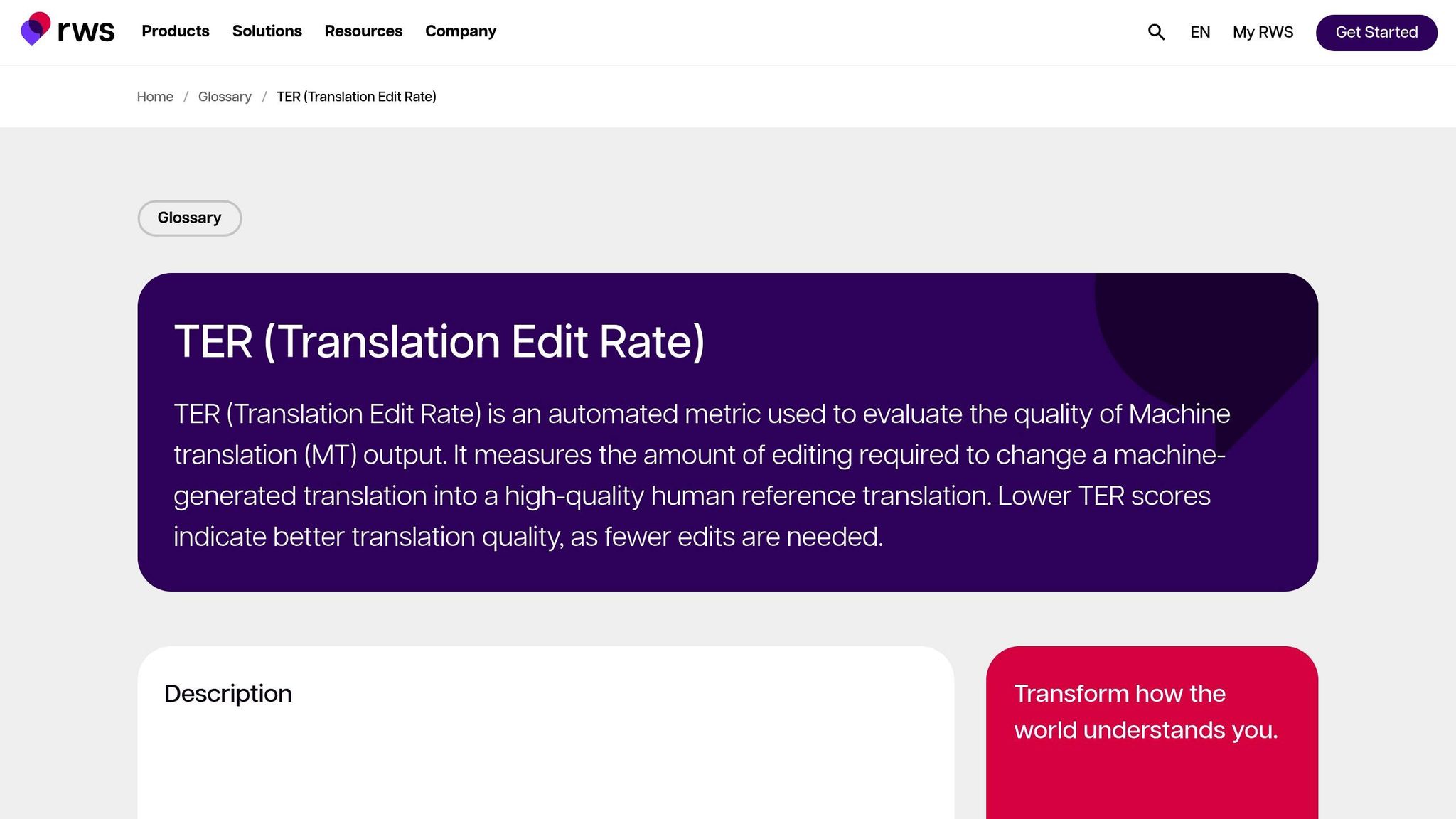
TER ocenia jakość tłumaczenia, obliczając liczbę edycji - wstawień, usunięć, podstawień i przesunięć - potrzebnych do przekształcenia wyniku maszyny w referencję. To czyni go szczególnie użytecznym do oceny nakładu pracy redakcyjnej wymaganego do wyrównania wyniku z pożądanym rezultatem. W ocenach MetricsMaTr10, TER-v0.7.25 wykazał korelację na poziomie systemu wynoszącą 0,89 z ocenami człowieka adekwatności semantycznej, podczas gdy TERp wykazał korelację na poziomie segmentu wynoszącą 0,68 [1].
