
翻译准确性指标:详解
翻译准确性指标帮助评估机器翻译与人工创建的参考翻译的匹配程度。这些工具对于评估翻译质量至关重要,特别是在处理大规模项目或高风险内容时。指标分为三类:
- 基于字符串的指标:BLEU、METEOR 和 TER 专注于词语或字符重叠。
- 基于神经网络的指标:COMET 和 BERTScore 使用 AI 模型分析语义相似性。
- 人工评估:直接评估,如 MQM,专注于充分性和流畅性。
主要要点:
- BLEU:快速简单,但在同义词和深层含义方面表现不佳。
- METEOR:考虑同义词和语言细微差别;更适合文学作品。
- TER:衡量编辑工作量,但忽视语义质量。
- COMET 和 BERTScore:高级 AI 模型,与人工判断高度一致,适合细微文本。
对于书籍翻译,将自动化工具与人工评估相结合可确保准确性并保留原始风格。BookTranslator.ai 等平台采用这种混合方法,以超过 99 种语言提供可靠的结果。
常见的翻译准确性指标
BLEU 分数
BLEU(双语评估替补)于 2002 年推出,至今仍是评估机器翻译的常用指标 [4]。它通过比较 n 元组精确度 来工作,即分析机器输出中的词序列与参考翻译的对齐方式。BLEU 分数范围从 0 到 1,数字越高表示质量越好。它最大的优势是什么?速度和简单性——BLEU 可以快速处理数千个翻译,使其极具实用性。这种效率甚至为它赢得了 NAACL 2018 时间考验奖。
如 Papineni 等人所解释的,"主要思想是使用源系统翻译和一组人工参考翻译之间的可变长度 n 元组匹配的加权平均值" [4]。
但是,BLEU 有一个明显的局限性:它优先考虑精确的词匹配。这意味着它可能低估了表达相同含义但使用不同措辞的翻译。为了解决这个问题,METEOR 等指标旨在捕捉语言细微差别。
METEOR 指标
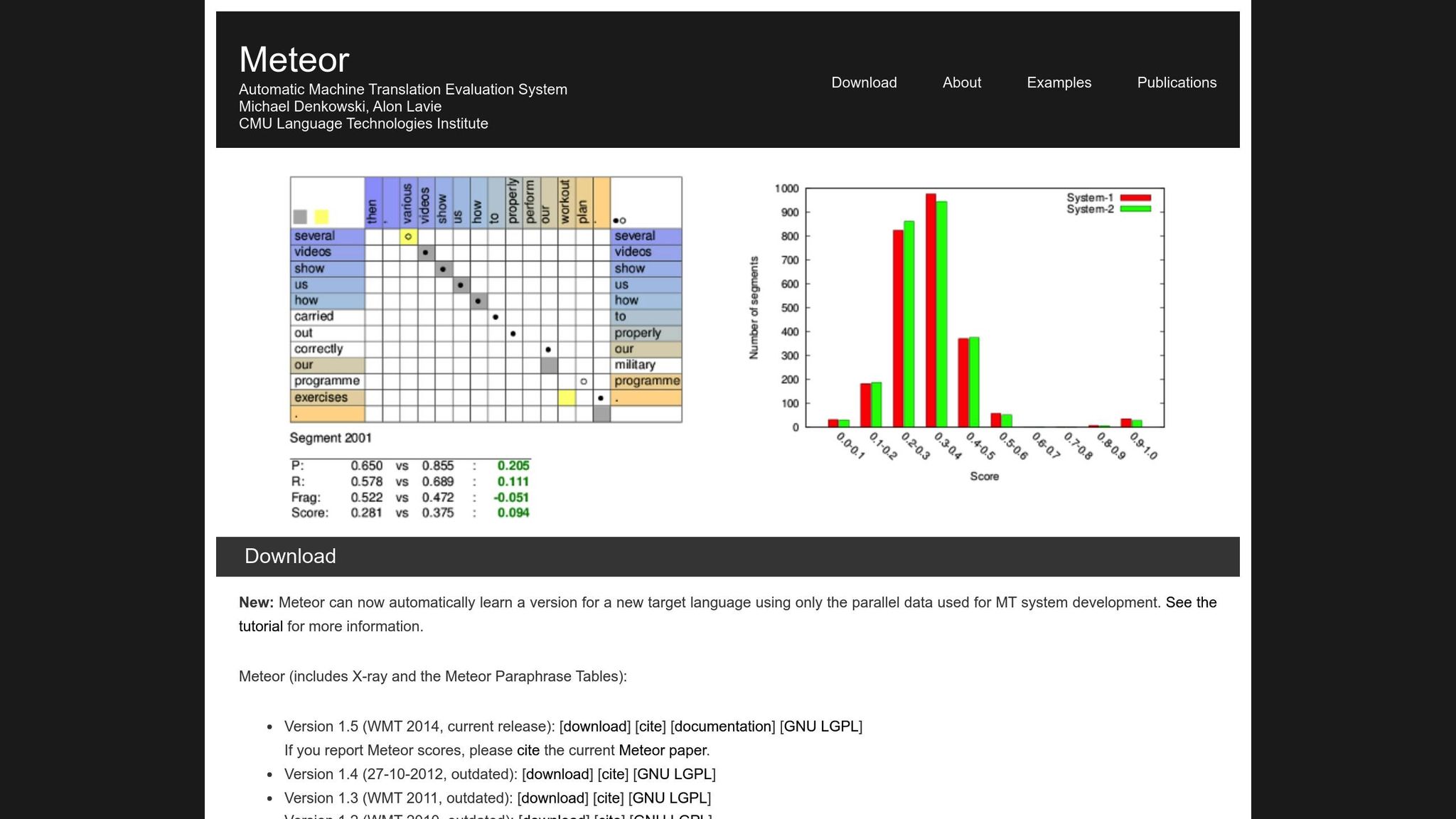
METEOR(具有显式排序的翻译评估指标)通过考虑精确度、召回率、同义词、词干提取和词序惩罚来改进 BLEU [1]。它处理"running"与"ran"或"happy"与"joyful"等变体,使其更适合意义最重要的翻译。例如,在 NIST MetricsMaTr10 挑战赛期间,METEOR-next-rank 在系统级别上与人工判断的 Spearman 相关性达到 0.92,在文档级别上达到 0.84 [1]。
也就是说,METEOR 也有其自身的挑战。它需要额外的资源,如同义词数据库和词干提取算法,这增加了其计算负载。不过,它通常提供更细致和可靠的评估,特别是在捕捉语义准确性方面。
翻译编辑率(TER)
TER 通过计算将机器输出转换为参考翻译所需的编辑次数(插入、删除、替换和移位)来评估翻译质量。这使其特别适合衡量对齐输出与所需结果所需的编辑工作量。在 MetricsMaTr10 评估中,TER-v0.7.25 在系统级别上与人工语义充分性评估的相关性为 0.89,而 TERp 在段落级别上的相关性为 0.68 [1]。
基于神经网络的指标:BERTScore、COMET 和 GEMBA
基于神经网络的指标通过专注于语义分析而非精确词匹配,将翻译评估提升到新的水平。以下是快速概览:
- BERTScore:使用上下文嵌入来衡量翻译之间的相似性。
- COMET:将源文本、假设和参考翻译集成到一个在人工注释上训练的神经框架中。它在与人工质量判断的相关性方面取得了一些最高的成绩 [5]。
