
Por qué METEOR es importante para la traducción de libros con IA
METEOR, abreviatura de Metric for Evaluation of Translation with Explicit ORdering (Métrica para la Evaluación de Traducciones con Ordenamiento Explícito), es una herramienta de evaluación de traducciones que prioriza el significado y la fluidez de las oraciones sobre las coincidencias exactas de palabras. A diferencia de BLEU, que se basa en la alineación estricta palabra por palabra, METEOR utiliza técnicas como la lematización, la coincidencia de sinónimos y la paráfrasis para evaluar mejor la calidad de las traducciones. Esto lo hace especialmente efectivo para traducir libros, donde capturar la voz del autor, el tono y el flujo narrativo es crítico.
Puntos clave:
- Por qué BLEU se queda corto: El enfoque estricto de BLEU en coincidencias exactas de palabras penaliza alternativas válidas, tiene dificultades con sinónimos y no logra evaluar la coherencia narrativa, lo que lo hace inadecuado para la literatura.
- Cómo funciona METEOR: METEOR alinea traducciones utilizando coincidencias exactas, raíces de palabras, sinónimos y paráfrasis. Prioriza el recall (cobertura de significado) sobre la precisión y aplica penalizaciones por mal orden de palabras.
- Desempeño: METEOR logra una correlación de 0.964 con el juicio humano a nivel de corpus, superando el 0.817 de BLEU.
- Impacto en las traducciones de libros: Al enfocarse en el significado y la fluidez, METEOR asegura que las traducciones retengan la profundidad y legibilidad del texto original, lo que la hace ideal para traducciones literarias impulsadas por IA.
Para plataformas como BookTranslator.ai, METEOR permite traducciones de alta calidad en más de 99 idiomas por tan solo $5.99 por cada 100,000 palabras, haciendo la literatura accesible a una audiencia global.
Problemas al evaluar traducciones de libros con IA
Por qué BLEU falla en traducciones de formato largo
BLEU (Bilingual Evaluation Understudy), una métrica introducida en 2002, se basa en la coincidencia estricta de n-gramas, que a menudo no logra capturar las sutilezas de la traducción literaria.
El meollo del problema radica en el enfoque de BLEU: evalúa la calidad haciendo coincidir secuencias de 1 a 4 palabras exactamente como aparecen en una referencia humana. Este método rígido tiene dificultades con la flexibilidad creativa requerida para traducir literatura. Como explica el equipo de NLLB:
"BLEU penaliza traducciones alternativas válidas. Si la referencia dice 'el coche es rojo' y el sistema produce 'el automóvil es rojo', BLEU penaliza la discrepancia aunque el significado sea idéntico" [4].
Esta incapacidad de reconocer sinónimos es particularmente problemática para los libros, donde la elección de palabras a menudo tiene un peso significativo. Por ejemplo, BLEU trata "grande" y "amplio" como palabras completamente diferentes, aunque signifiquen lo mismo. De manera similar, no cuenta para variaciones como "corriendo", "corre" y "corrió", a menudo penalizando traducciones que son tanto precisas como creativas.
Otra limitación fundamental es el diseño a nivel de corpus de BLEU. Fue desarrollado originalmente para manejar grandes conjuntos de datos, no la precisión a nivel de oración crítica para la literatura. BLEU también carece de la capacidad de evaluar la fluidez de las oraciones o la coherencia narrativa. Como señala NLLB:
"BLEU no cuenta la fluidez o la preservación del significado directamente - es puramente una medida de superposición de n-gramas" [4].
Esto significa que una traducción podría técnicamente incluir todas las palabras correctas pero organizarlas en un orden desordenado y incómodo - y aún así obtener una buena puntuación. Estas deficiencias destacan la necesidad de métodos de evaluación que prioricen el contexto, la coherencia y la experiencia narrativa general.
Por qué el contexto y el significado importan en los libros
Los libros son más que solo colecciones de oraciones - son narrativas intrincadas donde cada palabra, estructura de oración y elección estilística juega un papel en la formación de la experiencia del lector. El enfoque estrecho de BLEU en coincidencias exactas de palabras se pierde esta visión más amplia, especialmente cuando se trata de mantener el flujo narrativo y la coherencia.
