
Dlaczego METEOR ma znaczenie dla tłumaczenia książek za pomocą AI
METEOR, skrót od Metric for Evaluation of Translation with Explicit ORdering, to narzędzie do oceny tłumaczeń, które priorytetowo traktuje znaczenie i płynność zdań nad dokładnymi dopasowaniami słów. W przeciwieństwie do BLEU, które opiera się na ścisłym wyrównaniu słowo po słowie, METEOR wykorzystuje techniki takie jak stemming, dopasowywanie synonimów i parafraza, aby lepiej ocenić jakość tłumaczeń. To czyni go szczególnie skutecznym do tłumaczenia książek, gdzie uchwycenie głosu autora, tonu i przepływu narracji jest krytyczne.
Kluczowe spostrzeżenia:
- Dlaczego BLEU zawodzi: Ścisłe skupienie BLEU na dokładnych dopasowaniach słów karze ważne alternatywy, ma problemy z synonimami i nie potrafi ocenić spójności narracji, co czyni go nieodpowiednim dla literatury.
- Jak działa METEOR: METEOR wyrównuje tłumaczenia za pomocą dokładnych dopasowań, pierwiastków słów, synonimów i parafraz. Priorytetowo traktuje recall (pokrycie znaczenia) nad precyzją i stosuje kary za słabą kolejność słów.
- Wydajność: METEOR osiąga korelację 0,964 z oceną człowieka na poziomie korpusu, przewyższając BLEU's 0,817.
- Wpływ na tłumaczenia książek: Skupiając się na znaczeniu i przepływie, METEOR zapewnia, że tłumaczenia zachowują głębię i czytelność oryginalnego tekstu, co czyni go idealnym dla tłumaczeń literackich opartych na AI.
Dla platform takich jak BookTranslator.ai, METEOR umożliwia wysokiej jakości tłumaczenia w ponad 99 językach za zaledwie 5,99 USD za 100 000 słów, czyniąc literaturę dostępną dla globalnej publiczności.
Problemy z oceną tłumaczeń książek za pomocą AI
Dlaczego BLEU zawodzi w przypadku tłumaczeń długoformatowych
BLEU (Bilingual Evaluation Understudy), metryka wprowadzona w 2002 roku, opiera się na ścisłym dopasowaniu n-gramów, które często nie potrafi uchwycić subtelności tłumaczenia literackiego.
Jądro problemu leży w podejściu BLEU: ocenia jakość poprzez dopasowanie sekwencji 1- do 4-słowowych dokładnie tak, jak pojawiają się w referencji człowieka. Ta sztywna metoda boryka się z elastycznością twórczą wymaganą do tłumaczenia literatury. Jak wyjaśnia zespół NLLB:
"BLEU karze ważne alternatywne tłumaczenia. Jeśli referencja mówi „samochód jest czerwony", a system wytworzył „automobil jest czerwony", BLEU karze niezgodność, mimo że znaczenie jest identyczne" [4].
Ta niezdolność do rozpoznania synonimów jest szczególnie problematyczna dla książek, gdzie wybór słowa często nosi znaczną wagę. Na przykład BLEU traktuje „duży" i „wielki" jako całkowicie różne słowa, chociaż oznaczają to samo. Podobnie nie uwzględnia wariacji takich jak „biegnie", „biega" i „biegł", często karząc tłumaczenia, które są zarówno dokładne, jak i twórcze.
Innym podstawowym ograniczeniem jest projekt na poziomie korpusu BLEU. Został pierwotnie opracowany do obsługi dużych zbiorów danych, a nie precyzji na poziomie zdania krytycznej dla literatury. BLEU brakuje również zdolności do oceny przepływu zdań lub spójności narracji. Jak zauważa NLLB:
"BLEU nie uwzględnia bezpośrednio płynności ani zachowania znaczenia - to czysto miara pokrycia n-gramów" [4].
To oznacza, że tłumaczenie mogłoby technicznie zawierać wszystkie poprawne słowa, ale ułożyć je w pomieszanej, niezręcznej kolejności - i nadal uzyskać dobrą ocenę. Te niedociągnięcia podkreślają potrzebę metod oceny, które priorytetowo traktują kontekst, spójność i ogólne doświadczenie narracyjne.
Dlaczego kontekst i znaczenie są ważne w książkach
Książki to więcej niż tylko zbiory zdań - to skomplikowane narracje, gdzie każde słowo, struktura zdania i wybór stylistyczny odgrywa rolę w kształtowaniu doświadczenia czytelnika. Wąskie skupienie BLEU na dokładnych dopasowaniach słów pomija ten szerszy obraz, szczególnie gdy chodzi o utrzymanie przepływu narracji i spójności.