- GEMBA:利用大型语言模型进行零样本质量估计,提供更接近人工评估的近似值。
虽然这些指标功能强大,但它们存在权衡。与可以在标准 CPU 上以毫秒为单位运行的 BLEU 和 TER 不同,BERTScore 和 COMET 等基于神经网络的指标通常需要 GPU 加速来有效处理大型数据集。特别是 GEMBA,可能涉及高 API 成本和大型语言模型的潜在偏差,使某些用户难以使用。
用于评估机器翻译系统的自动指标
翻译指标比较

翻译准确性指标比较:BLEU、METEOR、TER、BERTScore、COMET 和 GEMBA
指标比较表
选择正确的翻译指标通常取决于评估的重点和可用的资源。传统指标如 BLEU 速度快,资源需求少,但难以捕捉更深层的语义含义。另一方面,神经指标在理解上下文和含义方面表现出色,但需要更多的计算能力。
最近的研究建议放弃基于重叠的指标。例如,WMT22 的研究结果建议放弃 BLEU 等指标,转而采用神经方法 [6]。该研究强调,BLEU、spBLEU 和 chrF 等重叠指标与人工专家评估的相关性很差。
以下是关键翻译指标的快速比较,涵盖它们的焦点领域、评分方法、与人工评估的相关性、局限性和对书籍翻译的适用性:
| 指标 | 焦点领域 | 评分范围 | 与人工评估的相关性 | 局限性 | 对书籍翻译的适用性 |
|---|---|---|---|---|---|
| BLEU | N 元组精确度 | 0 到 1(或 0-100) | 低到中等 | 在同义词方面表现不佳 [7][8] | 低;缺乏捕捉文学风格的能力 |
| METEOR | 精确度、召回率、同义词、词序 | 0 到 1 | 高 | 需要特定语言资源 [7] | 中等;对一致的术语有用 |
| TER | 编辑距离(编辑后工作量) | 0 到 1(越低越好) | 中等 | 忽视语义质量 [7] | 低;专注于机制,而非"声音" |
| BERTScore | 通过上下文嵌入的语义相似性 | 0 到 1 | 高 | 资源密集型 [7] | 高;捕捉更深层的含义和上下文 |
| COMET | 语义相似性和流畅性 | 0 到 1(0.5-0.8 典型) | 非常高 | 需要预训练模型 [7][8] | 高;保留风格和细微含义 |
| GEMBA | 基于 LLM 的整体评估 | 变量 | 高 | 复杂设置;昂贵的 API [7] | 高;提供"类人"的全面评审 |
该表强调了不同指标与特定翻译需求的对齐方式。对于技术翻译,BLEU 和 TER 等指标提供快速的基本基准。然而,对于文学翻译——风格、语调和细微含义至关重要——BERTScore 和 COMET 等神经指标表现要好得多。这些工具特别擅长捕捉文学文本的深度和艺术性,而传统指标往往忽视这些 [7]。
例如,BookTranslator.ai 等平台旨在平衡效率和质量,从神经指标中获益匪浅。BERTScore 和 COMET 等工具确保语义准确性和文学风格都得到保留。
为了更好地理解,"好的" BLEU 分数通常在 30 到 40 之间,分数超过 40 被认为很强,超过 50 表示高质量翻译 [8]。对于 COMET,分数通常范围从 0.5 到 0.8,接近 1.0 的值反映接近人工翻译质量 [8]。神经指标不仅在不同文本类型中表现一致,而且与 BLEU 等域敏感指标相比,能更好地适应不同的上下文 [6]。
sbb-itb-0c0385d
人工评估方法