La brecha de comprensión semántica es particularmente evidente. Michael Brenndoerfer señala:
"Dos traducciones semánticamente equivalentes podrían recibir puntuaciones BLEU muy diferentes dependiendo de sus opciones de palabras específicas" [5].
Esto crea un incentivo problemático para que los sistemas de IA busquen coincidencias exactas de palabras en lugar de esforzarse por la precisión semántica o la fluidez natural.
La traducción literaria exige un equilibrio entre precisión y recall - no solo evitar errores sino también preservar la profundidad, el tono y la resonancia emocional del texto original. BLEU enfatiza fuertemente la precisión, pero los libros requieren métricas que midan si la traducción captura la intención del autor y el flujo narrativo. Herramientas como METEOR, que priorizan el significado y la fluidez ponderando el recall nueve veces más que la precisión, ofrecen un enfoque más apropiado para evaluar traducciones literarias [1].
sbb-itb-0c0385d
METEOR : Una métrica para la traducción automática
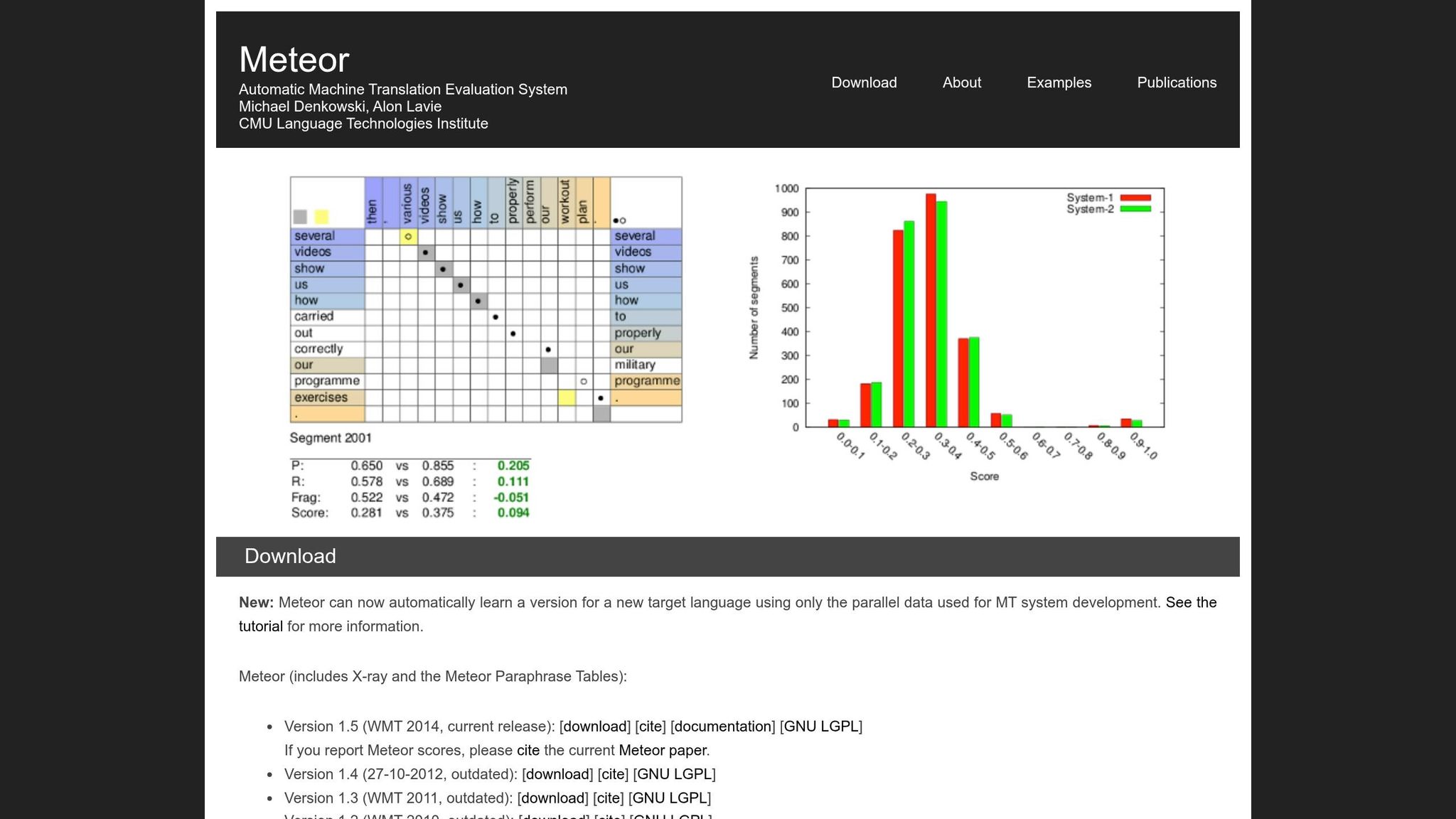
¿Qué es METEOR y cómo funciona?
