
Métricas de Precisión de Traducción: Explicadas
Las métricas de precisión de traducción ayudan a evaluar qué tan bien las traducciones automáticas coinciden con referencias creadas por humanos. Estas herramientas son cruciales para evaluar la calidad de la traducción, especialmente cuando se manejan proyectos a gran escala o contenido de alto riesgo. Las métricas se dividen en tres categorías:
- Métricas Basadas en Cadenas: BLEU, METEOR, y TER se centran en la superposición de palabras o caracteres.
- Métricas Basadas en Redes Neuronales: COMET y BERTScore analizan la similitud semántica utilizando modelos de IA.
- Evaluaciones Humanas: Evaluaciones directas como MQM se centran en la adecuación y fluidez.
Puntos clave:
- BLEU: Rápido y simple pero tiene dificultades con sinónimos y significado más profundo.
- METEOR: Tiene en cuenta sinónimos y matices lingüísticos; mejor para obras literarias.
- TER: Mide el esfuerzo de edición pero ignora la calidad semántica.
- COMET y BERTScore: Modelos avanzados de IA que se alinean estrechamente con el criterio humano, excelentes para textos matizados.
Para traducciones de libros, combinar herramientas automatizadas con evaluaciones humanas garantiza la precisión y preserva el estilo original. Plataformas como BookTranslator.ai utilizan este enfoque híbrido para entregar resultados confiables en más de 99 idiomas.
Métricas Comunes de Precisión de Traducción
Puntuación BLEU
Introducida en 2002, BLEU (Bilingual Evaluation Understudy) sigue siendo una métrica de referencia para evaluar la traducción automática [4]. Funciona comparando precisión de n-gramas, lo que significa analizar cómo las secuencias de palabras en la salida de la máquina se alinean con las traducciones de referencia. Las puntuaciones BLEU oscilan entre 0 y 1, siendo los números más altos indicadores de mejor calidad. ¿Su mayor fortaleza? Velocidad y simplicidad - BLEU puede procesar miles de traducciones rápidamente, lo que la hace altamente práctica. Esta eficiencia incluso le valió el premio NAACL 2018 Test-of-Time.
Como explicaron Papineni et al., "La idea principal es usar un promedio ponderado de coincidencias de n-gramas de longitud variable entre la traducción del sistema y un conjunto de traducciones de referencia humanas" [4].
Sin embargo, BLEU tiene una limitación notable: prioriza coincidencias exactas de palabras. Esto significa que podría subestimar traducciones que transmiten el mismo significado pero utilizan palabras diferentes. Para abordar esto, métricas como METEOR tienen como objetivo capturar matices lingüísticos.
Métrica METEOR
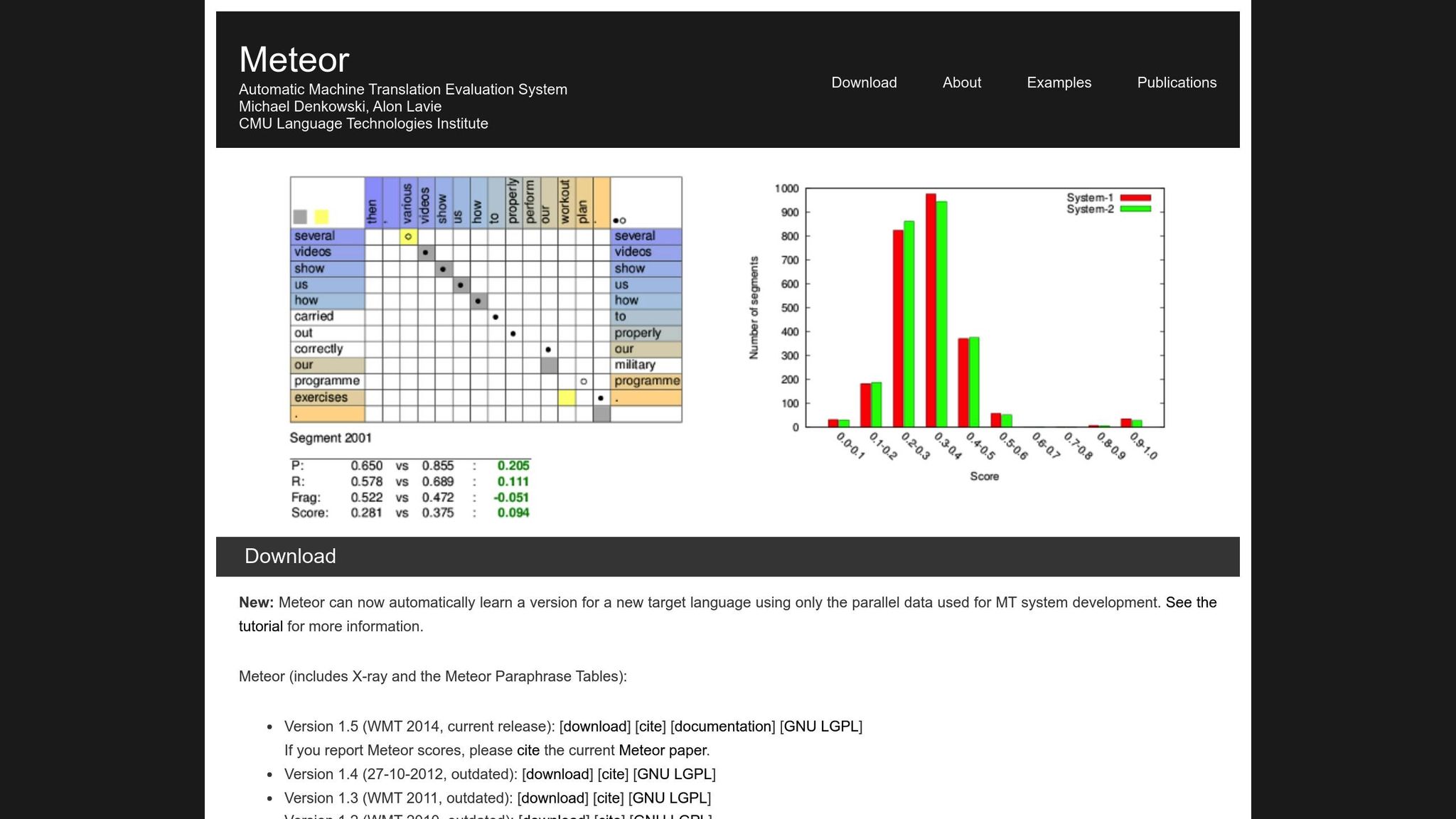
