
Heb je je ooit afgevraagd hoe enorme boeken zo snel worden vertaald terwijl de consistentie perfect blijft? Het is geen magie, en het is niet puur een machine die het werk doet. Het geheim ligt in een proces dat Computer-Assisted Translation, of CAT, wordt genoemd.
Dit gaat niet over het vervangen van een bekwame menselijke vertaler door AI. Denk er eerder aan als een krachtig partnerschap. CAT-tools zijn geavanceerde assistenten die zich bezighouden met repetitieve, geheugenbased taken, waardoor de menselijke expert zich kan concentreren op wat zij het beste doen: nuance, culturele context en de subtiele kunst van taal vastleggen.
Computer-Assisted Translation voor PDF's begrijpen

Stel je een meesterchef voor met een high-tech souschef. De hoofdchef is nog steeds de creatieve kracht, proeft, past aan en neemt elke kritieke beslissing. Maar de souschef voert feilloos het vervelende voorbereidingswerk uit—hakken, meten en elke recept perfect onthouden. Dat is precies hoe CAT werkt. Het is een samenwerking, geen geautomatiseerde fabriek.
De software 'denkt' niet voor de vertaler of maakt creatieve keuzes. Het stroomlijnt gewoon de workflow door zich bezig te houden met taken die mensen vermoeiend vinden maar computers in een oogwenk kunnen doen.
De kerncomponenten van CAT-software
Dit mens-en-machine-team krijgt zijn kracht van twee hoofdkenmerken die de basis vormen van elk serieus vertaalproject:
- Translation Memory (TM): Dit is een levende database die alles opslaat waar een vertaler ooit aan heeft gewerkt—elke zin, frase en alinea. De volgende keer dat een vergelijkbare zin opduikt, stelt de TM onmiddellijk de vorige vertaling voor. Dit bespaart ongelooflijk veel tijd en houdt de taal consistent van hoofdstuk één tot de appendix.
- Terminology Databases (Termbases): Beschouw een termbase als een aangepast woordenboek voor je specifieke project. Het is een lijst met kritieke termen die altijd op dezelfde manier moeten worden vertaald. Voor een fantasyroman kan dit karakternamen, magische spreuken of fictieve locaties bevatten. Het is het gereedschap dat consistentie garandeert.
Dit krachtige duo is een belangrijke reden voor de groei van de industrie. De machine translation markt, die vaak in CAT-systemen is geïntegreerd, werd in 2020 gewaardeerd op USD 153,8 miljoen en is op weg om in 2026 USD 230,67 miljoen te bereiken. Efficiëntie is het spelletje, vooral als je met massale woordaantallen van boeken te maken hebt.
Het belangrijkste om te onthouden is dat CAT gaat over vergroting, niet automatisering. Het verbetert menselijke vaardigheden en stelt vertalers in staat zich te concentreren op de creatieve en culturele fijnstelling die een vertaling echt geweldig maakt.
Maar hier zit het addertje onder het gras als je een PDF in het spel brengt. Voordat dit geweldige systeem kan werken, moet de software het document kunnen lezen. Een PDF is vaak als een afbeelding van tekst; je kunt de woorden zien, maar je kunt ze niet gemakkelijk pakken om mee te werken.
Dit betekent dat er een cruciale eerste stap is voordat enig vertaalmagisch kan gebeuren. De technologie achter dit, die machines in staat stelt menselijke taal te begrijpen, is fascinerend. Als je nieuwsgierig bent hoe het werkt, kun je een goed overzicht krijgen door Natural Language Processing (NLP) te verkennen.
De unieke uitdaging van het vertalen van PDF-bestanden
Dus, waarom is het vertalen van een PDF veel moeilijker dan, zeg maar, een eenvoudig Word-document? Hier is een goede manier om erover na te denken: een PDF is als een foto van een boekpagina. Je kunt de woorden en afbeeldingen prima zien, maar je kunt ze niet zomaar aanpassen en bewerken zoals je zou doen in een normaal tekstdocument. Dat vaste formaat is de kern van het probleem.
Dit enkele probleem werpt een grote moersleutel in elke computer assisted translation PDF workflow. Voordat een CAT-tool zelfs maar kan beginnen met Translation Memory of woordenboeken, heeft het schone, bewerkbare tekst nodig. Een PDF bestrijdt dit van nature bij elke stap.
Digitaal-native versus gescande PDF's
Je zult over het algemeen twee soorten PDF's tegenkomen, en elk brengt zijn eigen moeilijkheden mee. Uitzoeken welk type je onder handen hebt, is de eerste stap.