Luka w zrozumieniu semantycznym jest szczególnie rażąca. Michael Brenndoerfer wskazuje:
"Dwa semantycznie równoważne tłumaczenia mogą otrzymać bardzo różne wyniki BLEU w zależności od ich konkretnych wyborów słów" [5].
To tworzy problematyczną zachętę dla systemów AI do gonienia dokładnych dopasowań słów zamiast dążenia do dokładności semantycznej lub naturalnej płynności.
Tłumaczenie literackie wymaga równowagi między precyzją a recall - nie tylko unikaniem błędów, ale także zachowaniem głębi, tonu i resonancji emocjonalnej oryginalnego tekstu. BLEU mocno podkreśla precyzję, ale książki wymagają metryk, które mierzą, czy tłumaczenie uchwycić intencje autora i przepływ narracji. Narzędzia takie jak METEOR, które priorytetowo traktują znaczenie i przepływ, ważąc recall dziewięć razy wyżej niż precyzję, oferują bardziej odpowiednie podejście do oceny tłumaczeń literackich [1].
sbb-itb-0c0385d
METEOR : metryka do tłumaczenia maszynowego
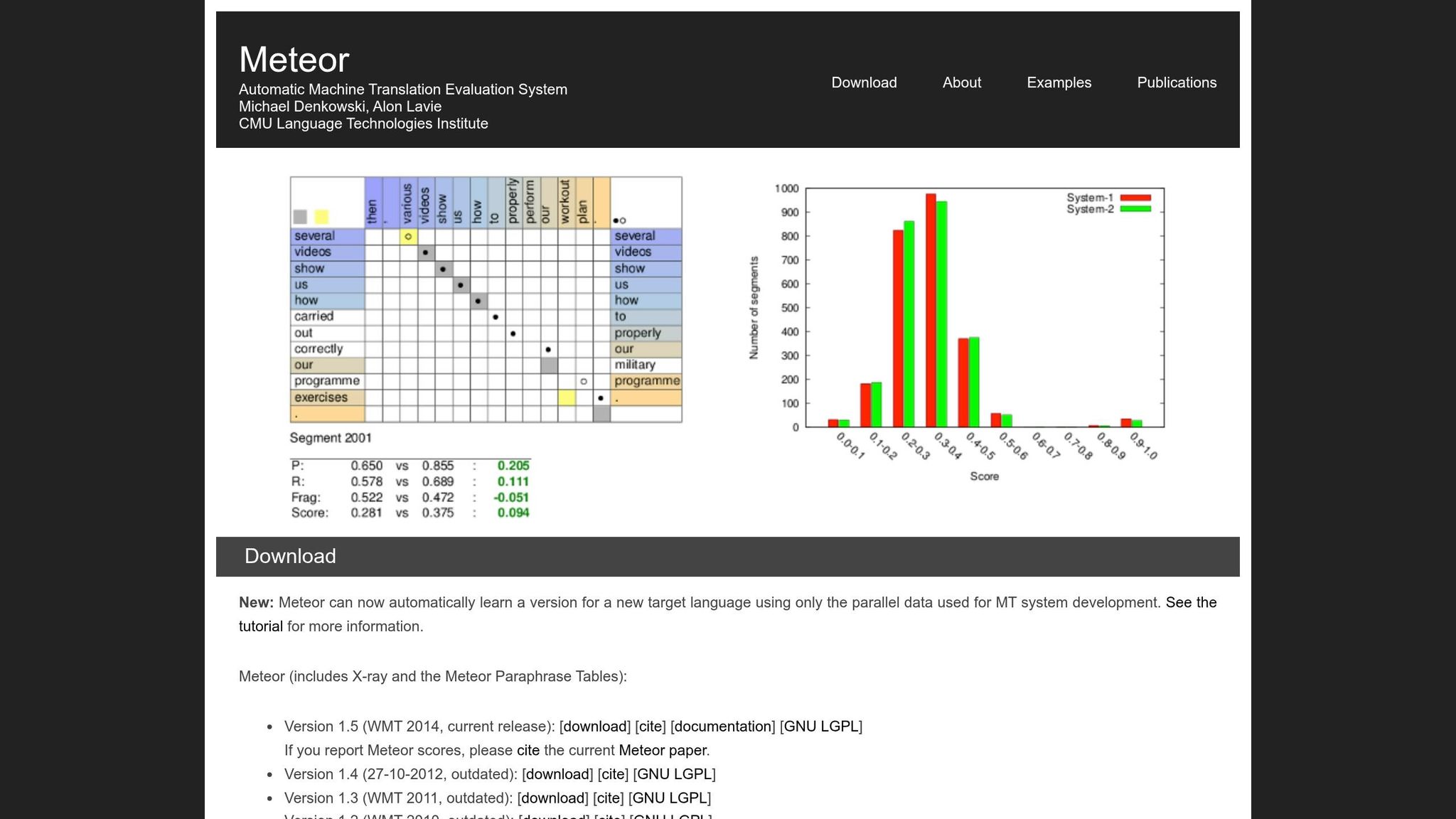
Co to jest METEOR i jak to działa?
