
번역 정확도 메트릭: 설명
번역 정확도 메트릭은 기계 번역이 인간이 만든 참조 자료와 얼마나 잘 일치하는지 평가하는 데 도움이 됩니다. 이러한 도구는 특히 대규모 프로젝트나 중요한 콘텐츠를 다룰 때 번역 품질을 평가하는 데 중요합니다. 메트릭은 세 가지 범주로 나뉩니다:
- 문자열 기반 메트릭: BLEU, METEOR, 그리고 TER은 단어나 문자 겹침에 초점을 맞춥니다.
- 신경 기반 메트릭: COMET과 BERTScore는 AI 모델을 사용하여 의미론적 유사성을 분석합니다.
- 인간 평가: MQM과 같은 직접 평가는 적절성과 유창성에 초점을 맞춥니다.
주요 요점:
- BLEU: 빠르고 간단하지만 동의어와 깊은 의미에서 어려움을 겪습니다.
- METEOR: 동의어와 언어적 뉘앙스를 고려합니다. 문학 작품에 더 적합합니다.
- TER: 편집 노력을 측정하지만 의미론적 품질을 무시합니다.
- COMET & BERTScore: 인간의 판단과 밀접하게 일치하는 고급 AI 모델로, 뉘앙스가 있는 텍스트에 적합합니다.
책 번역의 경우 자동화된 도구와 인간 평가를 결합하면 정확성을 보장하고 원본의 스타일을 보존합니다. BookTranslator.ai와 같은 플랫폼은 이러한 하이브리드 접근 방식을 사용하여 99개 이상의 언어로 신뢰할 수 있는 결과를 제공합니다.
일반적인 번역 정확도 메트릭
BLEU 점수
2002년에 도입된 BLEU (Bilingual Evaluation Understudy)는 기계 번역 평가를 위한 주요 메트릭입니다 [4]. 이는 n-gram 정확도를 비교하여 작동하며, 기계의 출력에서 단어 시퀀스가 참조 번역과 어떻게 일치하는지 분석합니다. BLEU 점수는 0에서 1 사이이며, 더 높은 숫자는 더 나은 품질을 나타냅니다. 가장 큰 장점은 무엇일까요? 속도와 단순성 - BLEU는 수천 개의 번역을 빠르게 처리할 수 있어 매우 실용적입니다. 이러한 효율성으로 인해 NAACL 2018 Test-of-Time 상을 받았습니다.
Papineni 등이 설명한 바와 같이, "핵심 아이디어는 시스템의 번역과 인간 참조 번역 세트 간의 가변 길이 n-gram 일치의 가중 평균을 사용하는 것입니다" [4].
하지만 BLEU에는 주목할 만한 제한이 있습니다: 정확한 단어 일치를 우선시합니다. 이는 같은 의미를 전달하지만 다른 표현을 사용하는 번역의 가치를 과소평가할 수 있습니다. 이를 해결하기 위해 METEOR와 같은 메트릭은 언어적 뉘앙스를 포착하려고 합니다.