- Digitaal-native PDF's: Dit zijn bestanden die rechtstreeks van programma's zoals Microsoft Word of Adobe InDesign zijn gemaakt. De tekst is technisch gezien daar, maar is vaak op zijn plaats vergrendeld. Het eruit proberen te krijgen voelt als een spaarvarken stukslaan—ja, je krijgt de munten eruit, maar je zit met een puinhoop van verbroken opmaak en kapotte alinea's.
- Gescande PDF's: Deze zijn nog moeilijker. Een gescande PDF is eigenlijk gewoon een afbeelding, wat betekent dat de 'tekst' niets meer is dan een patroon van pixels. Om er iets van te maken wat een computer kan begrijpen, moet je het door Optical Character Recognition (OCR) halen, een proces dat de afbeelding scant en die pixels terug converteert naar digitale tekst.
Een groot deel van PDF-vertaling is gewoon worstelen met deze gescande documenten. Leren hoe je de tekst schoon kunt extraheren is een kritieke vaardigheid. Voor een beter inzicht in dit complexe proces loont het gescande PDF-bestanden vertalen te leren.
Veelvoorkomende valkuilen voor auteurs
Zonder de juiste tools en proces raken auteurs die een PDF proberen te vertalen vaak tegen een muur van frustrerende, tijdverspillende problemen die de eindkwaliteit van hun boek verpesten. Voor een dieper inzicht in het navigeren door deze uitdagingen is onze gids over hoe je een gescande PDF vertaalt een geweldige bron.
Het fundamentele probleem met een PDF is dat het is ontworpen voor weergave, niet voor bewerking. Het hele doel ervan is een statische visuele lay-out op elk apparaat te behouden, wat het tegenovergestelde is van wat een vertaalworkflow nodig heeft: flexibele, toegankelijke inhoud.
Dit basisconflict leidt tot alle klassieke kopzorgen:
- Verbroken opmaak: Wanneer je de tekst eindelijk eruit hebt gerukt, kunnen die schone kolommen en netjes georganiseerde alinea's in een chaotische warboel veranderen.
- Onbewerkbare afbeeldingen: Elke tekst die onderdeel is van een afbeelding, zoals in een grafiek of diagram, blijft vergrendeld. Het is onvertaalbaar zonder serieuze afbeeldingsbewerking.
- Onnauwkeurige tekstextractie: OCR is krachtige technologie, maar het is niet foutloos. Het kan karakters misinterpreteren, typefouten introduceren of volledig mislukken op scans van lage kwaliteit. Dit betekent dat iemand de volledige tekst nauwgezet moet controleren voordat de vertaling zelfs maar kan beginnen.
Deze problemen zijn precies waarom een professionele, tool-gestuurde aanpak niet alleen een nice-to-have is; het is essentieel voor het bereiken van een resultaat van hoge kwaliteit.
Je stap-voor-stap PDF-vertaalworkflow
In een computer assisted translation PDF project springen, vooral voor iets zo complex als een boek, kan overweldigend voelen. Maar als je het in een duidelijke, methodische workflow opsplitst, wordt het proces veel beter beheersbaar. Deze routekaart zal je door de hele reis leiden, van die vergrendelde PDF tot een perfect vertaald, publicatieklaar boek.
Het echte werk begint lang voordat het eerste woord wordt vertaald. De eerste, en wellicht belangrijkste, fase gaat helemaal over voorbereiding. Denk eraan als het leggen van een fundament voor een huis—als je dit deel niet goed doet, zal alles wat je erop bouwt instabiel zijn. Het doel hier is je statische PDF in een formaat krijgen dat vertaalsoftware echt kan lezen.
Fase 1: Voorbereiding en tekstextractie
Je eerste taak is de tekst uit de starre structuur van de PDF bevrijden. Hoe je dit doet, hangt volledig af van wat voor soort PDF je hebt: een die digitaal is geboren of een die een scan van een fysiek document is.
Het pad dat je aan het allereerste begin inslaat, verandert op basis van de oorsprong van de PDF.