METEOR (Métrica para la Evaluación de Traducción con Orden Explícito) mejora BLEU al considerar precisión, exhaustividad, sinónimos, lematización y penalizaciones de orden de palabras [1]. Maneja variaciones como "corriendo" vs. "corrió" o "feliz" vs. "alegre", lo que la hace más adecuada para traducciones donde el significado es lo más importante. Por ejemplo, durante el desafío NIST MetricsMaTr10, METEOR-next-rank logró una correlación rho de Spearman de 0,92 con los juicios humanos a nivel de sistema y 0,84 a nivel de documento [1].
Dicho esto, METEOR viene con sus propios desafíos. Requiere recursos adicionales, como bases de datos de sinónimos y algoritmos de lematización, lo que aumenta su carga computacional. Aún así, a menudo proporciona una evaluación más matizada y confiable, especialmente para capturar la precisión semántica.
Tasa de Edición de Traducción (TER)
TER evalúa la calidad de la traducción calculando el número de ediciones - inserciones, eliminaciones, sustituciones y cambios - necesarias para transformar la salida de la máquina en la referencia. Esto la hace particularmente útil para medir el esfuerzo de edición requerido para alinear la salida con el resultado deseado. En las evaluaciones MetricsMaTr10, TER-v0.7.25 demostró una correlación a nivel de sistema de 0,89 con las evaluaciones humanas de adecuación semántica, mientras que TERp mostró una correlación a nivel de segmento de 0,68 [1].
Métricas Basadas en Redes Neuronales: BERTScore, COMET, y GEMBA
Las métricas basadas en redes neuronales llevan la evaluación de traducción al siguiente nivel enfocándose en análisis semántico en lugar de coincidencias exactas de palabras. Aquí hay un desglose rápido:
- BERTScore: Utiliza incrustaciones contextuales para medir la similitud entre traducciones.
- COMET: Integra el texto de origen, hipótesis y traducciones de referencia en un marco neuronal entrenado con anotaciones humanas. Ha logrado algunas de las correlaciones más altas con los juicios de calidad humana [5].
- GEMBA: Aprovecha grandes modelos de lenguaje para estimación de calidad sin ejemplos, ofreciendo una aproximación más cercana a la evaluación humana.
Aunque estas métricas son poderosas, vienen con compensaciones. A diferencia de BLEU y TER, que pueden ejecutarse en CPU estándar en milisegundos, las métricas basadas en redes neuronales como BERTScore y COMET a menudo requieren aceleración GPU para manejar conjuntos de datos grandes de manera eficiente. GEMBA, en particular, puede implicar costos de API altos y posibles sesgos de grandes modelos de lenguaje, lo que la hace menos accesible para algunos usuarios.