Metryki oparte na sieciach neuronowych: BERTScore, COMET i GEMBA
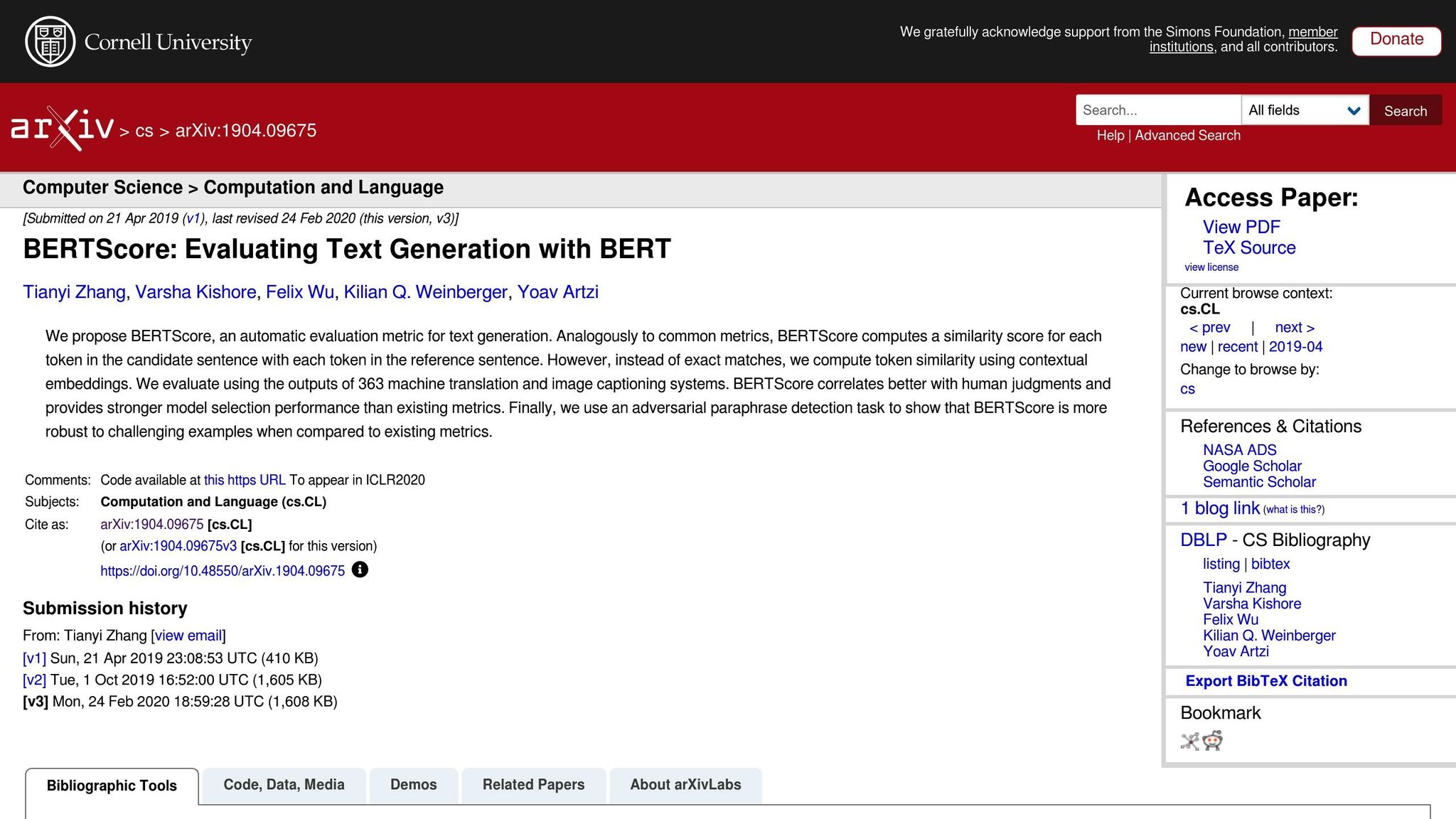
Metryki oparte na sieciach neuronowych podnoszą ocenę tłumaczenia na wyższy poziom, skupiając się na analizie semantycznej zamiast dokładnych dopasowań słów. Oto szybkie wyjaśnienie:
- BERTScore: Wykorzystuje osadzenia kontekstowe do pomiaru podobieństwa między tłumaczeniami.
- COMET: Integruje tekst źródłowy, hipotezę i tłumaczenia referencyjne w ramach sieci neuronowej wytrenowanej na adnotacjach człowieka. Osiągnął niektóre z najwyższych korelacji z ludzkimi ocenami jakości [5].
- GEMBA: Wykorzystuje duże modele językowe do szacowania jakości bez przykładów, oferując bliższe przybliżenie oceny człowieka.