METEOR 메트릭
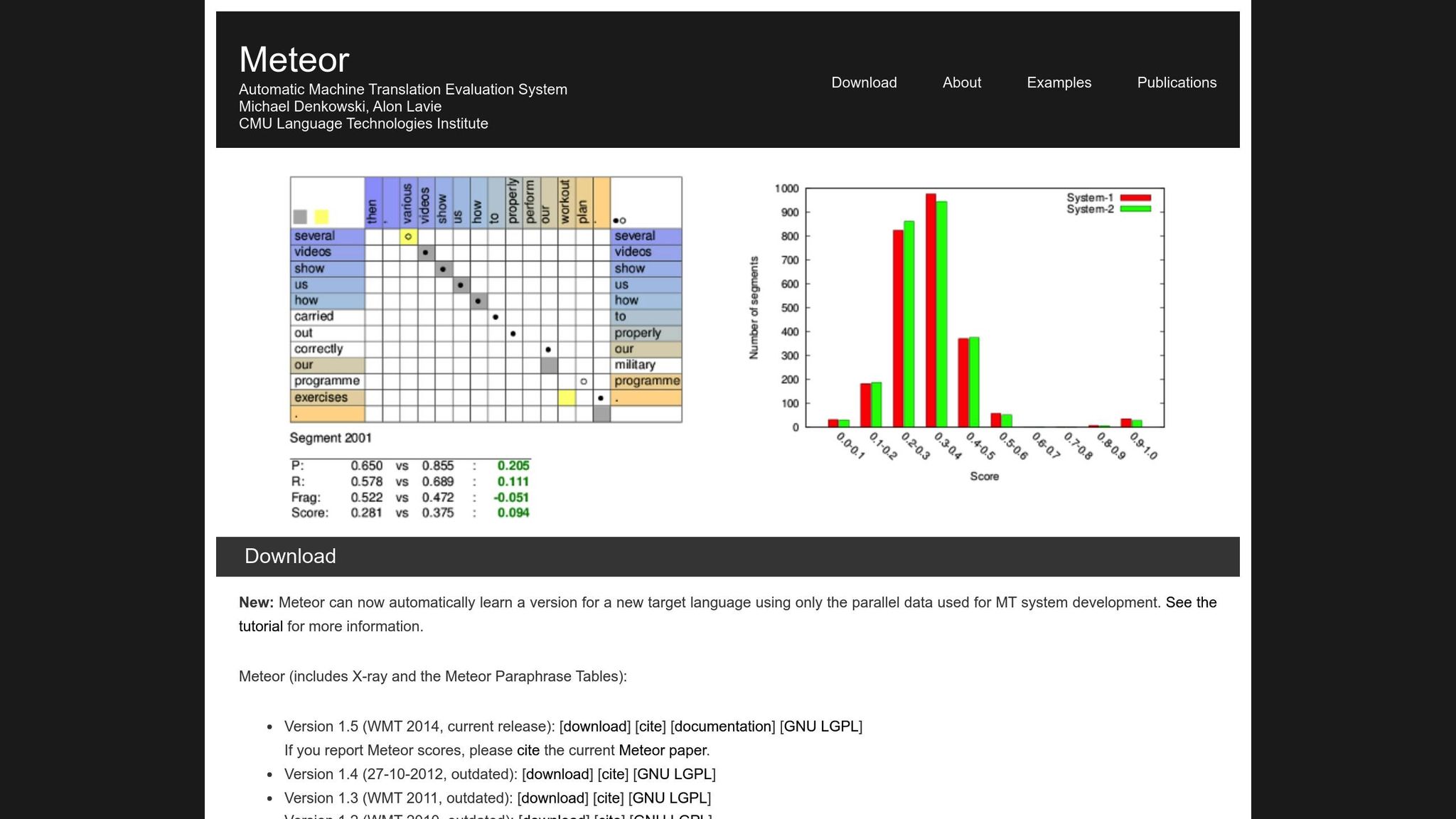
METEOR (Metric for Evaluation of Translation with Explicit ORdering)는 정확도, 재현율, 동의어, 어간 추출 및 단어 순서 페널티를 고려하여 BLEU를 개선합니다 [1]. "running" 대 "ran" 또는 "happy" 대 "joyful"과 같은 변형을 처리하므로, 의미가 가장 중요한 번역에 더 적합합니다. 예를 들어, NIST MetricsMaTr10 챌린지 중에 METEOR‑next‑rank는 시스템 수준에서 0.92, 문서 수준에서 0.84의 Spearman's rho 상관관계를 달성했습니다 [1].
그렇긴 하지만, METEOR는 고유한 문제를 가지고 있습니다. 동의어 데이터베이스 및 어간 추출 알고리즘과 같은 추가 리소스가 필요하여 계산 부하가 증가합니다. 그럼에도 불구하고, 특히 의미론적 정확성을 포착하기 위해 더 뉘앙스 있고 신뢰할 수 있는 평가를 제공합니다.
