
曾经想过把书架上的实体书变成完美翻译的数字副本吗?这就是OCR和翻译流程的妙处。它从光学字符识别(OCR)开始,从扫描页面中提取文本,然后使用机器翻译将其转换为新语言。本指南远不止简单的应用程序,而是为处理书籍和其他长篇内容而设计的专业工作流程,具有应有的精确性。
您的数字书籍翻译现代工作流程
将印刷书籍转换为精美的翻译数字文件是一个真正的项目。这不是一键式操作,而是一个有条不紊的过程,旨在保持作者的原始声音完整,同时将其开放给全新的受众。您实际上是在建立一座从印刷页面到数字屏幕的桥梁,将静态墨迹转变为动态、可编辑和可搜索的数据。
成功真的取决于一系列谨慎的步骤,每一步都为下一步奠定基础。可以把它看作是您书籍的生产线。
书籍翻译的核心阶段
从一堆纸张到完成的EPUB或PDF的旅程涉及几个不同的阶段。这个图表为您提供了整个过程的鸟瞰图,从获取扫描的源材料到格式化最终文件。
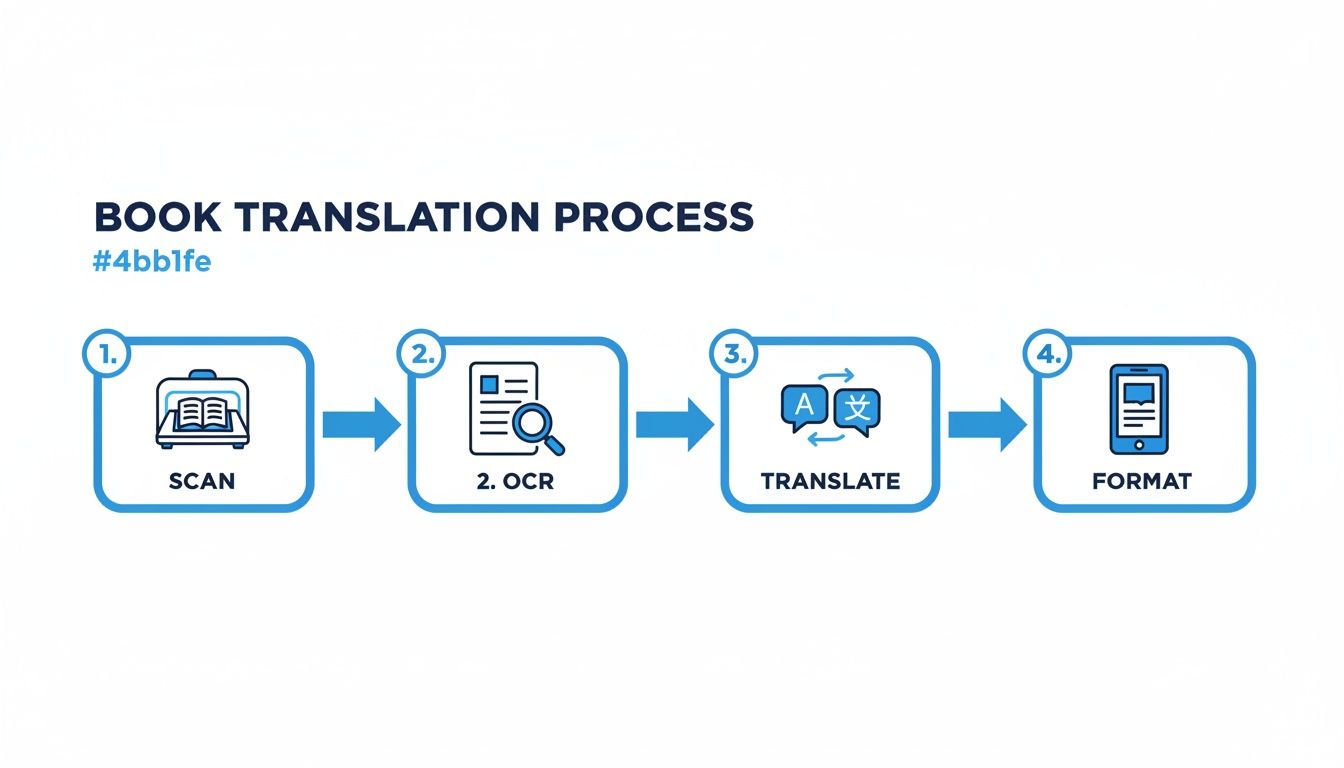
这些阶段中的每一个——扫描、OCR、翻译和格式化——都是关键环节。您从一个阶段获得的质量直接决定了您可以投入下一个阶段的质量。
这已不再是一个小众技能;需求正在爆炸性增长。全球光学字符识别市场在2024年达到139.5亿美元,预计到2033年将飙升至460亿美元以上,这都得益于全球数字化的大规模推动。
关键要点:对于任何大型项目,结构化的工作流程是必不可少的。如果您仓促进行扫描或在清理提取的文本上节省成本,您只是在为自己制造大麻烦,特别是在翻译和格式化期间。
作为任何现代专业工作流程的一部分,确保GDPR合规的AI集成也至关重要,特别是当您处理整本书籍的内容时。本指南将为您提供完整的项目计划,以自信地从头到尾管理大规模OCR和翻译项目。
准备您的书籍以获得完美的扫描效果
您整个OCR和翻译项目取决于一件事:初始扫描的质量。在您甚至考虑运行文本识别软件之前,您需要把这第一步做好。模糊、歪斜或光线不足的扫描将导致一系列错误,给您留下乱码文本和翻译噩梦。
可以把它比作烹饪。世界上最好的厨师也无法用变质的食材做出美餐。您的扫描就是您的食材。

这是您的扫描仪成为最重要工具的地方。忘记对整本书使用手机应用程序;您永远无法获得所需的一致性。对于这种规模的项目,只有平板扫描仪才能为您提供所需的控制和质量。
调整您的扫描仪设置
获取正确的扫描仪设置不仅仅是一个建议——对于获得干净、准确的文本来说绝对至关重要。这里的一些调整可以为您节省无数小时的痛苦手动更正。
我扫描过数百本书,从现代平装本到几个世纪前的古籍,正确的设置会产生巨大差异。为了帮助您开始,这是一个关于使用什么和原因的快速指南。
书籍OCR的最优扫描仪设置
| 设置 | 现代书籍推荐 | 旧书/复杂书籍推荐 | 原因 |
|---|---|---|---|
