
لماذا يعتبر METEOR مهماً لترجمة الكتب بالذكاء الاصطناعي
METEOR، اختصار لـ Metric for Evaluation of Translation with Explicit ORdering، هو أداة تقييم الترجمة التي تعطي الأولوية للمعنى وتدفق الجملة على مطابقة الكلمات الدقيقة. بخلاف BLEU، التي تعتمد على محاذاة صارمة من كلمة إلى كلمة، يستخدم METEOR تقنيات مثل التجذير وتطابق المرادفات والإعادة الصياغة لتقييم جودة الترجمة بشكل أفضل. هذا يجعله فعالاً بشكل خاص لترجمة الكتب، حيث يكون التقاط صوت المؤلف والنبرة وتدفق السرد أمراً حاسماً.
الرؤى الرئيسية:
- لماذا تقصر BLEU: يؤدي التركيز الصارم لـ BLEU على مطابقة الكلمات الدقيقة إلى معاقبة البدائل الصحيحة، وتواجه صعوبات مع المرادفات، وتفشل في تقييم التماسك السردي، مما يجعلها غير مناسبة للأدب.
- كيف يعمل METEOR: يحاذي METEOR الترجمات باستخدام المطابقات الدقيقة وجذور الكلمات والمرادفات والإعادة الصياغة. يعطي الأولوية للاستدعاء (تغطية المعنى) على الدقة وينطبق عقوبات لترتيب الكلمات السيئ.
- الأداء: يحقق METEOR ارتباطاً بنسبة 0.964 مع حكم الإنسان على مستوى المجموعة، متفوقاً على 0.817 لـ BLEU.
- التأثير على ترجمات الكتب: من خلال التركيز على المعنى والتدفق، يضمن METEOR احتفاظ الترجمات بعمق وقابلية قراءة النص الأصلي، مما يجعله مثالياً لترجمات الأدب المدفوعة بالذكاء الاصطناعي.
بالنسبة لمنصات مثل BookTranslator.ai، يمكّن METEOR ترجمات عالية الجودة في أكثر من 99 لغة بسعر منخفض يصل إلى 5.99 دولار لكل 100,000 كلمة، مما يجعل الأدب في متناول الجمهور العالمي.
مشاكل تقييم ترجمات الكتب بالذكاء الاصطناعي
لماذا تفشل BLEU في الترجمات الطويلة
BLEU (Bilingual Evaluation Understudy)، وهي مقياس تم تقديمه في عام 2002، تعتمد على مطابقة n-gram صارمة، والتي غالباً ما تفشل في التقاط الدقائق في الترجمة الأدبية.
يكمن جوهر المشكلة في نهج BLEU: فهي تقيّم الجودة بمطابقة تسلسلات من 1 إلى 4 كلمات بالضبط كما تظهر في مرجع بشري. تواجه هذه الطريقة الصارمة صعوبات مع المرونة الإبداعية المطلوبة لترجمة الأدب. كما يشرح فريق NLLB:
"BLEU تعاقب الترجمات البديلة الصحيحة. إذا قال المرجع 'السيارة حمراء' وأنتج النظام 'السيارة حمراء'، فإن BLEU تعاقب عدم التطابق حتى لو كان المعنى متطابقاً" [4].
هذا العجز عن التعرف على المرادفات يثير مشاكل خاصة في الكتب، حيث يحمل اختيار الكلمات وزناً كبيراً. على سبيل المثال، تعامل BLEU كلمتي "كبير" و"ضخم" كلمات مختلفة تماماً، على الرغم من أنهما تعنيان نفس الشيء. وبالمثل، فإنها لا تأخذ في الاعتبار الاختلافات مثل "يجري" و"يركض" و"ركض"، وغالباً ما تعاقب الترجمات التي تكون دقيقة وإبداعية في نفس الوقت.
قيد أساسي آخر هو تصميم BLEU على مستوى المجموعة. تم تطويره في الأصل للتعامل مع مجموعات البيانات الكبيرة، وليس الدقة على مستوى الجملة الحاسمة للأدب. كما أن BLEU تفتقر إلى القدرة على تقييم تدفق الجملة أو التماسك السردي. كما لاحظ فريق NLLB:
"BLEU لا تأخذ في الاعتبار الطلاقة أو الحفاظ على المعنى بشكل مباشر - إنها مجرد مقياس تداخل n-gram" [4].
هذا يعني أن الترجمة قد تتضمن من الناحية الفنية جميع الكلمات الصحيحة ولكن ترتبها بطريقة مربكة وحرجة - ولا تزال تحقق درجة عالية. تسلط هذه القصور الضوء على الحاجة إلى طرق التقييم التي تعطي الأولوية للسياق والتماسك والتجربة السردية الشاملة.