Chociaż te metryki są potężne, wiążą się z kompromisami. W przeciwieństwie do BLEU i TER, które mogą działać na standardowych procesorach w milisekundach, metryki oparte na sieciach neuronowych, takie jak BERTScore i COMET, często wymagają przyspieszenia GPU do efektywnego obsługiwania dużych zbiorów danych. GEMBA w szczególności może wiązać się z wysokimi kosztami API i potencjalnymi uprzedzeniami dużych modeli językowych, co czyni je mniej dostępnymi dla niektórych użytkowników.
Automatyczne metryki do oceny systemów MT
Porównanie metryk tłumaczenia

Porównanie metryk dokładności tłumaczenia: BLEU, METEOR, TER, BERTScore, COMET i GEMBA
Tabela porównania metryk
Wybór właściwej metryki tłumaczenia często zależy od fokusa oceny i dostępnych zasobów. Tradycyjne metryki, takie jak BLEU, są szybkie i wymagają minimalnych zasobów, ale mają trudności z uchwyceniem głębszego znaczenia semantycznego. Z drugiej strony, metryki neuronowe doskonale radzą sobie z rozumieniem kontekstu i znaczenia, ale wymagają większej mocy obliczeniowej.
Ostatnie badania sugerują odejście od metryk opartych na nakładaniu się. Na przykład, ustalenia WMT22 zalecają porzucenie metryk takich jak BLEU na rzecz podejść neuronowych [6]. Badanie podkreśla, że metryki nakładania się, takie jak BLEU, spBLEU i chrF, słabo korelują z ocenami ekspertów człowieka.
Oto szybkie porównanie kluczowych metryk tłumaczenia, obejmujące ich obszary fokusa, metody punktacji, korelację z oceną człowieka, ograniczenia i przydatność do tłumaczeń książek:
| Metyka | Obszar fokusa | Zakres punktacji | Korelacja z oceną człowieka | Ograniczenia | Przydatność do tłumaczeń książek |
|---|---|---|---|---|---|
| BLEU | Precyzja n-gramów | 0 do 1 (lub 0-100) | Niska do umiarkowanej | Ma trudności z synonimami [7][8] | Niska; brak zdolności do uchwycenia stylu literackiego |
| METEOR | Precyzja, wycofanie, synonimy, kolejność słów | 0 do 1 | Wysoka | Wymaga zasobów specyficznych dla języka [7] | Umiarkowana; przydatna dla spójnej terminologii |
| TER | Odległość edycji (nakład pracy redakcyjnej) | 0 do 1 (niższe jest lepsze) | Umiarkowana | Ignoruje jakość semantyczną [7] | Niska; skupia się na mechanice, a nie na „głosie" |
| BERTScore | Podobieństwo semantyczne za pośrednictwem osadzeń kontekstowych | 0 do 1 | Wysoka | Wymaga dużo zasobów [7] | Wysoka; uchwytuje głębsze znaczenie i kontekst |
| COMET | Podobieństwo semantyczne i płynność | 0 do 1 (0,5-0,8 typowo) | Bardzo wysoka | Wymaga wstępnie wytrenowanych modeli [7][8] | Wysoka; zachowuje styl i zniuansowane znaczenie |
| GEMBA | Holistyczna ocena oparta na LLM | Zmienia się | Wysoka | Złożona konfiguracja; drogie API [7] | Wysoka; oferuje „humanoidalny" przegląd kompleksowy |
Ta tabela podkreśla, jak różne metryki są dostosowane do konkretnych potrzeb tłumaczenia. Dla tłumaczeń technicznych metryki takie jak BLEU i TER zapewniają szybkie, podstawowe benchmarki. Jednak dla tłumaczeń literackich - gdzie styl, ton i zniuansowane znaczenie są krytyczne - metryki neuronowe, takie jak BERTScore i COMET, działają znacznie lepiej. Narzędzia te są szczególnie zdolne do uchwycenia głębi i artystyczności tekstów literackich, które tradycyjne metryki często pomijają [7].
Na przykład, platformy takie jak BookTranslator.ai, które mają na celu zrównoważenie wydajności i jakości, znacznie korzystają z metryk neuronowych. Narzędzia takie jak BERTScore i COMET zapewniają zachowanie zarówno dokładności semantycznej, jak i stylu literackiego.