| 分辨率(DPI) | 300-400 DPI | 400-600 DPI | 300是清晰度的最低要求。对于小字体、褪色的墨迹或复杂的布局,请提高分辨率以捕获更多细节,而不会增加文件大小。 |
| 颜色模式 | 灰度 | 灰度 | 灰度比苛刻的黑白模式更好地捕获文本细微差别,避免全彩扫描的巨大文件大小和颜色噪声。 |
| 文件格式 | TIFF | TIFF | TIFF是无损格式。它完美地保留每个像素,防止JPEG创建的压缩伪影,这可能会破坏OCR精度。 |
这些设置是捕获清晰文本的最佳选择。记住,目标是从一开始就为OCR软件提供最干净的数据。
我的个人规则:永远不要为存档扫描使用JPEG。它的"有损"压缩实际上会丢弃数据以使文件更小,在字母周围创建模糊的伪影。这是一个快捷方式,最终总是会花费您更多的更正时间。
预处理:清理阶段
随着您的页面被数字化,您还没有完全准备好进行OCR引擎。一点点预处理将清理原始扫描并显著提升您的结果。大多数体面的扫描软件都包括这些工具,但免费的图像编辑器也能很好地工作。
这是我总是检查和修复的内容:
- 倾斜校正:这是最重要的一步。它自动拉直以略微角度扫描的任何页面。即使很小的1度倾斜也会使软件困惑,所以在每一页上都运行这个。
- 裁剪:去掉黑色边框和扫描仪盖进入图像的任何部分。您希望软件只关注页面内容,而不是周围的垃圾。
- 对比度/亮度:调整这些级别以使文本尽可能暗,背景尽可能亮。小心不要冲淡字母。对于有泛黄页面或褪色墨迹的旧书,这是一个救星。
这种仔细的准备工作是将令人沮丧的项目与成功项目区分开来的因素。
一旦您获得了完美的提取文本,您就可以考虑最终格式。如果您在辩论如何打包您翻译的书籍,我们有一个有用的指南,分解EPUB与PDF用于AI翻译的利弊。
为干净的文本提取选择正确的OCR工具
随着您的完美扫描准备就绪,是时候转向数字转换的核心:选择正确的光学字符识别(OCR)引擎。您现在选择的工具直接影响您的原始文本的质量,这反过来又为整个翻译过程奠定了基础。当您处理整本书时,不仅仅任何OCR软件都能胜任。
您通常在两条路径中寻找:强大的桌面应用程序或高度可扩展的基于云的服务。每个都有其位置,最佳选择真的取决于您项目的具体情况。

ABBYY FineReader的这个界面展示了认真OCR工作的必备功能——能够并排看到原始扫描和识别的文本。这使发现和修复错误变得轻而易举。
桌面软件与云服务
对于那些想要完全、精细控制流程的人,像ABBYY FineReader这样的桌面应用程序是长期以来的行业最爱。它在处理复杂的页面布局方面表现出色,识别大量语言,并为您提供手动在要捕获的确切文本周围绘制框的工具。这对于告诉软件忽略讨厌的页眉、页脚和页码是一个救星。
另一方面,您有像Google Cloud Vision OCR和Amazon Textract这样的云动力。这些服务是为规模而构建的。与其将您自己的计算机占用数小时,不如一次性向它们提供数百甚至数千页,只为您处理的内容付费。他们的AI模型不断被改进,所以您开箱即用获得的准确性往往令人印象深刻。