Métricas Automáticas para Evaluar Sistemas de TA
Comparación de Métricas de Traducción

Comparación de Métricas de Precisión de Traducción: BLEU, METEOR, TER, BERTScore, COMET y GEMBA
Tabla de Comparación de Métricas
Elegir la métrica de traducción correcta a menudo depende del enfoque de su evaluación y de los recursos disponibles. Las métricas tradicionales como BLEU son rápidas y requieren recursos mínimos pero tienen dificultades para capturar significado semántico más profundo. Por otro lado, las métricas neuronales destacan en la comprensión del contexto y el significado pero exigen más potencia computacional.
La investigación reciente sugiere alejarse de las métricas basadas en superposición. Por ejemplo, los hallazgos de WMT22 recomiendan abandonar métricas como BLEU en favor de enfoques neuronales [6]. El estudio destaca que las métricas de superposición como BLEU, spBLEU y chrF tienen una correlación deficiente con las evaluaciones de expertos humanos.
Aquí hay una comparación rápida de métricas clave de traducción, cubriendo sus áreas de enfoque, métodos de puntuación, correlación con evaluación humana, limitaciones e idoneidad para traducciones de libros:
| Métrica | Área de Enfoque | Rango de Puntuación | Correlación con Evaluación Humana | Limitaciones | Idoneidad para Traducciones de Libros |
|---|---|---|---|---|---|
| BLEU | Precisión de n-gramas | 0 a 1 (o 0-100) | Baja a Moderada | Tiene dificultades con sinónimos [7][8] | Baja; carece de capacidad para capturar estilo literario |
| METEOR | Precisión, exhaustividad, sinónimos, orden de palabras | 0 a 1 | Alta | Requiere recursos específicos del idioma [7] | Moderada; útil para terminología consistente |
| TER | Distancia de edición (esfuerzo de post-edición) | 0 a 1 (menor es mejor) | Moderada | Ignora la calidad semántica [7] | Baja; se enfoca en mecánica, no en "voz" |
| BERTScore | Similitud semántica mediante incrustaciones contextuales | 0 a 1 | Alta | Requiere muchos recursos [7] | Alta; captura significado más profundo y contexto |
| COMET | Similitud semántica y fluidez | 0 a 1 (0,5-0,8 típico) | Muy Alta | Requiere modelos pre-entrenados [7][8] | Alta; preserva estilo y significado matizado |
| GEMBA | Evaluación holística basada en LLM | Varía | Alta | Configuración compleja; API costosas [7] | Alta; ofrece una revisión exhaustiva "similar a la humana" |
Esta tabla subraya cómo las diferentes métricas se alinean con necesidades específicas de traducción. Para traducciones técnicas, métricas como BLEU y TER proporcionan puntos de referencia rápidos y básicos. Sin embargo, para traducciones literarias - donde el estilo, el tono y el significado matizado son críticos - las métricas neuronales como BERTScore y COMET funcionan mucho mejor. Estas herramientas son particularmente aptas para capturar la profundidad y el arte de textos literarios, que las métricas tradicionales a menudo pasan por alto [7].
Por ejemplo, plataformas como BookTranslator.ai, que tienen como objetivo equilibrar eficiencia y calidad, se benefician significativamente de métricas neuronales. Herramientas como BERTScore y COMET aseguran que se preserve tanto la precisión semántica como el estilo literario.
Para poner las cosas en perspectiva, una puntuación "buena" de BLEU típicamente cae entre 30 y 40, siendo las puntuaciones superiores a 40 consideradas fuertes, y cualquier cosa superior a 50 indicando traducción de alta calidad [8]. Para COMET, las puntuaciones generalmente oscilan entre 0,5 y 0,8, siendo los valores más cercanos a 1,0 indicadores de calidad de traducción casi humana [8]. Las métricas neuronales no solo funcionan consistentemente en diferentes tipos de texto sino que también se adaptan mejor a contextos variables comparadas con métricas sensibles al dominio como BLEU [6].
sbb-itb-0c0385d
Métodos de Evaluación Humana
Las métricas automatizadas podrían ofrecer velocidad y consistencia, pero a menudo pierden los detalles sutiles que definen la calidad de la traducción. Ahí es donde la evaluación humana interviene como el estándar de oro[2]. Aunque es más lenta y costosa, la evaluación humana descubre las razones más profundas detrás de los problemas de calidad - cosas que métricas como BLEU o COMET simplemente no pueden identificar[9].