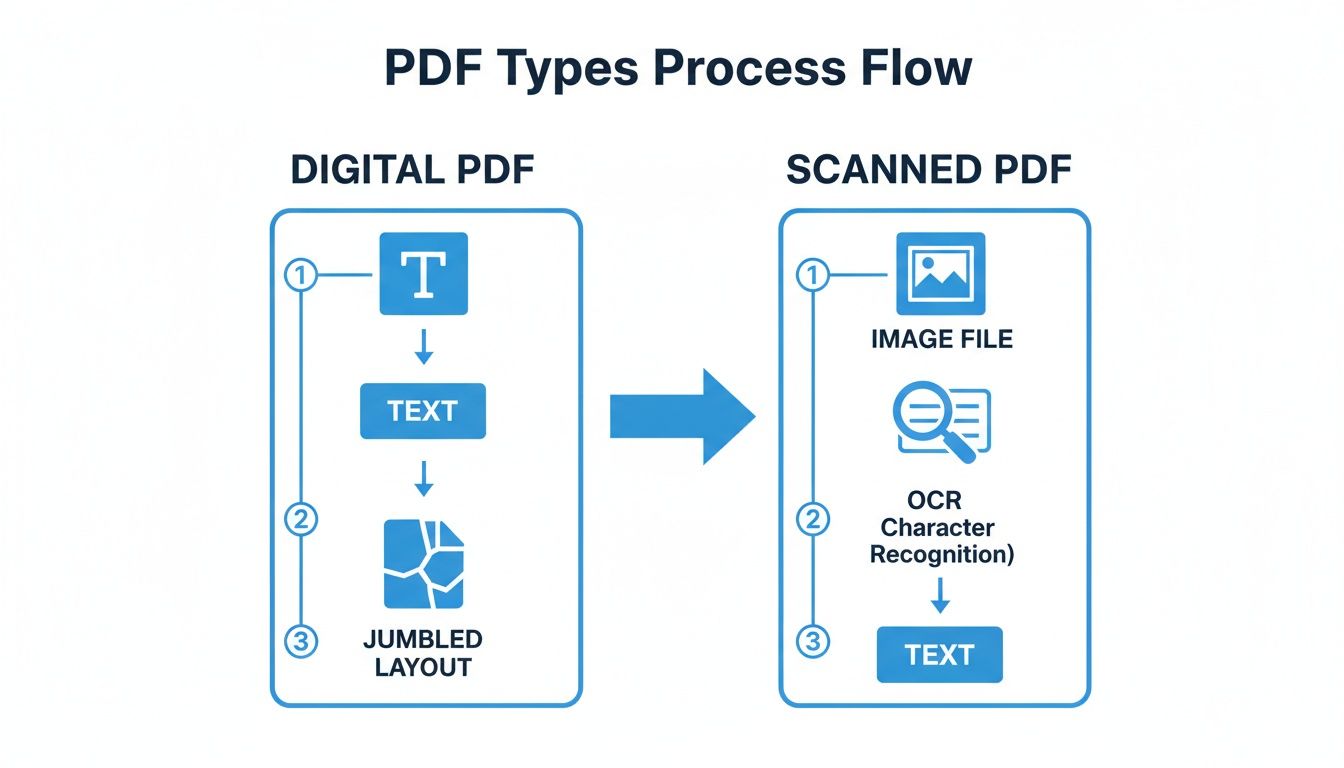
Zoals je kunt zien, leiden beide paden tot geëxtraheerde tekst, maar de gescande PDF voegt een lastige extra stap toe: OCR.
Voor gescande boeken betekent dit de pagina's door Optical Character Recognition (OCR) software halen. Waarschuwing: dit proces is zelden foutloos. Het spuwt vaak fouten uit zoals verkeerd gelezen letters ("l" in plaats van "1") of vreemd samengevoegde woorden. Daarom is een nauwgezette opschoning en correctie van de geëxtraheerde tekst absoluut essentieel voordat je iets anders doet.
Om je een duidelijker beeld te geven, hier is een overzicht van de volledige workflow van begin tot eind.
CAT-workflowfasen voor PDF-vertaling
Deze tabel geeft een overzicht van de essentiële fasen in een computer-assisted translation workflow voor een PDF-bestand, met wat er in elke stap gebeurt en de betrokken tools.