لماذا يكون السياق والمعنى مهماً في الكتب
الكتب أكثر من مجرد مجموعات من الجمل - إنها سرديات معقدة حيث تلعب كل كلمة وبنية جملة واختيار أسلوبي دوراً في تشكيل تجربة القارئ. يفتقد التركيز الضيق لـ BLEU على مطابقة الكلمات الدقيقة هذه الصورة الأكبر، خاصة عندما يتعلق الأمر بالحفاظ على تدفق السرد والتماسك.
فجوة الفهم الدلالي واضحة بشكل خاص. يشير مايكل برندوفر:
"قد تحصل ترجمتان متكافئتان دلالياً على درجات BLEU مختلفة جداً اعتماداً على اختياراتهما المحددة للكلمات" [5].
هذا يخلق حافزاً إشكالياً لأنظمة الذكاء الاصطناعي لمطاردة مطابقات الكلمات الدقيقة بدلاً من السعي للدقة الدلالية أو الطلاقة الطبيعية.
تتطلب الترجمة الأدبية توازناً بين الدقة والاستدعاء - ليس فقط تجنب الأخطاء بل أيضاً الحفاظ على العمق والنبرة والصدى العاطفي للنص الأصلي. تركز BLEU بشدة على الدقة، لكن الكتب تتطلب مقاييس تقيس ما إذا كانت الترجمة تلتقط نية المؤلف وتدفق السرد. تقدم الأدوات مثل METEOR، التي تعطي الأولوية للمعنى والتدفق بوزن الاستدعاء تسع مرات أعلى من الدقة، نهجاً أكثر ملاءمة لتقييم الترجمات الأدبية [1].
sbb-itb-0c0385d
METEOR : مقياس للترجمة الآلية
ما هو METEOR وكيف يعمل؟
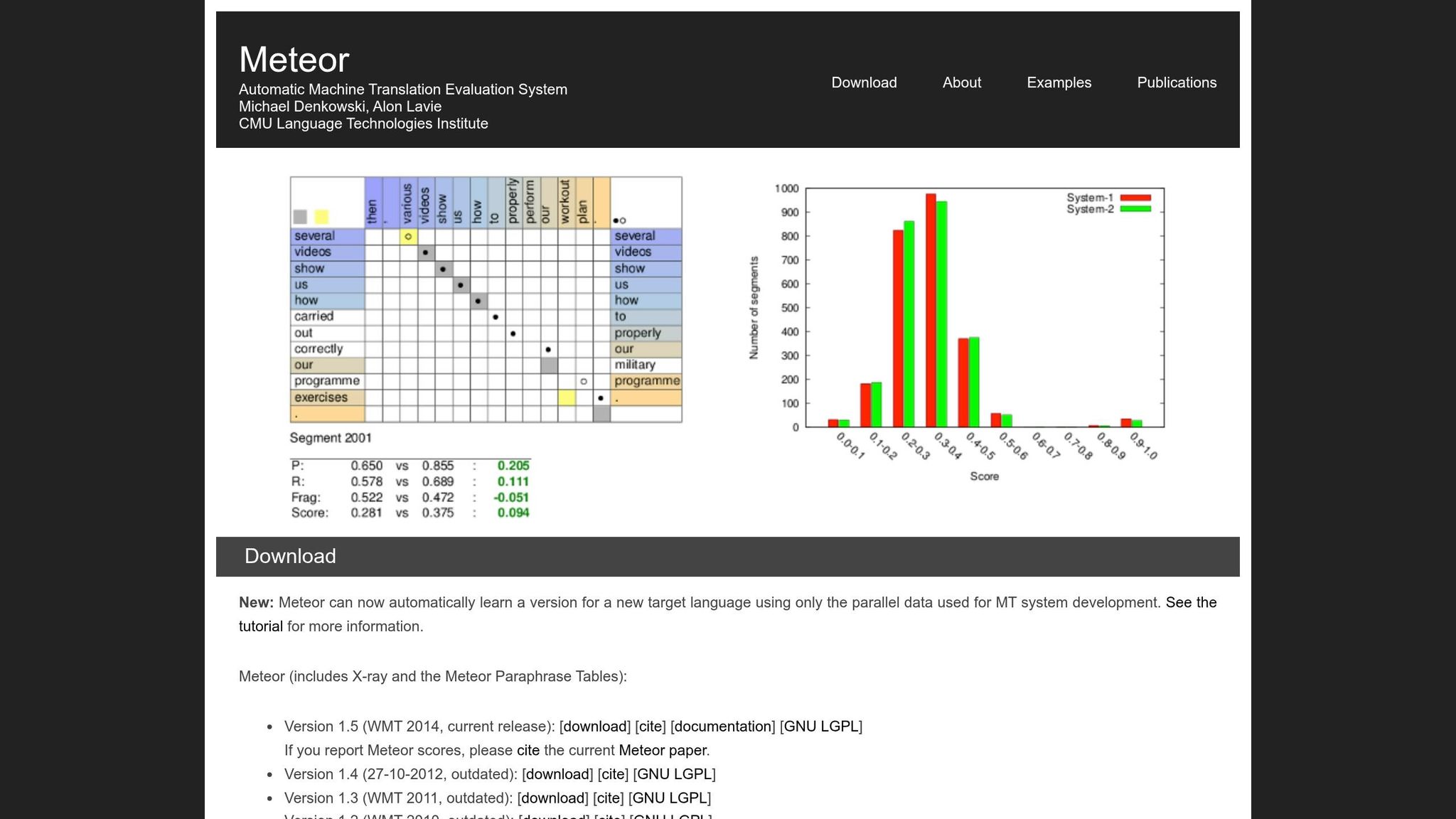
تم تقديم METEOR، اختصار لـ Metric for Evaluation of Translation with Explicit ORdering، في عام 2005 من قبل الباحثين Satanjeev Banerjee و Alon Lavie في جامعة كارنيجي ميلون. تم تطويره لمعالجة بعض قيود BLEU، خاصة مطابقتها الصارمة من كلمة إلى كلمة. يركز METEOR على الحفاظ على المعنى وترتيب الكلمات الطبيعي، مما يجعله مفيداً بشكل خاص لتقييم الترجمات التي تحتاج إلى الحفاظ على تدفق السرد - مثل ترجمات الكتب.
يعمل المقياس بمحاذاة الكلمات الفردية في الترجمة المرشحة مع تلك الموجودة في الترجمة المرجعية. عندما تكون هناك عدة طرق لمحاذاة الكلمات، يختار METEOR الطريقة التي تحتوي على أقل عدد من "التقاطعات" (التقاطعات بين خطوط الربط). يساعد هذا النهج في الحفاظ على ترتيب كلمات أكثر طبيعية في عملية التقييم [1].