Aby postawić sprawy w perspektywie, „dobry" wynik BLEU zwykle mieści się w przedziale 30 do 40, przy czym wyniki powyżej 40 uważa się za silne, a wszystko powyżej 50 wskazuje na wysokiej jakości tłumaczenie [8]. Dla COMET, wyniki generalnie wahają się od 0,5 do 0,8, przy czym wartości bliższe 1,0 odzwierciedlają tłumaczenie bliskie ludzkiemu [8]. Metryki neuronowe nie tylko działają konsekwentnie w różnych typach tekstu, ale także lepiej się adaptują do różnych kontekstów w porównaniu z metrykami wrażliwymi na domenę, takimi jak BLEU [6].
sbb-itb-0c0385d
Metody oceny człowieka
Zautomatyzowane metryki mogą oferować szybkość i konsystencję, ale często brakuje im subtelnych szczegółów, które definiują jakość tłumaczenia. To właśnie tam pojawia się ocena człowieka jako złoty standard[2]. Chociaż jest wolniejsza i droższa, ocena człowieka odkrywa głębsze przyczyny problemów z jakością - rzeczy, które metryki takie jak BLEU lub COMET po prostu nie mogą zidentyfikować[9].
Istnieją dwa główne podejścia do oceny człowieka. Jednym jest Directly Expressed Judgment (DEJ), gdzie tłumaczenia są oceniane na skalach, takich jak płynność i adekwatność. Drugie obejmuje metody non-DEJ, które skupiają się na spotykaniu i kategoryzowaniu konkretnych błędów, często używając ram takich jak MQM[12]. Podczas gdy metody analityczne rozkładają poszczególne błędy i ich ważność, metody holistyczne patrzą na ogólną jakość. Razem te podejścia tworzą podstawę ram takich jak MQM.
MQM (Multidimensional Quality Metrics)

Gdy zautomatyzowane narzędzia zawodzą, MQM oferuje bardziej szczegółową i praktyczną alternatywę. Rozkłada błędy tłumaczenia na kategorie takie jak Dokładność, Płynność, Terminologia, Konwencje lokalizacyjne i Projekt/Znacznik, zamiast podsumowywać jakość jedną liczbą[18, 17].
„W przeciwieństwie do tego, zautomatyzowane metryki zazwyczaj dostarczają tylko liczbę bez wskazania, jak poprawić wyniki."
– Komitet MQM[10]
Błędy są oceniane pod względem ważności: Neutralne (zaznaczone, ale akceptowalne, bez kary), Drobne (nieznacznie zauważalne, waga kary 1), Poważne (wpływa na zrozumienie, waga kary 5) i Krytyczne (czyni tekst bezużytecznym, waga kary 25)[11]. Dla krytycznych tłumaczeń, takich jak dokumenty prawne, progi przejścia mogą być ustawione tak wysoko jak 99,5 na surowej skali punktacji[11].
Tym, co czyni MQM szczególnie przydatnym, jest jego zdolność do wskazania konkretnych obszarów problemowych. Na przykład, jeśli literackie tłumaczenie uzyska niski wynik, MQM może ujawnić, czy problem leży w niezręcznym sformułowaniu czy niespójnej terminologii. Ten poziom szczegółowości jest szczególnie cenny dla platform takich jak BookTranslator.ai, gdzie przechwycenie zarówno znaczenia, jak i stylu literackiego jest niezbędne.
Punktacja adekwatności i płynności
Budując na ustrukturyzowanych ramach takich jak MQM, oceniający skupiają się również na dwóch kluczowych wymiarach jakości tłumaczenia: adekwatności i płynności. Adekwatność mierzy, jak dobrze tłumaczenie przekazuje znaczenie tekstu źródłowego, podczas gdy płynność ocenia, jak naturalne i czytelne jest dla rodzimych użytkowników języka. Te aspekty są często oceniane na skalach pięciostopniowych[9].
Zrównoważenie tych dwóch wymiarów może być trudne, szczególnie w tłumaczeniach literackich. Zachowanie głosu oryginalnego autora przy jednoczesnym zapewnieniu, że tekst czyta się płynnie w języku docelowym, wymaga starannej uwagi.
Aby udoskonalić ten proces, oceniający używają Direct Assessment (DA), która ocenia tłumaczenia w formatach monolingwalnych, dwujęzycznych lub opartych na referencjach[9]. Scalar Quality Metric (SQM) idzie dalej ze skalą siedmiostopniową, pozwalając oceniającym oceniać poszczególne segmenty w kontekście całego dokumentu. Dla książek ten fokus kontekstowy jest krytyczny - jakość często zależy od tego, jak dobrze rozdział rozwija postacie lub utrzymuje ciągłość fabuły.
Używanie metryk do tłumaczenia książek
Tłumaczenie książek to wyjątkowe wyzwanie. W przeciwieństwie do instrukcji obsługi czy materiałów marketingowych, książki wymagają równowagi między dokładnością semantyczną - zapewnieniem, że znaczenie jest prawidłowe - i zachowaniem stylu - utrzymaniem głosu i tonu autora. Ocena tłumaczeń książek wymaga dostosowanego podejścia, z metrykami wybranymi do pasowania do konkretnego typu t