METEOR, skrót od Metric for Evaluation of Translation with Explicit ORdering, został wprowadzony w 2005 roku przez badaczy Satanjeeva Banerjee'a i Alona Lavie'a na Carnegie Mellon University. Został opracowany w celu rozwiązania niektórych ograniczeń BLEU, szczególnie jego sztywnego dopasowania słowo po słowie. METEOR skupia się na zachowaniu znaczenia i naturalnej kolejności słów, co czyni go szczególnie przydatnym do oceny tłumaczeń, które muszą utrzymać przepływ narracji - takich jak tłumaczenia książek.
Metryka działa poprzez wyrównanie poszczególnych słów w tłumaczeniu kandydata z tymi w tłumaczeniu referencyjnym. Gdy istnieje wiele sposobów wyrównania słów, METEOR wybiera ten z najmniejszą liczbą „przecinków" (przecięć między liniami mapowania). To podejście pomaga utrzymać bardziej naturalną kolejność słów w procesie oceny [1].
Główne cechy METEOR
METEOR wyróżnia się dzięki podejściu do dopasowania warstwowego, które wykracza poza dokładne dopasowanie słów. Wykorzystuje cztery sekwencyjne moduły do oceny tłumaczeń:
- Dokładne dopasowanie: Dopasowuje identyczne formy słów.
- Stemming: Dopasowuje słowa, które mają ten sam pierwiastek, takie jak „biegnie" i „biega".
- Synonimia: Rozpoznaje słowa o podobnych znaczeniach za pomocą WordNet.
- Dopasowywanie parafraz: Dopasowuje frazy o podobnej zawartości semantycznej.
To warstwowe podejście rozwiązuje problemy BLEU ze zrozumieniem ważnych wariacji słów i alternatywnych wyrażeń [1][2][6].
System punktacji METEOR łączy dwa kluczowe elementy. Po pierwsze, oblicza ważoną średnią F precyzji i recall, przy czym recall jest ważony dziewięć razy bardziej niż precyzja. To odzwierciedla sposób, w jaki ludzie zwykle oceniają jakość tłumaczenia, priorytetowo traktując pokrycie oryginalnego znaczenia nad dokładnymi dopasowaniami [1]. Po drugie, stosuje karę za fragmentację, aby zniechęcić tłumaczenia, w których dopasowane słowa są rozproszone lub poza kolejnością. Jeśli dopasowane słowa są podzielone na zbyt wiele „fragmentów", wynik może zostać zmniejszony o do 50%. Zapewnia to, że tłumaczenia z poprawnymi słowami, ale słabą strukturą - często określane jako „sałata ze słów" - otrzymują niższe wyniki [1].
Jak METEOR wyrównuje się z oceną człowieka
Badania pokazują, że METEOR koreluje z oceną człowieka lepiej niż BLEU, osiągając współczynniki korelacji między 0,60 a 0,75, w porównaniu z zakresem BLEU 0,45 do 0,60 [6].
Ta silniejsza korelacja wynika w dużej mierze z skupienia METEOR na poziomie zdania. Podczas gdy BLEU jest przeznaczony do oceny tłumaczeń na poziomie korpusu, METEOR ocenia poszczególne zdania lub segmenty. To czyni go szczególnie skutecznym w ocenie przepływu i spójności potrzebnych w tłumaczeniach książek [1]. Ponadto METEOR może przetwarzać do 500 segmentów na sekundę na rdzeń CPU, co czyni go zarówno wydajnym, jak i niezawodnym do praktycznego zastosowania [2]. Jego zdolność do ścisłego dopasowania do oceny człowieka utrwaliła jego rolę w ulepszaniu tłumaczeń książek opartych na AI.