| Fase | Doelstelling | Veelgebruikte tools of technieken |
|---|---|---|
| 1. Tekstextractie | De PDF omzetten in een bewerkbaar tekstformaat dat een CAT-tool kan verwerken. | Adobe Acrobat Pro, Abbyy FineReader (voor OCR), verschillende online converters. |
| 2. CAT-import | De schone tekst in een CAT-omgeving importeren en deze opsplitsen in segmenten. | Trados Studio, MemoQ, Phrase, Smartling. |
| 3. Vertaling | De tekst segment voor segment vertalen, gebruikmakend van TM- en Termbase-assets. | Menselijke taalkundige die in de editor van het CAT-hulpmiddel werkt. |
| 4. Kwaliteitsborging | Automatische en handmatige controles uitvoeren om inconsistenties, fouten en opmaakproblemen op te sporen. | Ingebouwde QA-checkers in CAT-tools (bijv. Xbench), handmatige correctie. |
| 5. Lay-out (DTP) | De originele boeklay-out met de vertaalde tekst en afbeeldingen opnieuw maken. | Adobe InDesign, QuarkXPress, Affinity Publisher. |
Elke fase bouwt voort op de vorige, zodat het uiteindelijke vertaalde boek nauwkeurig, consistent en professioneel opgemaakt is.
Fase 2: CAT-omgeving en vertaling
Met je schone, bewerkbare tekst klaar, is het tijd om in de CAT-omgeving te gaan. Dit is waar de magie gebeurt, met krachtige softwarefuncties die consistentie helpen garanderen en het werk versnellen.
- Import en segmentatie: Je begint met het importeren van de tekst in je CAT-tool. De software snijdt de tekst dan automatisch in kleinere stukken genaamd segmenten, meestal zinnen of frasen.
- Assets gebruiken: Terwijl de vertaler door elk segment werkt, stelt het hulpmiddel actief overeenkomsten voor uit de Translation Memory (TM). Tegelijkertijd markeert de Termbase (je projectwoordenboek) sleuteltermen om ervoor te zorgen dat ze elke keer op dezelfde manier worden vertaald.
- Menselijke vertaling en beoordeling: Dit is waar de menselijke expert het overneemt. Een professionele vertaler zal de suggesties van de software accepteren, afwijzen of aanpassen, gebruikmakend van hun taalkundige vaardigheden om de juiste toon, culturele nuances en precieze betekenis vast te leggen. Deze stap is wat een vertaling van hoge kwaliteit onderscheidt van een onbeholpen, door machine gegenereerde.
De invloed van AI in deze ruimte is onmogelijk te negeren. De AI-taalvertaalmarkt explodeerde van USD 1,88 miljard in 2023 naar USD 2,34 miljard in 2024, een duidelijk teken van de enorme vraag naar deze tools. Het verandert ook hoe professionals werken, met 70% van Europese taalkundigen die nu machine translation gebruiken als onderdeel van hun dagelijks werk. Je kunt meer lezen over de opkomst van AI in vertaling op sonix.ai.
De CAT-omgeving is het hart van de workflow. Dit is waar technologie en menselijke expertise samensmelten, gebruikmakend van opgeslagen kennis (TM en woordenboeken) om laag voor laag een consistente, hoogwaardige vertaallaag op te bouwen.
Fase 3: Kwaliteitsborging en uiteindelijke lay-out
Zodra elke zin is vertaald, verschuift de focus naar polijsten en presentatie. Dit is de eindsprint.
Eerst voer je een reeks geautomatiseerde Quality Assurance (QA) controles uit. Deze tools zijn ontworpen om de soort fouten op te sporen die een menselijk oog gemakkelijk mist, zoals inconsistente terminologie, nummeropmaakfouten of extra spaties. Denk eraan als een digitaal vangnet.
Tot slot wordt de vertaalde tekst doorgegeven aan de Desktop Publishing (DTP) fase. Hier opent een professionele ontwerper een programma zoals Adobe InDesign en bouwt zorgvuldig de originele lay-out van je boek opnieuw op. Ze voegen afbeeldingen opnieuw in, formatteren de nieuwe tekst zodat deze past, en zorgen ervoor dat het uiteindelijke vertaalde boek een perfect visueel equivalent is van het origineel. Het is een moeizaam maar absoluut kritiek eindstadium.
Essentiële tools voor Computer Assisted PDF-vertaling

Om een PDF met computergestuurde methoden succesvol te vertalen, heb je meer nodig dan slechts één stuk software. Het gaat om het samenstellen van een gespecialiseerde digitale gereedschapskist. Elk hulpmiddel heeft een heel specifieke taak: de tekst voorzichtig uit de PDF trekken, je helpen deze te vertalen, en dan alles in een nieuwe taal weer in elkaar zetten, zodat het er precies hetzelfde uitziet als het origineel.
Denk eraan als een werkplaats met drie fasen voor je boek. Ten eerste moet je het origineel voorzichtig demonteren. Ten tweede bouw je de kerncomponenten—de woorden zelf—in de doeltaal opnieuw op. Tot slot zorg je voor de uiteindelijke montage en afwerkingstouches. Elke fase heeft het juiste gereedschap nodig voor het werk.