Hay dos enfoques principales para la evaluación humana. Uno es Juicio Directamente Expresado (DEJ), donde las traducciones se califican en escalas como fluidez y adecuación. El otro implica métodos no-DEJ, que se centran en detectar y categorizar errores específicos, a menudo utilizando marcos como MQM[12]. Mientras que los métodos analíticos desglosan errores individuales y su gravedad, los métodos holísticos observan la calidad general. Juntos, estos enfoques forman la columna vertebral de marcos como MQM.
MQM (Métricas Multidimensionales de Calidad)

Cuando las herramientas automatizadas se quedan cortas, MQM ofrece una alternativa más detallada y útil. Desglosa errores de traducción en categorías como Precisión, Fluidez, Terminología, Convenciones Locales y Diseño/Marcado, en lugar de resumir la calidad con un solo número[18, 17].
"Por el contrario, las métricas automatizadas típicamente proporcionan solo un número sin indicación de cómo mejorar los resultados."
– Comité MQM[10]
Los errores se califican por gravedad: Neutral (marcado pero aceptable, sin penalización), Menor (ligeramente notable, peso de penalización de 1), Mayor (afecta la comprensión, peso de penalización de 5), y Crítico (hace que el texto sea inutilizable, peso de penalización de 25)[11]. Para traducciones críticas, como documentos legales, los umbrales de aprobación podrían establecerse tan altos como 99,5 en una escala de puntuación bruta[11].
Lo que hace que MQM sea especialmente útil es su capacidad para identificar áreas problemáticas específicas. Por ejemplo, si una traducción literaria obtiene una puntuación baja, MQM puede revelar si el problema radica en una fraseología incómoda o terminología inconsistente. Este nivel de detalle es particularmente valioso para plataformas como BookTranslator.ai, donde capturar tanto el significado como el estilo literario es esencial.
Puntuación de Adecuación y Fluidez
Basándose en marcos estructurados como MQM, los evaluadores también se centran en dos dimensiones clave de la calidad de la traducción: adecuación y fluidez. La adecuación mide qué tan bien la traducción transmite el significado del texto de origen, mientras que la fluidez evalúa qué tan natural y legible es para los hablantes nativos. Estos aspectos a menudo se califican en escalas de cinco puntos[9].
Equilibrar estas dos dimensiones puede ser complicado, especialmente en traducciones literarias. Preservar la voz del autor original mientras se asegura que el texto se lea sin problemas en el idioma de destino requiere atención cuidadosa.
Para refinar este proceso, los evaluadores utilizan Evaluación Directa (DA), que califica traducciones en formatos monolingües, bilingües o basados en referencia[9]. La Métrica de Calidad Escalar (SQM) va un paso más allá con una escala de siete puntos, permitiendo a los evaluadores evaluar segmentos individuales dentro del contexto de todo el documento. Para libros, este enfoque contextual es crítico - la calidad a menudo depende de qué tan bien un capítulo desarrolla personajes o mantiene la continuidad de la trama.
Uso de Métricas para Traducción de Libros
Traducir libros es un desafío único. A diferencia de manuales de instrucciones o materiales de marketing, los libros requieren un equilibrio entre precisión semántica - asegurar que el significado sea correcto - y preservación estilística - mantener la voz y el tono del autor. Evaluar traducciones de libros requiere un enfoque personalizado, con métricas elegidas para adaptarse al tipo específico de contenido que se está traduciendo.
Traducciones Técnicas vs. Literarias
No todas las traducciones de libros tienen los mismos requisitos. Los textos técnicos, como materiales académicos o de instrucción, priorizan la precisión y la consistencia. Para estos, métricas como TER (Tasa de Edición de Traducción) son particularmente efectivas, ya que miden la cantidad de edición necesaria para perfeccionar la traducción.
Las obras literarias, por otro lado, son una historia diferente. Las novelas, memorias y géneros similares dependen en gran medida del flujo narrativo y la resonancia emocional. En estos casos, METEOR destaca porque tiene en cuenta sinónimos y diferencias semánticas sutiles, logrando correlaciones con evaluaciones humanas tan altas como 0,92 a nivel de sistema [1]. Aunque BLEU puede proporcionar una línea de base rápida, a menudo pierde los matices más profundos que definen traducciones literarias de alta calidad.
Combinación de Evaluación Automática y Humana
Dadas las diversas demandas de la traducción de libros, un enfoque de evaluación híbrida funciona mejor. Las métricas basadas en redes neuronales como COMET y BERTScore ofrecen una manera rápida de evaluar la calidad de la traducción y se alinean bien con el criterio humano