METEOR vs. BLEU: Dlaczego METEOR działa lepiej dla tłumaczenia książek za pomocą AI

Porównanie metryk tłumaczenia METEOR vs BLEU
Kluczowe zalety METEOR dla tłumaczenia książek
Jeśli chodzi o tłumaczenie dzieł literackich, METEOR wyróżnia się jako bardziej efektywna metryka oceny niż BLEU. Jego unikalne metody wyrównania i skupienie na znaczeniu czynią go szczególnie odpowiednim dla niuansów tłumaczenia książek.
Jedną z głównych różnic jest sposób, w jaki każda metryka obsługuje dokładność semantyczną. BLEU opiera się na dokładnych dopasowaniach słów, które mogą niesprawiedliwie karać tłumaczenia, które używają synonimów lub alternatywnych form słów - nawet gdy znaczenie pozostaje nienaruszone. METEOR, z drugiej strony, zawiera stemming i dopasowywanie synonimów. Na przykład rozpoznaje, że słowa takie jak „dobry" i „dobrze" lub „biega" i „biegnie" mają tę samą wartość semantyczną. Ta elastyczność jest niezbędna dla tłumaczeń literackich, gdzie różnorodny słownik i twórcze sformułowania są często konieczne do zachowania stylu i intencji autora.
Innym ważnym rozróżnieniem jest nacisk METEOR na recall nad precyzją. BLEU priorytetowo traktuje precyzję, mierząc, ile słów w tłumaczeniu generowanym przez AI pasuje do tych w tekście referencyjnym. METEOR, jednak, równoważy precyzję i recall, przy czym recall jest ważony dziewięć razy bardziej [1]. Zapewnia to, że tłumaczenie uchwycić pełne znaczenie oryginalnego tekstu - krytyczny czynnik dla dokładnego przekazania złożonych narracji.
METEOR również wyróżnia się w ocenie na poziomie zdania. Podczas gdy BLEU jest dostosowany do oceny tłumaczeń na poziomie korpusu, METEOR jest przeznaczony do ścisłego wyrównania z oceną człowieka na poszczególnych zdaniach lub segmentach. Osiąga maksymalną korelację około 0,403 na poziomie zdania [1]. To czyni go szczególnie skutecznym w ocenie przepływu i spójności określonych fragmentów, co jest kluczowe w tłumaczeniu książek.
Jedną z wyróżniających się cech METEOR jest jego kara za fragmentację, która rozwiązuje problem kolejności słów i struktury zdań. Jeśli dopasowane słowa w tłumaczeniu są rozproszone na zbyt wiele fragmentów, wynik może spaść nawet o 50% [1]. Ten mechanizm zapewnia, że tłumaczenia zachowują naturalną i spójną strukturę - coś, co BLEU często przeoczy. Skupiając się na tych szczegółach, METEOR pomaga zachować subtelne znaczenie i czytelność oryginalnego tekstu.
Tabela porównawcza: METEOR vs. BLEU
| Cecha | BLEU | METEOR |
|---|---|---|
| Główne skupienie | Precyzja (dokładne pokrycie słów) | Recall (pokrycie znaczenia i zawartości) |
| Kryteria dopasowania | Dokładne dopasowanie n-gramów | Dokładne, stemming, synonimy i parafrazy |
| Dokładność semantyczna | Niska (tylko dokładne dopasowania słów) | Wysoka (zawiera synonimy i stemming) |
| Korelacja z człowiekiem | Silniejsza na poziomie korpusu | Silna na poziomach zdania i korpusu |
| Struktura zdania | Pośrednia (poprzez pokrycia n-gramów) | Bezpośrednia (poprzez karę za fragmentację i wyrównanie) |
| Elastyczność | Sztywna; karze twórcze sformułowania | Elastyczna; nagradza równoważność semantyczną |
| Obsługa Recall | Pośrednia (kara za zwięzłość) | Bezpośrednia (obliczenie recall ważone 9x bardziej) |
Jak METEOR jest używany na platformach tłumaczenia książek za pomocą AI
Zapewnianie jakości za pomocą METEOR
Platformy tłumaczenia zasilane sztuczną inteligencją wykorzystują METEOR do utrzymania dokładności semantycznej i podtrzymania delikatnych niuansów dzieł literackich. Proces rozpoczyna się od mapowania wyrównania, gdzie system identyfikuje połączenia między tłumaczeniem generowanym przez AI a tekstem referencyjnym. Obejmuje to rozpoznanie dokładnych dopasowań, pierwiastków słów, synonimów, a nawet parafraz [2]. Takie szczegółowe mapowanie zapewnia, że tłumaczenie odzwierciedla oryginalne znaczenie, nawet jeśli sformułowanie różni się.