الميزات الأساسية لـ METEOR
يتميز METEOR بـ نهج المطابقة المرحلية، الذي يتجاوز مطابقة الكلمات الدقيقة. يستخدم أربع وحدات متسلسلة لتقييم الترجمات:
- المطابقة الدقيقة: تطابق أشكال الكلمات المتطابقة.
- التجذير: تطابق الكلمات التي تشترك في نفس الجذر، مثل "يجري" و"يركض".
- المرادفات: تعترف بالكلمات ذات المعاني المتشابهة باستخدام WordNet.
- مطابقة الإعادة الصياغة: تطابق العبارات ذات المحتوى الدلالي المماثل.
يعالج هذا النهج الطبقي مشكلة BLEU في عدم القدرة على حساب تنويعات الكلمات الصحيحة والتعبيرات البديلة [1][2][6].
يجمع نظام تسجيل METEOR بين عنصرين رئيسيين. أولاً، يحسب متوسط F المرجح للدقة والاستدعاء، مع وزن الاستدعاء تسع مرات أكثر من الدقة. يعكس هذا كيفية تقييم البشر لجودة الترجمة، مع إعطاء الأولوية لتغطية المعنى الأصلي على المطابقات الدقيقة [1]. ثانياً، ينطبق عقوبة التجزئة لثني الترجمات حيث تكون الكلمات المطابقة مشتتة أو بترتيب غير صحيح. إذا تم تقسيم الكلمات المطابقة إلى عدد كبير جداً من "الأجزاء"، يمكن معاقبة الدرجة بنسبة تصل إلى 50%. يضمن هذا أن الترجمات التي تحتوي على كلمات صحيحة لكن بهيكل سيء - غالباً ما يشار إليها باسم "حساء الكلمات" - تحصل على درجات أقل [1].
كيف يتوافق METEOR مع حكم الإنسان
تُظهر الدراسات أن METEOR يرتبط بحكم الإنسان بشكل أفضل من BLEU، محققاً معاملات ارتباط بين 0.60 و 0.75، مقابل نطاق BLEU من 0.45 إلى 0.60 [6].
يرجع هذا الارتباط الأقوى إلى حد كبير إلى تركيز METEOR على مستوى الجملة. بينما تم تصميم BLEU لتقييم الترجمات على مستوى المجموعة، يقيّم METEOR الجمل أو الأجزاء الفردية. هذا يجعله فعالاً بشكل خاص في تقييم التدفق والتماسك المطلوبين في ترجمات الكتب [1]. بالإضافة إلى ذلك، يمكن لـ METEOR معالجة ما يصل إلى 500 جزء في الثانية لكل نواة CPU، مما يجعله فعالاً وموثوقاً للاستخدام العملي [2]. لقد عزز قدرته على مطابقة حكم الإنسان بشكل وثيق دوره في تحسين ترجمات الكتب المدفوعة بالذكاء الاصطناعي.