De tekst ontgrendelen met converters en OCR
De allereerste stap is vaak de lastigste. Je hebt een manier nodig om de tekst uit het vaste, 'platte' PDF-formaat te ontgrendelen. Voor het vertalen van hele boeken is het goed doen van dit eerste stadium absoluut kritiek.
Je belangrijkste tools hiervoor zijn:
- PDF-converters: Als je PDF oorspronkelijk van een programma zoals Word is gemaakt, kan een goede converter zoals Adobe Acrobat Pro deze vaak schoon terug exporteren naar een bewerkbaar formaat. Dit is altijd het best-case scenario.
- OCR-software: Voor gescande boeken of PDF's die eigenlijk alleen maar afbeeldingen van tekst zijn, heb je Optical Character Recognition (OCR) nodig. Een krachtig hulpmiddel zoals ABBYY FineReader is ontworpen om de afbeelding van elke pagina te 'lezen' en de vormen van de letters terug te converteren naar echte, bewerkbare tekst.
Zonder een van deze tools is je PDF een gesloten doos. Ze zijn de poortwachters van je inhoud, waardoor deze toegankelijk wordt voor de vertaaltools die daarna komen.
De vertaalmotor: CAT-tools
Zodra de tekst vrij is, gaat deze naar het hart van de operatie: het CAT-hulpmiddel. Dit is waar de vaardigheden van de vertaler samenkomen met krachtige software om een nauwkeurige en, het belangrijkste, consistente vertaling te produceren.
Professionele CAT-tools zoals Trados Studio of memoQ zijn gebouwd rond twee functies die absoluut essentieel zijn voor projecten van boeklengte. Hun hele doel is consistentie garanderen van pagina één tot het laatste hoofdstuk.
Translation Memory (TM): Denk hieraan als het geheugen van je project. Het slaat elke zin op die je vertaalt. Wanneer diezelfde zin—of een zeer vergelijkbare—opnieuw verschijnt, stelt de TM onmiddellijk de vorige vertaling voor.
Terminology Management (Termbase): Dit is een aangepast woordenboek voor je boek. Het zorgt ervoor dat sleuteltermen, zoals karakternamen, plaatsen of unieke concepten, altijd op exact dezelfde manier worden vertaald, elke keer dat ze verschijnen.
Deze software wordt centraal voor wereldwijde communicatie. De language translation software markt, gewaardeerd op USD 10,72 miljard in 2024, zal naar verwachting groeien naar USD 18,26 miljard tegen 2033, met documentvertaling als het grootste onderdeel. Deze groei toont gewoon aan hoe vitaal deze tools zijn geworden. Je kunt meer lezen over deze markttrends op researchnester.com.
De beelden opnieuw opbouwen met DTP-software
Na afloop van de vertaling zit je met een blok platte tekst. De uiteindelijke, kritieke stap is om die tekst terug in de originele lay-out van het boek te krijgen, compleet met afbeeldingen en professionele opmaak. Dit is het werk van Desktop Publishing (DTP) software.
Industriestandaard programma's zoals Adobe InDesign worden voor deze fase gebruikt. Een bekwaam ontwerper neemt de vertaalde tekst en plaatst deze zorgvuldig terug in de lay-out, voegt afbeeldingen opnieuw in, past de afstand aan om rekening te houden met tekstexpansie, en zorgt ervoor dat het afgewerkte boek een perfect spiegelbeeld van het origineel is. Dit is een handmatig proces dat het oog van een ontwerper vereist, geen geautomatiseerde stap. Onze gids naar documentvertaalsoftware gaat dieper in op dit soort tools.
Best practices voor het vertalen van je PDF-boek
Een boekvertaling goed doen, vooral als je met een PDF begint, gaat allemaal over strategie. Als je zonder plan begint, kun je gemakkelijk in een frustrerende, dure puinhoop belanden. Maar door een paar bewezen best practices te volgen, kun je het proces soepel navigeren en een resultaat bereiken dat je originele werk recht doet.
De eerste, en verreweg belangrijkste, regel is dit: zoek altijd eerst naar het originele bronbestand. Voordat je zelfs maar denkt aan het aanpakken van de PDF, doe je alles wat je kunt om het bestand waarvan het is gemaakt te vinden, of dat nu een Adobe InDesign-project, een Microsoft Word-document of iets dergelijks is. Deze ene stap kan je een wereld van verdriet besparen, omzeilt het lastige en tijdrovende proces van tekstextractie en lay-out opnieuw opbouwen vanaf nul.