Aby obsługiwać złożoności różnych języków, METEOR jest konfigurowany za pomocą narzędzi specyficznych dla języka, takich jak stemmery i tabele parafraz. Na przykład platformy takie jak BookTranslator.ai, które obsługują ponad 99 języków, używają tych zasobów do radzenia sobie z unikalnymi strukturami lingwistycznymi różnych języków. Niezależnie od tego, czy chodzi o języki romańskie, takie jak hiszpański i francuski, czy bardziej skomplikowane, takie jak arabski i czeski, te narzędzia są niezbędne do uchwycenia wariacji morfologicznych [2].
To, co wyróżnia METEOR, to jego zdolność do precyzyjnego dostrojenia parametrów. Platformy mogą kalibrować te ustawienia, aby wyrównać się z konkretnymi zadaniami oceny, takimi jak pomiar adekwatności lub utrzymanie spójnego stylu. Ta funkcja jest szczególnie wartościowa w tłumaczeniach literackich, gdzie zachowanie głosu autora i rytmu narracji jest niezbędne. Ponadto kara za fragmentację systemu zapewnia, że zdania płyną naturalnie, unikając niezręcznego, rozłączonego uczucia zwykłego ciągu poprawnych słów. Ta dbałość o płynność zdań jest krytyczna dla utrzymania czytelników zaabsorbowanych historią przez setki stron.
Poza poprawianiem jakości tłumaczeń, METEOR odgrywa również kluczową rolę w udostępnianiu literatury globalnej publiczności.
Poprawa wielojęzycznego dostępu do literatury
Chroniąc znaczenie i głębię oryginalnego tekstu, METEOR nie tylko poprawia jakość tłumaczenia, ale także pomaga przynieść literaturę czytelnikom w ich ojczystych językach. Korzystając z danych równoległych, METEOR umożliwia platformom rozszerzenie ich oferty języków bez poświęcania jakości [2]. Ta zdolność do adaptacji jest szczególnie ważna dla czytelników na niedoreprezentowanych rynkach języków.
Podejście oceny skupione na człowieku zapewnia, że tłumaczenia brzmią naturalnie i angażująco. Na przykład platformy takie jak BookTranslator.ai zapewniają tłumaczenia począwszy od 5,99 USD za 100 000 słów, zapewniając wysokiej jakości tłumaczenia za przystępną cenę, zachowując jednocześnie urok narracyjny historii i subtelności kulturowe. Priorytetowo traktując recall nad precyzją, METEOR uchwycić bogatość tekstu źródłowego, w tym skomplikowane łuki postaci i warstwy tematyczne, które są niezbędne dla przekonującej opowieści.
Podsumowanie
METEOR zmienia grę w ocenie tłumaczenia książek za pomocą AI poprzez priorytetowe traktowanie dokładności semantycznej i naturalnej czytelności. W przeciwieństwie do tradycyjnych metryk, METEOR uwzględnia synonimy, pierwiastki słów i parafrazy, osiągając imponującą korelację 0,964 z oceną człowieka na poziomie korpusu - znacznie wyższą niż BLEU's 0,817 [1]. Zapewnia to, że tłumaczenia zachowują styl autora, spójność narracji i subtelne elementy kulturowe.
To, co wyróżnia METEOR, to jego recall-weighted scoring połączony z karą za fragmentację, co zapewnia, że tłumaczenia nie tylko uchwycić pełne znaczenie oryginalnego tekstu, ale również czytają się gładko. Jest to szczególnie krytyczne dla treści długoformatowych, gdzie utrzymanie spójności i przepływu na całej rozszerzonej narracji jest niezbędne.
Dla platform takich jak BookTranslator.ai, obsługujących ponad 99 języków, zdolność METEOR do rozpoznania wariacji lingwistycznych umożliwia wysokiej jakości tłumaczenia po konkurencyjnych stawkach - począwszy od zaledwie 5,99 USD za 100 000 słów. Poprzez wykorzystanie danych równoległych do nauki nowych języków docelowych [2], METEOR otwiera drzwi dla czytelników w niedofinansowanych regionach, aby uzyskać dostęp do literatury w ich ojczystych językach.
"METEOR funkcjonuje bardziej jak nowoczesne systemy rozpoznawania głosu, które rozumieją różne sposoby powiedzenia tego samego. Ocenia tłumaczenia z elastycznością, odzwierciedlając ocenę człowieka.