METEOR مقابل BLEU: لماذا يعمل METEOR بشكل أفضل لترجمة الكتب بالذكاء الاصطناعي

مقارنة مقاييس ترجمة METEOR و BLEU
المميزات الرئيسية لـ METEOR لترجمة الكتب
عندما يتعلق الأمر بترجمة الأعمال الأدبية، يبرز METEOR كمقياس تقييم أكثر فعالية من BLEU. تجعل طرق محاذاته الفريدة وتركيزه على المعنى مناسباً بشكل خاص لدقائق ترجمة الكتب.
أحد الاختلافات الرئيسية هو كيفية تعامل كل مقياس مع الدقة الدلالية. تعتمد BLEU على مطابقة الكلمات الدقيقة، والتي يمكن أن تعاقب بشكل غير عادل الترجمات التي تستخدم المرادفات أو أشكال الكلمات البديلة - حتى عندما يبقى المعنى سليماً. من ناحية أخرى، يدمج METEOR التجذير وتطابق المرادفات. على سبيل المثال، يعترف بأن كلمات مثل "جيد" و"حسن" أو "يركض" و"يجري" تشارك نفس القيمة الدلالية. هذه المرونة ضرورية لترجمات الأدب، حيث يكون التنويع في المفردات والصياغة الإبداعية ضرورياً غالباً للحفاظ على أسلوب المؤلف ونيته.
تمييز مهم آخر هو تركيز METEOR على الاستدعاء على الدقة. تعطي BLEU الأولوية للدقة بقياس عدد الكلمات في الترجمة التي ينتجها الذكاء الاصطناعي والتي تطابق تلك الموجودة في النص المرجعي. ومع ذلك، يوازن METEOR بين الدقة والاستدعاء، مع وزن الاستدعاء تسع مرات أكثر ثقلاً [1]. هذا يضمن أن الترجمة تلتقط المعنى الكامل للنص الأصلي - عامل حاسم لنقل السرديات المعقدة بدقة.
يتفوق METEOR أيضاً في التقييم على مستوى الجملة. بينما تم تصميم BLEU لتقييم الترجمات على مستوى المجموعة، تم تصميم METEOR للمحاذاة الوثيقة مع حكم الإنسان على الجمل أو الأجزاء الفردية. يحقق الحد الأقصى للارتباط بحوالي 0.403 على مستوى الجملة [1]. هذا يجعله فعالاً بشكل خاص في تقييم تدفق وتماسك المقاطع المحددة، وهو أمر أساسي في ترجمة الكتب.
أحد الميزات البارزة في METEOR هو عقوبة التجزئة، التي تعالج ترتيب الكلمات وبنية الجملة. إذا كانت الكلمات المطابقة في الترجمة مشتتة في عدد كبير جداً من الأجزاء، يمكن أن تنخفض الدرجة بنسبة تصل إلى 50% [1]. تضمن هذه الآلية أن الترجمات تحافظ على هيكل طبيعي ومتماسك - شيء غالباً ما تتغاضى عنه BLEU. من خلال التركيز على هذه التفاصيل، يساعد METEOR على الحفاظ على المعنى الدقيق وقابلية قراءة النص الأصلي.
جدول المقارنة: METEOR مقابل BLEU
| الميزة | BLEU | METEOR |
|---|---|---|
| التركيز الأساسي | الدقة (تداخل الكلمات الدقيقة) | الاستدعاء (تغطية المعنى والمحتوى) |
| معايير المطابقة | مطابقة n-gram الدقيقة | الدقيقة والتجذير والمرادفات والإعادة الصياغة |
| الدقة الدلالية | منخفضة (مطابقات الكلمات الدقيقة فقط) | عالية (تشمل المرادفات والتجذير) |
| الارتباط البشري | أقوى على مستوى المجموعة | قوي على مستويات الجملة والمجموعة |
| بنية الجملة | غير مباشر (عبر تداخلات n-gram) | مباشر (عبر عقوبة التجزئة والمحاذاة) |
| المرونة | صارمة؛ تعاقب الصياغة الإبداعية | مرنة؛ تكافئ التكافؤ الدلالي |
| معالجة الاستدعاء | غير مباشر (عقوبة الإيجاز) | مباشر (حساب الاستدعاء مرجح 9 مرات) |
كيف يتم استخدام METEOR في منصات ترجمة الكتب بالذكاء الاصطناعي
ضمان الجودة مع METEOR
تستفيد منص