我的两分钱:如果我正在处理一本设计非常奇特的书,我会坚持使用桌面工具以获得微调的控制。但是如果目标是数字化整个书架的标准布局书籍,云服务的纯粹速度和批处理能力是唯一的出路。
调整您的OCR设置以获得最大精度
无论您选择哪个工具,都不要只是按"开始"按钮。提前花几分钟配置设置将使您免于之后大量的手动清理。
以下是必不可少的:
- 设置识别语言:这似乎很明显,但这是最关键的一步。明确告诉软件源语言(例如德语、日语、西班牙语)会加载正确的字符集和字典,大幅降低错误率。
- 定义识别区域:在几个示例页面上花一分钟在主体文本周围绘制框。这是您如何训练OCR忽略页码、运行标题和装饰边框的方式,这些只会污染您的最终文本文件。
- 启用字典:如果软件具有此功能,请将其打开。它允许工具根据已知词汇检查识别的单词,这有助于它自我纠正常见错误,如将"rn"与"m"混淆。
这个初始设置是您对抗混乱、充满错误的文本文件的第一道防线。
许多最好的OCR和翻译解决方案现在由复杂的AI驱动;值得研究不同的内容创作者的AI工具以查看还有什么可以补充您的工作流程。这种对更聪明技术的推动是翻译服务市场增长的一个巨大因素,该市场在2024年的价值为267亿美元,预计到2029年将达到342.4亿美元。快速增长只是表明全球对高质量、高效本地化的需求有多大。
翻译内容而不失作者的声音
从OCR流程中获得干净的文本是一个巨大的进步,但现在来了真正的挑战:翻译。如果您只是将文本转储到标准翻译工具中,您会得到单词回来,但作者的灵魂将消失。结果通常在技术上是正确的,但在情感上是平坦的,被剥夺了使书籍引人入胜的个性。
目标不仅仅是交换一种语言中的单词与另一种语言中的单词。这是关于忠实地传递含义、风格和语调。完成这项工作的最佳方法是采用混合方法——将AI的原始力量与人类专家不可替代的细微差别相结合。
将AI速度与人类洞察相结合
像DeepL这样的现代翻译平台已经完全改变了游戏规则。他们在理解上下文和句子结构方面非常出色,产生的翻译感觉比旧系统的笨拙、字面输出自然得多。这为您提供了一个很好的初稿,通常在几分钟内完成人类翻译人员需要数周才能完成的工作。
但是尽管其复杂性,AI仍然在细微之处出错。它不太理解习语表达、文化内部笑话或定义作者声音的独特风格怪癖。例如,西班牙语中的一个俏皮短语如果按字面翻译,很容易在英语中变得生硬和过于正式。
这正是为什么最终的人类审查对于高质量的结果绝对必要。理想的工作流程是一个伙伴关系:
- 获得AI初稿:首先通过顶级机器翻译引擎运行您干净的、OCR提取的文本。
- 引入人类专家:一个流利的使用者然后仔细阅读翻译的文本,与原文进行比较以捕捉机器遗漏的内容。