METEOR, abreviatura de Metric for Evaluation of Translation with Explicit ORdering, fue introducido en 2005 por los investigadores Satanjeev Banerjee y Alon Lavie en la Universidad Carnegie Mellon. Fue desarrollado para abordar algunas de las limitaciones de BLEU, particularmente su coincidencia rígida palabra por palabra. METEOR se enfoca en preservar el significado y el orden natural de las palabras, lo que lo hace especialmente útil para evaluar traducciones que necesitan mantener el flujo narrativo - como las traducciones de libros.
La métrica funciona alineando palabras individuales en la traducción candidata con las de la traducción de referencia. Cuando hay múltiples formas de alinear las palabras, METEOR elige la que tiene el menor número de "cruces" (intersecciones entre líneas de mapeo). Este enfoque ayuda a mantener un orden de palabras más natural en el proceso de evaluación [1].
Características principales de METEOR
METEOR destaca por su enfoque de coincidencia por niveles, que va más allá de la coincidencia exacta de palabras. Utiliza cuatro módulos secuenciales para evaluar traducciones:
- Coincidencia exacta: Coincide formas de palabras idénticas.
- Lematización: Coincide palabras que comparten la misma raíz, como "corriendo" y "corre".
- Sinonimia: Reconoce palabras con significados similares utilizando WordNet.
- Coincidencia de paráfrasis: Coincide frases con contenido semántico similar.
Este enfoque en capas aborda la dificultad de BLEU para tener en cuenta variaciones de palabras válidas y expresiones alternativas [1][2][6].
El sistema de puntuación de METEOR combina dos elementos clave. Primero, calcula una media F ponderada de precisión y recall, siendo el recall ponderado nueve veces más fuertemente que la precisión. Esto refleja cómo los humanos tienden a evaluar la calidad de la traducción, priorizando la cobertura del significado original sobre las coincidencias exactas [1]. Segundo, aplica una penalización por fragmentación para desalentar traducciones donde las palabras coincidentes están dispersas o fuera de orden. Si las palabras coincidentes se dividen en demasiados "fragmentos", la puntuación puede ser penalizada hasta en un 50%. Esto asegura que las traducciones con palabras correctas pero estructura pobre - a menudo denominadas "ensalada de palabras" - reciban puntuaciones más bajas [1].
Cómo METEOR se alinea con el juicio humano
Los estudios muestran que METEOR se correlaciona con el juicio humano mejor que BLEU, logrando coeficientes de correlación entre 0.60 y 0.75, en comparación con el rango de 0.45 a 0.60 de BLEU [6].
Esta alineación más fuerte se debe en gran parte al enfoque a nivel de oración de METEOR. Mientras que BLEU está diseñado para evaluar traducciones a nivel de corpus, METEOR evalúa oraciones o segmentos individuales. Esto lo hace particularmente efectivo para evaluar el flujo y la coherencia necesarios en las traducciones de libros [1]. Además, METEOR puede procesar hasta 500 segmentos por segundo por núcleo de CPU, lo que lo hace eficiente y confiable para uso práctico [2]. Su capacidad de alinearse estrechamente con el juicio humano ha solidificado su papel en la mejora de las traducciones de libros impulsadas por IA.
METEOR vs. BLEU: Por qué METEOR funciona mejor para la traducción de libros con IA

Comparación de métricas de traducción METEOR vs BLEU
Ventajas clave de METEOR para la traducción de libros
Cuando se trata de traducir obras literarias, METEOR destaca como una métrica de evaluación más efectiva que BLEU. Sus métodos de alineación únicos y enfoque en el significado la hacen especialmente adecuada para los matices de la traducción de libros.