Beoordeel je startpunt
Oké, dus je hebt alles geprobeerd en de PDF is alles wat je hebt. Wat nu? Je volgende stap is om precies uit te zoeken wat voor soort PDF je hebt. Een schone, digitaal gemaakte PDF is een volledig ander dier dan een wazige, gescande.
Een snelle manier om dit te testen is het document openen en proberen de tekst met je cursor te markeren. Als je individuele woorden en zinnen kunt selecteren, zit je goed. Dit betekent dat de tekst 'live' is en waarschijnlijk schoon kan worden geëxtraheerd.
Als je niets kunt selecteren, heb je een op afbeeldingen gebaseerde PDF in handen, wat betekent dat je naar de OCR-stap gaat. Het succes van dat proces hangt volledig af van de kwaliteit van de scan.
- Controleer op helderheid en resolutie: Zijn de letters scherp en duidelijk, of zien ze er wat fuzzy uit? Scans met hoge resolutie geven OCR-software veel meer kans om het goed te doen.
- Zoek naar complexe lay-outs: Zorg voor lastige opmaak. Dingen zoals meerdere kolommen, tekst die rond afbeeldingen loopt, en veel tabellen kunnen extractietools gemakkelijk in verwarring brengen.
- Identificeer handgeschreven notities: OCR-technologie is notoir slecht in het lezen van handschrift. Alle gekrabbelde notities of markeringen zullen bijna zeker handmatig moeten worden uitgetypt.
Bereid je voor op consistentie en plan voor ontwerp
Voordat één woord wordt vertaald, moet je nadenken over consistentie. Dit is waar een woordenboek, of termbase, van pas komt. Dit is gewoon een lijst met de sleuteltermen van je boek—denk karakternamen, unieke concepten of merkgebonden frasen—samen met hun vooraf goedgekeurde vertalingen. Dit aan je vertaler geven is cruciaal voor het behouden van consistentie over alle 400+ pagina's, wat een van de grootste aanwijzingen is van een professioneel werk.
Een veelvoorkomende valkuil is denken dat het werk klaar is zodra de vertaling is voltooid. In werkelijkheid is dat slechts de helft van de strijd. Het opnieuw opbouwen van het ontwerp en de lay-out van het boek is een afzonderlijke, en vaak even intensieve, taak.
Tot slot, vergeet niet om tijd en middelen in te plannen voor wat bekend staat als Desktop Publishing (DTP). Talen nemen zelden dezelfde hoeveelheid ruimte in beslag. Een vertaling van Engels naar Duits kan bijvoorbeeld vaak tot 30% langer zijn. Een professionele ontwerper zal terug moeten gaan, de lay-out aanpassen zodat de nieuwe tekst past, alle afbeeldingen opnieuw invoegen, en ervoor zorgen dat het uiteindelijke boek er net zo verzorgd uitziet als het origineel. DTP van dag één inplannen bespaart je nare verrassingen later en zorgt ervoor dat je vertaalde boek iets is waar je trots op kunt zijn.
Waarom EPUB de slimmere keuze is voor boekvertaling
Na worstelen met de lastige, vaak frustrerende wereld van computer assisted translation PDF workflows, wordt het vrij duidelijk dat er een betere manier moet zijn. En gelukkig is die er. De oplossing is om helemaal aan het begin met een EPUB-bestand te beginnen, wat bijna alle pijnlijke handmatige stappen omzeilt die we zojuist hebben behandeld.
Denk eraan als volgt: een PDF is eigenlijk een digitale foto van een pagina. De tekst is in de afbeelding verflakt, wat het een echte kopzorg maakt om uit te pakken of te veranderen. Een EPUB is daarentegen meer als een dynamisch Word-document. Het is gebouwd om flexibel te zijn, waardoor tekst en afbeeldingen kunnen refloweren en zich aanpassen aan elk scherm—of elke taal.
Deze ingebouwde aanpassingsvermogen is een enorme winst voor auteurs en vertalers. Wanneer je een EPUB gebruikt, kun je vergeten over onhandige tekstextractie of rommelige OCR-conversies. De volledige structuur van je boek—elk hoofdstuk, elke kop—is al perfect behouden.
Het structurele voordeel van EPUB
De magie van het EPUB-formaat ligt in hoe het de blauwdruk van je boek vasthoudt. Het begrijpt wat een hoofdstuk is, wat een kop is, en