- 细化和抛光:审查者平滑了尴尬的措辞,纠正了文化误翻,并微调语调,直到它完美匹配作者的意图。
这个一二组合为您提供了AI的难以置信的效率,而不牺牲原始作品的心脏。我们实际上在我们关于AI与人类翻译人员和保留文学风格的文章中更深入地探讨了这个话题。
使用术语表和风格指南以获得一致性
当您处理像书籍一样大的项目时,一致性就是一切。没有什么比看到主要角色的名字或虚构城市从一章到下一章的拼写不同更能让读者脱离故事的了。它只是感觉草率。
幸运的是,现代CAT(计算机辅助翻译)工具为您提供了一种方法来强制一致性。他们让您建立特定于项目的资源,指导整个翻译,无论是AI还是人类在做这项工作。
- 翻译术语表:可以把这看作是您书籍的自定义字典。您可以准确定义关键术语、角色名称和特定短语必须每次出现时的翻译方式。
- 风格指南:这是您对语调和正式程度制定法律的地方。散文应该是对话式还是学术式的?您是否想避免特定的短语?风格指南确保这本书读起来像一个有凝聚力的整体,而不是断开连接的章节的集合。
通过建立一个简单的术语表,您可以强制一致性并大幅减少手动更正的时间。它确保"El Bosque de las Sombras"始终被翻译为"The Forest of Shadows",而不是"The Woods of Shade"。
推动所有这一切的引擎,机器翻译(MT),是一个增长极其迅速的领域。2025年估值为11.2亿美元,该市场预计到2030年将近翻倍至20亿美元。这种繁荣是由神经机器翻译(NMT)推动的,由于其卓越的准确性,它拥有主导的48.67%市场份额。正如您从Global Growth Insights的MT技术上升中看到的,这项技术正在使复杂的ocr和翻译工作流程比以往任何时候都更强大。采用这种聪明的、混合的方法是创建真正尊重原始作品的最终产品的最佳选择。
把它全部组合回来:制作您的最终数字书籍
您成功了。扫描、OCR清理和仔细翻译都完成了。现在您有了一个干净的、翻译的手稿,是时候进行流程中最有回报的部分了:将其重建为一本精美的、专业的数字书籍。
这是所有那些细致准备工作得到回报的地方。您本质上是一个数字排版员,将原始文本转变为优雅的EPUB或清晰的PDF,读者会喜欢。这个最终的组装是将简单的文本文件提升为真正高质量阅读体验的因素。
从纯文本到结构化电子书
首先,您需要将翻译的文本导入电子书创建工具。对于创建可回流的EPUB——大多数电子阅读器(如Kindle和Kobo)的标准——您无法使用强大的免费选项,如Calibre或Sigil。如果您的项目需要模仿印刷书籍的固定布局,那么Adobe InDesign是这项工作的行业标准工具。
随着您的文本导入,真正的工艺开始了。这不仅仅是复制粘贴工作;您正在有条不紊地重建书籍的架构,以确保其可读和可导航。
- 章节分隔:您需要插入干净的分隔符来引导读者通过叙述。
- 标题和副标题:应用适当的H1、H2和H3标签会创建逻辑层次结构和功能性目录。
