
多语言EPUB无障碍的最佳实践
创建无障碍的多语言EPUB确保每个人,无论语言或残障如何,都能享受数字书籍。以下是实现方法:
- 语言元数据:使用
<dc:language>在EPUB中声明主要和次要语言。这有助于屏幕阅读器和盲文显示器加载正确的设置。 - 语言标记:在内容中添加
xml:lang标签以指示语言变化,确保准确的发音和文本转语音性能。 - 非拉丁文字:嵌入适当的字体并确保Unicode兼容性,以避免显示问题,如缺失字符。
- 无障碍标准:遵循WCAG 2.x(A级)、EPUB 3.3和BCP 47标准以满足无障碍指南。
- 测试工具:使用 EPUBCheck、Ace by DAISY 和 Thorium Reader 等工具验证EPUB,确认无障碍功能按预期工作。
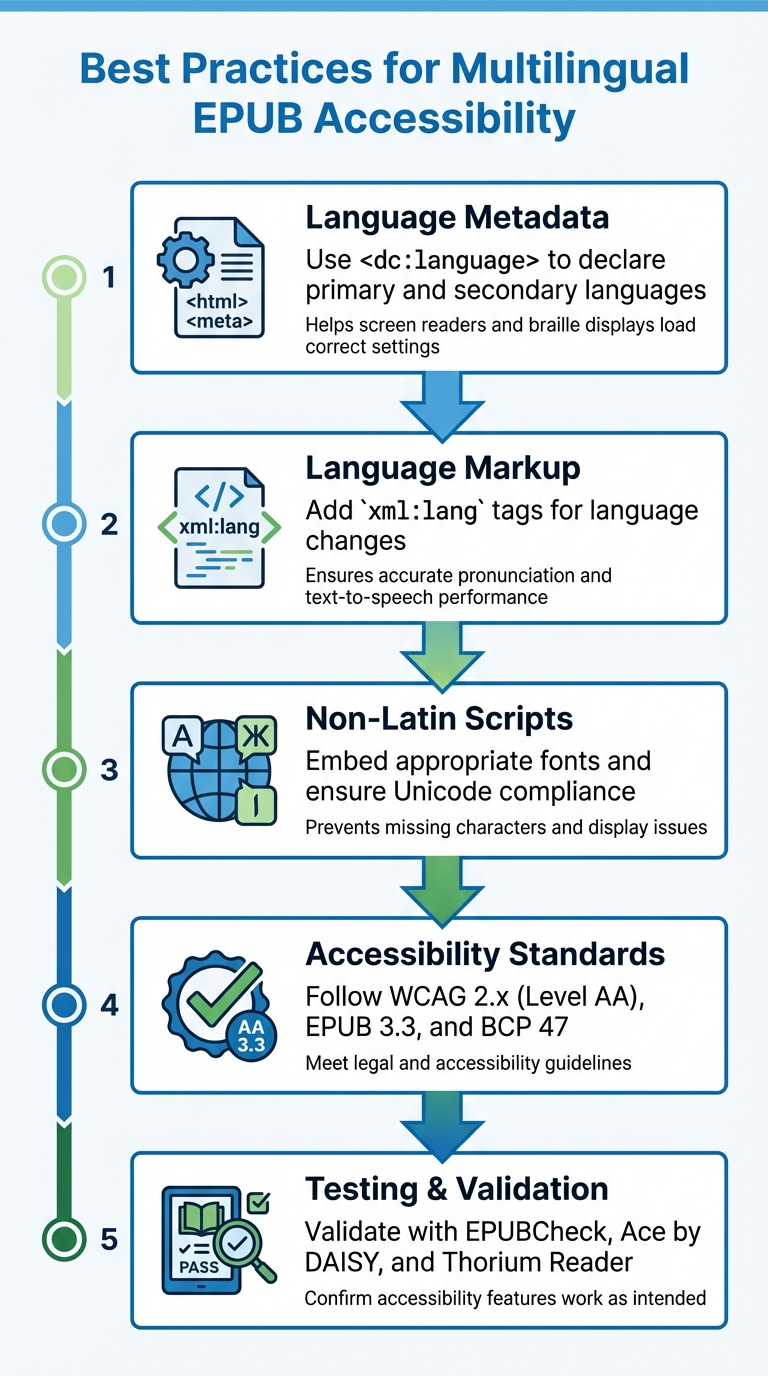
创建无障碍多语言EPUB的5步流程
EPUB无障碍基础101
sbb-itb-0c0385d
元数据和语言声明
设置准确的元数据是实现多语言EPUB无障碍的基础。EPUB包文档(OPF文件)中的 <metadata> 部分将您的书籍包含的语言信息传达给辅助技术。这确保屏幕阅读器和盲文显示器等工具立即加载正确的设置 - 如语音合成器或盲文表。没有这些信息,辅助技术可能会默认使用错误的语言,为依赖这些技术的用户造成不必要的困难。在EPUB中声明主要和次要语言始于此元数据设置。
如何声明主要和次要语言
Dublin Core <dc:language> 元素是识别EPUB中语言的首选方法。对于多语言书籍,您需要添加多个 <dc:language> 标签 - 每种内容语言一个。始终首先列出主要语言,因为Google Play Books等平台使用它来正确分类您的书籍。来自波兰盲人和视力障碍者基金会"Trakt"的Monika Zarczuk-Engelsma强调了这一点:
在EPUB元数据中包含所有书籍语言。
这样做可确保可刷新的盲文显示器自动调整到正确的盲文表,这对盲人读者准确解释不同语言的拼写和标点符号至关重要。对于多语言内容,强烈建议使用EPUB 3而不是EPUB 2,因为旧版本缺少 refines 属性,这可能导致辅助技术处理元数据的方式混乱。
使用正确的语言代码