Una de las principales diferencias es cómo cada métrica maneja la precisión semántica. BLEU se basa en coincidencias exactas de palabras, que pueden penalizar injustamente traducciones que utilizan sinónimos o formas de palabras alternativas - incluso cuando el significado permanece intacto. METEOR, por otro lado, incorpora lematización y coincidencia de sinónimos. Por ejemplo, reconoce que palabras como "bueno" y "bien" o "corre" y "corriendo" comparten el mismo valor semántico. Esta flexibilidad es esencial para las traducciones literarias, donde el vocabulario diverso y las frases creativas a menudo son necesarios para preservar el estilo e intención del autor.
Otra distinción importante es el énfasis de METEOR en recall sobre precisión. BLEU prioriza la precisión midiendo cuántas palabras en la traducción generada por IA coinciden con las del texto de referencia. METEOR, sin embargo, equilibra precisión y recall, con recall ponderado nueve veces más fuertemente [1]. Esto asegura que la traducción capture el significado completo del texto original - un factor crítico para transmitir con precisión narrativas complejas.
METEOR también destaca en la evaluación a nivel de oración. Mientras que BLEU está adaptado para evaluar traducciones a nivel de corpus, METEOR está diseñado para alinearse estrechamente con el juicio humano en oraciones o segmentos individuales. Logra una correlación máxima de aproximadamente 0.403 a nivel de oración [1]. Esto lo hace particularmente efectivo para evaluar el flujo y la coherencia de pasajes específicos, que es clave en la traducción de libros.
Una de las características destacadas de METEOR es su penalización por fragmentación, que aborda el orden de palabras y la estructura de las oraciones. Si las palabras coincidentes en la traducción se dispersan en demasiados fragmentos, la puntuación puede caer hasta un 50% [1]. Este mecanismo asegura que las traducciones mantengan una estructura natural y coherente - algo que BLEU a menudo pasa por alto. Al enfocarse en estos detalles, METEOR ayuda a preservar el significado matizado y la legibilidad del texto original.
Tabla de comparación: METEOR vs. BLEU
| Característica | BLEU | METEOR |
|---|---|---|
| Enfoque principal | Precisión (superposición exacta de palabras) | Recall (cobertura de significado y contenido) |
| Criterios de coincidencia | Coincidencia exacta de n-gramas | Exacta, lematización, sinónimos y paráfrasis |
| Precisión semántica | Baja (solo coincidencias exactas de palabras) | Alta (incluye sinónimos y lematización) |
| Correlación humana | Más fuerte a nivel de corpus | Fuerte a nivel de oración y corpus |
| Estructura de oración | Indirecta (mediante superposiciones de n-gramas) | Directa (mediante penalización por fragmentación y alineación) |
| Flexibilidad | Rígida; penaliza frases creativas | Flexible; recompensa equivalencia semántica |
| Manejo de recall | Indirecta (penalización por brevedad) | Directa (cálculo de recall ponderado 9x más) |
Cómo se utiliza METEOR en plataformas de traducción de libros con IA
Asegurando calidad con METEOR
Las plataformas de traducción impulsadas por IA aprovechan METEOR para mantener la precisión semántica y preservar los matices delicados de las obras literarias. El proceso comienza con el mapeo de alineación, donde el sistema identifica conexiones entre la traducción generada por IA y un texto de referencia. Esto implica reconocer coincidencias exactas, raíces de palabras, sinónimos e incluso paráfrasis [2]. Tal mapeo detallado asegura que la traducción refleje el significado original, incluso si la redacción difiere.
Para manejar las complejidades de diferentes idiomas, METEOR se configura con herramientas específicas del idioma como lematizadores y tablas de paráfrasis. Por ejemplo, plataformas como BookTranslator.ai, que soporta más de 99 idiomas, utilizan estos recursos para abordar las estructuras lingüísticas únicas de idiomas diversos. Ya sean idiomas románicos como el español y el francés u otros más intrincados como el árabe y el checo, estas herramientas son vitales para capturar variaciones morfológicas [2].