自动化指标可能提供速度和一致性,但它们往往忽视定义翻译质量的微妙细节。这就是人工评估作为黄金标准的地方 [2]。虽然它更慢且更昂贵,但人工评估揭示了质量问题背后的更深层原因——BLEU 或 COMET 等指标根本无法识别的东西 [9]。
人工评估有两种主要方法。一种是 直接表达判断(DEJ),其中翻译根据流畅性和充分性等量表进行评级。另一种涉及 非 DEJ 方法,专注于发现和分类特定错误,通常使用 MQM 等框架 [12]。虽然分析方法分解个别错误及其严重程度,但整体方法查看总体质量。这些方法共同构成了 MQM 等框架的支柱。
MQM(多维质量指标)

当自动化工具不足时,MQM 提供了更详细和可操作的替代方案。它将翻译错误分解为准确性、流畅性、术语、区域设置约定和设计/标记等类别,而不是用单一数字总结质量 [18, 17]。
"相比之下,自动化指标通常只提供一个数字,没有说明如何改进结果的指示。"
– MQM 委员会 [10]
错误按严重程度评级:中立(已标记但可接受,无惩罚)、轻微(略微明显,惩罚权重为 1)、重大(影响理解,惩罚权重为 5)和 严重(使文本无法使用,惩罚权重为 25) [11]。对于法律文件等关键翻译,通过阈值可能设置为原始分数尺度上的 99.5 [11]。
MQM 特别有用的原因是它能够精确指出具体的问题领域。例如,如果文学翻译评分较低,MQM 可以揭示问题是否在于措辞不当或术语不一致。这种详细程度对于 BookTranslator.ai 等平台特别有价值,其中捕捉含义和文学风格都至关重要。
充分性和流畅性评分
基于 MQM 等结构化框架,评估者还专注于翻译质量的两个关键维度:充分性和流畅性。充分性衡量翻译对源文本含义的传达程度,而流畅性评估对母语使用者来说有多自然和可读。这些方面通常在五点量表上评分 [9]。
平衡这两个维度可能很棘手,特别是在文学翻译中。在保留原作者声音的同时确保文本在目标语言中流畅阅读需要仔细关注。
为了改进此过程,评估者使用 直接评估 (DA),它以单语、双语或基于参考的格式评分翻译 [9]。标量质量指标 (SQM) 进一步采用七点量表,允许评分者在整个文档的背景下评估单个段落。对于书籍,这种情境焦点至关重要——质量通常取决于章节如何发展角色或保持情节连贯性。
在书籍翻译中使用指标
翻译书籍是一项独特的挑战。与说明书或营销材料不同,书籍需要在 语义准确性(确保含义正确)和 风格保留(保持作者的声音和语调)之间取得平衡。评估书籍翻译需要量身定制的方法,指标选择要适合被翻译的具体内容类型。
技术翻译与文学翻译
并非所有书籍翻译都有相同的要求。技术文本,如学术或教学材料,优先考虑精确性和一致性。对于这些,TER(翻译编辑率)等指标特别有效,因为它们衡量完善翻译所需的编辑量。
另一方面,文学作品是另一回事。小说、回忆录和类似的文体大量依赖于叙事流和情感共鸣。在这些情况下,METEOR 脱颖而出,因为它考虑了同义词和微妙的语义差异,在系统级别上与人工评估的相关性高达 0.92 [1]。虽然 BLEU 可以提供快速基线,但它往往忽视定义高质量文学翻译的更深层细微差别。
结合自动和人工评估
鉴于书籍翻译的多样化需求,混合评估方法效果最好。神经指标如 COMET 和 BERTScore 提供了快速衡量翻译质量的方式,并与人工判断高度一致 [6]。但是,这些自动化工具有局限性——它们无法完全捕捉翻译的实际和艺术价值。
为了解决这个问题,BookTranslator.ai 等平台将自动化评估与人工评估相结合。例如,他们通常使用 7 点量表来衡量语义充分性