번역 편집률 (TER)
TER는 기계 출력을 참조로 변환하는 데 필요한 편집(삽입, 삭제, 대체 및 이동) 수를 계산하여 번역 품질을 평가합니다. 이는 출력을 원하는 결과와 일치시키는 데 필요한 편집 노력을 측정하는 데 특히 유용합니다. MetricsMaTr10 평가에서 TER-v0.7.25는 의미론적 적절성에 대한 인간 평가와 시스템 수준에서 0.89의 상관관계를 보였으며, TERp는 세그먼트 수준에서 0.68의 상관관계를 보였습니다 [1].
신경 기반 메트릭: BERTScore, COMET, 그리고 GEMBA
신경 기반 메트릭은 정확한 단어 일치보다는 의미론적 분석에 초점을 맞추어 번역 평가를 다음 단계로 가져갑니다. 빠른 분석은 다음과 같습니다:
- BERTScore: 문맥적 임베딩을 사용하여 번역 간의 유사성을 측정합니다.
- COMET: 소스 텍스트, 가설 및 참조 번역을 인간 주석으로 학습된 신경 프레임워크에 통합합니다. 인간 품질 판단과 가장 높은 상관관계 중 일부를 달성했습니다 [5].
- GEMBA: 대규모 언어 모델을 활용하여 제로샷 품질 추정을 제공하며, 인간 평가에 더 가까운 근사를 제공합니다.
이러한 메트릭은 강력하지만 트레이드오프가 있습니다. BLEU와 TER와 달리, 밀리초 단위로 표준 CPU에서 실행될 수 있으며, BERTScore 및 COMET과 같은 신경 기반 메트릭은 대규모 데이터세트를 효율적으로 처리하기 위해 GPU 가속이 필요한 경우가 많습니다. 특히 GEMBA는 높은 API 비용 및 대규모 언어 모델의 잠재적 편향을 포함할 수 있어 일부 사용자에게는 접근성이 떨어집니다.
MT 시스템 평가를 위한 자동 메트릭
번역 메트릭 비교

번역 정확도 메트릭 비교: BLEU, METEOR, TER, BERTScore, COMET 및 GEMBA
메트릭 비교 테이블
올바른 번역 메트릭을 선택하는 것은 평가의 초점과 보유한 리소스에 따라 달라집니다. BLEU와 같은 전통적인 메트릭은 빠르고 최소한의 리소스가 필요하지만 더 깊은 의미론적 의미를 포착하기 어렵습니다. 반면에 신경 메트릭은 문맥과 의미를 이해하는 데 탁월하지만 더 많은 계산 능력이 필요합니다.
최근 연구는 겹침 기반 메트릭에서 벗어날 것을 제안합니다. 예를 들어, WMT22의 결과는 신경 접근 방식을 선호하여 BLEU와 같은 메트릭을 포기할 것을 권장합니다 [6]. 이 연구는 BLEU, spBLEU 및 chrF와 같은 겹침 메트릭이 인간 전문가 평가와 상관관계가 낮다는 것을 강조합니다.
주요 번역 메트릭의 빠른 비교는 다음과 같으며, 초점 영역, 점수 방법, 인간 평가 상관관계, 제한 사항 및 책 번역에 대한 적절성을 다룹니다:
| 메트릭 | 초점 영역 | 점수 범위 | 인간 평가와의 상관관계 | 제한 사항 | 책 번역에 대한 적절성 |
|---|---|---|---|---|---|
| BLEU | N-gram 정확도 | 0에서 1 (또는 0-100) | 낮음에서 중간 | 동의어에서 어려움 [7][8] | 낮음; 문학 스타일을 포착할 능력 부족 |
| METEOR | 정확도, 재현율, 동의어, 단어 순서 | 0에서 1 | 높음 | 언어별 리소스 필요 [7] | 중간; 일관된 용어에 유용 |
| TER | 편집 거리 (사후 편집 노력) | 0에서 1 (낮을수록 좋음) | 중간 | 의미론적 품질 무시 [7] | 낮음; 기계적 측면에 초점, "목소리" 아님 |
| BERTScore | 문맥적 임베딩을 통한 의미론적 유사성 | 0에서 1 | 높음 | 리소스 집약적 [7] | 높음; 더 깊은 의미와 문맥 포착 |
| COMET | 의미론적 유사성과 유창성 | 0에서 1 (0.5-0.8 전형) | 매우 높음 | 사전 학습된 모델 필요 [7][8] | 높음; 스타일과 뉘앙스 있는 의미 보존 |
| GEMBA | 전체 LLM 기반 평가 | 다양함 | 높음 | 복잡한 설정; 비용이 많이 드는 API [7] | 높음; "인간 같은" 종합적인 검토 제공 |
이 표는 다양한 메트릭이 특정 번역 필요와 어떻게 일치하는지를 강조합니다. 기술 번역의 경우 BLEU 및 TER과 같은 메트릭은 빠르고 기본적인 벤치마크를 제공합니다. 그러나 문학 번역의 경우 - 스타일, 톤 및 뉘앙스 있는 의미가 중요한 경우 - BERTScore 및 COMET과 같은 신경 메트릭이 훨씬 더 잘 수행됩니다. 이러한 도구는 특히 문학 텍스트의 깊이와 예술성을 포착하는 데 능숙하며, 이는 전통적인 메트릭이 종종 간과합니다 [7].