Lo que distingue a METEOR es su capacidad de ajustar parámetros. Las plataformas pueden calibrar estos ajustes para alinearse con tareas de evaluación específicas, como medir la adecuación o mantener un estilo consistente. Esta característica es particularmente valiosa en traducciones literarias, donde preservar la voz del autor y el ritmo de la narrativa es esencial. Además, la penalización por fragmentación del sistema asegura que las oraciones fluyan naturalmente, evitando la sensación incómoda y desarticulada de una mera cadena de palabras correctas. Esta atención a la fluidez de las oraciones es crítica para mantener a los lectores absortos en la historia durante cientos de páginas.
Más allá de mejorar la calidad de las traducciones, METEOR también juega un papel fundamental en hacer que la literatura sea más accesible para una audiencia global.
Mejorando el acceso multilingüe a la literatura
Al salvaguardar el significado y la profundidad del texto original, METEOR no solo mejora la calidad de la traducción sino que también ayuda a llevar la literatura a lectores en sus idiomas nativos. Utilizando datos paralelos, METEOR permite que las plataformas expandan sus ofertas de idiomas sin sacrificar la calidad [2]. Esta capacidad de adaptación es especialmente importante para lectores en mercados de idiomas subrepresentados.
El enfoque de evaluación centrado en el humano asegura que las traducciones se sientan naturales y atractivas. Por ejemplo, plataformas como BookTranslator.ai proporcionan traducciones comenzando en $5.99 por cada 100,000 palabras, manteniendo traducciones de alta calidad asequibles mientras se retiene el encanto narrativo de la historia y las sutilezas culturales. Al priorizar el recall sobre la precisión, METEOR captura la riqueza del texto fuente, incluyendo arcos de personajes intrincados y capas temáticas que son esenciales para la narración convincente.
Conclusión
METEOR está cambiando el juego en la evaluación de traducciones de libros con IA al priorizar la precisión semántica y la legibilidad natural. A diferencia de las métricas tradicionales, METEOR tiene en cuenta sinónimos, raíces de palabras y paráfrasis, logrando una impresionante correlación de 0.964 con el juicio humano a nivel de corpus - significativamente más alta que el 0.817 de BLEU [1]. Esto asegura que las traducciones retengan el estilo del autor, la consistencia narrativa y elementos culturales sutiles.
Lo que distingue a METEOR es su puntuación ponderada por recall combinada con una penalización por fragmentación, que asegura que las traducciones no solo capturen el significado completo del texto original sino que también lean fluidamente. Esto es especialmente crítico para contenido de formato largo, donde mantener la coherencia y el flujo en una narrativa extensa es esencial.
Para plataformas como BookTranslator.ai, que soportan más de 99 idiomas, la capacidad de METEOR de reconocer variaciones lingüísticas permite traducciones de alta calidad a precios competitivos - comenzando en solo $5.99 por cada 100,000 palabras. Al aprovechar datos paralelos para aprender nuevos idiomas de destino [2], METEOR abre la puerta para que lectores en regiones desatendidas accedan a la literatura en sus idiomas nativos.
"METEOR funciona más como sistemas modernos de reconocimiento de voz que entienden diferentes formas de decir lo mismo. Evalúa traducciones con flexibilidad, reflejando el juicio humano." - Iterate.ai [3]
Preguntas frecuentes
¿Es METEOR suficiente para juzgar la calidad de la traducción de un libro?
METEOR es una herramienta útil para medir la calidad de la traducción, especialmente cuando se trata de identificar matices semánticos y detalles lingüísticos. Sin embargo, confiar únicamente en ella no es suficiente para evaluar completamente la calidad de la traducción de un libro. Emparejar METEOR con evaluaciones humanas ofrece una forma más equilibrada y exhaustiva de evaluar la calidad de la traducción.
¿Cómo maneja METEOR los modismos y las frases creativas?
METEOR aborda los desafíos de los modismos y las frases creativas a través de la coincidencia de sinónimos, la lematización y la evaluación lingüística adaptable. Estas herramientas le permiten comprender expresiones sutiles y no literales, asegurando que las traducciones preserven tanto el significado previsto como el estilo original.
¿Puede METEOR detectar problemas de consistencia en toda una novela?
METEOR es capaz de detectar problemas de consistencia en una novela examinando similitudes semánticas y detalles lingüísticos en todo el texto. Esto ayuda a asegurar que la traducción preserve un significado, tono y estilo consistentes en todo el libro.