- 文本样式:是时候通过恢复斜体、粗体和任何独特的块引用来恢复原始作者的意图了。
- 图像放置:小心地将原始插图、图表或图表重新集成到文本流中。

像Calibre这样的工具为您提供了令人难以置信的控制,让您微调从封面图像和元数据到决定书籍外观的底层CSS的所有内容。如需更深入的了解,请查看我们关于翻译友好格式化的顶级工具的指南。
最终QA:验证和抛光
在您打香槟之前,还有最后一个关键步骤:彻底的质量保证(QA)检查。电子书在您的桌面上可能看起来完美无缺,但在实际的电子阅读器上可能会崩溃。这个最后的通过确保每个读者获得一致的、专业的体验,无论他们的设备如何。
来自经验的一个建议:甚至不要想跳过这个。一个破损的图像或遗漏的章节分隔符可以完全将读者拉出故事并破坏您所有的辛苦工作。
这是您的最终QA检查清单应该是什么样的:
- 完整的格式化通读:用细齿梳仔细阅读整个电子书,仅寻找格式化问题。标题都一致吗?段落缩进看起来对吗?图像对齐正确,没有跨页中断吗?
- 在多个设备上测试:这是必不可少的。将文件加载到尽可能多的设备和应用程序上。Kindle、Kobo、Apple Books、Google Play Books——看看它在所有这些上的样子。可回流的EPUB从一个平台到另一个平台的呈现方式可能令人惊讶地不同。
- 运行EPUB验证:使用官方工具,如EPUBCheck验证器,以确保您的文件在技术上是合理的并符合行业标准。这是您对抗兼容性错误的最佳防御,这些错误可能导致您的书籍被在线商店拒绝。
通过细致地重建和抛光您的数字书籍,您创建了一个真正尊重原始作品的最终产品。您已经通过ocr和翻译流程成功地为全新的受众解锁了它,现在它已准备好供他们享受。
关于书籍OCR和翻译的常见问题
即使有了坚实的工作流程,承担一个完整的书籍翻译项目也可能会遇到一些意外。让我们解决一些最常见的问题,从导航法律边界到为您的工具设置现实的期望。现在弄清楚这些东西可以为您节省之后大量的麻烦。
可以把它看作是平衡技术可能性与项目的实际现实。一点远见会大有帮助。
扫描和翻译受版权保护的书籍合法吗?
这是大问题,说实话,它处于法律灰色地带。在许多地方,包括美国,扫描您购买的书籍供个人使用可能属于"合理使用"原则。这里的关键词是个人使用。
一旦您分享、分发或尝试出售该翻译副本,您就已经踏入了明确的版权侵权界线。除非您直接获得版权持有人的许可,否则这是违法的。
我的两分钱:将整个流程视为访问您已经拥有的内容的方式。这是为了阅读您合法购买的书籍,但用您自己的语言。永远不要分享或出售您创建的文件。始终了解您所在地的版权法。
我应该如何处理复杂的布局,如教科书或杂志?
并非所有书籍都是简单、直接的文本块。带有标注框的教科书、多列的杂志或插图小说对于基本OCR工具来说可能是一场噩梦。这是专业级桌面软件真正赚取其价值的地方。
像