예를 들어, 효율성과 품질의 균형을 맞추는 것을 목표로 하는 BookTranslator.ai와 같은 플랫폼은 신경 메트릭의 이점을 크게 누립니다. BERTScore 및 COMET
관점을 제시하기 위해, "좋은" BLEU 점수는 일반적으로 30에서 40 사이이며, 40을 초과하는 점수는 강력한 것으로 간주되고, 50 이상은 고품질 번역을 나타냅니다 [8]. COMET의 경우, 점수는 일반적으로 0.5에서 0.8 사이이며, 1.0에 더 가까운 값은 거의 인간 수준의 번역 품질을 반영합니다 [8]. 신경 메트릭은 다양한 텍스트 유형에서 일관되게 수행될 뿐만 아니라 BLEU와 같은 도메인 민감 메트릭에 비해 다양한 문맥에 더 잘 적응합니다 [6].
sbb-itb-0c0385d
인간 평가 방법
자동화된 메트릭은 속도와 일관성을 제공할 수 있지만, 번역 품질을 정의하는 미묘한 세부 사항을 종종 놓칩니다. 이것이 인간 평가가 금본위제로 작용하는 곳입니다[2]. 비록 더 느리고 비용이 많이 들지만, 인간 평가는 BLEU나 COMET과 같은 메트릭이 단순히 식별할 수 없는 품질 문제의 더 깊은 이유를 드러냅니다[9].
인간 평가에는 두 가지 주요 접근 방식이 있습니다. 하나는 직접 표현된 판단 (DEJ)으로, 번역이 유창성 및 적절성과 같은 척도에서 평가됩니다. 다른 하나는 비DEJ 방법으로, 특정 오류를 찾아내고 분류하는 데 초점을 맞추며, 종종 MQM과 같은 프레임워크를 사용합니다[12]. 분석 방법이 개별 오류와 그 심각도를 분석하는 동안, 전체적 방법은 전반적인 품질을 봅니다. 이러한 접근 방식들은 함께 MQM과 같은 프레임워크의 백본을 형성합니다.
MQM (다차원 품질 메트릭)

자동화된 도구가 부족할 때, MQM은 더 상세하고 실행 가능한 대안을 제공합니다. 단일 숫자로 품질을 요약하는 대신, 정확도, 유창성, 용어, 로케일 규칙 및 디자인/마크업과 같은 범주로 번역 오류를 분류합니다[18, 17].
"대조적으로, 자동화된 메트릭은 일반적으로 결과를 개선하는 방법에 대한 표시 없이 단순히 숫자를 제공합니다."
– MQM 위원회[10]
오류는 심각도별로 평가됩니다: 중립적 (표시되지만 허용 가능, 페널티 없음), 경미 (약간 눈에 띔, 페널티 가중치 1), 주요 (이해에 영향, 페널티 가중치 5), 그리고 심각 (텍스트를 사용 불가능하게 만듦, 페널티 가중치 25)[11].