为确保与阅读系统和辅助工具的兼容性,使用ISO 639-1两字母代码(例如,'en'代表英语,'es'代表西班牙语)。以下是常见语言及其正确元数据格式的快速参考:
| 语言 | ISO 639-1代码 | 元数据示例 |
|---|---|---|
| 英语 | en | <dc:language>en</dc:language> |
| 西班牙语 | es | <dc:language>es</dc:language> |
| 法语 | fr | <dc:language>fr</dc:language> |
| 日语 | ja | <dc:language>ja</dc:language> |
| 波兰语 | pl | <dc:language>pl</dc:language> |
| 德语 | de | <dc:language>de</dc:language> |
一致性至关重要。元数据中的语言代码应与内容中的语言标签相匹配,这些标签使用 xml:lang 属性定义。这种对齐允许屏幕阅读器在用户浏览您的书籍时无缝切换语言,避免发音错误等问题。
内容文档中的语言标记
设置了准确的书籍语言元数据后,下一步是确保精确的文本内语言标记。这涉及使用 xml:lang 属性标记内容中的语言变化。为什么这很重要?它帮助屏幕阅读器和文本转语音工具准确了解何时切换语言。这确保应用了正确的发音和语音规则。没有它,屏幕阅读器可能会通过应用错误语言的规则来发音错误,造成混淆。
使用 xml:lang 进行语言切换
xml:lang 属性对于标记EPUB 3内容中的语言变化至关重要。您可以在内联元素(如 <span>)上使用它来标记短语,或在块级元素(如 <p> 或 <div>)上使用它来标记较长的部分。例如,如果您的英文书籍包含法语引文,您可以这样标记:
<span xml:lang="fr">Bonjour</span>
这向屏幕阅读器发出信号以切换到法语语音合成器,并确保可刷新的盲文显示器使用正确的盲文表。
来自波兰盲人和视力障碍者基金会"Trakt"的Monika Zarczuk-Engelsma强调了其重要性:
xml:lang属性可以在文本中用来标记用另一种语言书写的部分...这样,屏幕阅读器可以切换到与给定语言相对应的语音合成器。
对于从右到左阅读的语言,如阿拉伯语或希伯来语,在相关元素上的 xml:lang 旁边包含 dir="rtl"。这保持了正确的渲染和阅读顺序。始终使用两字符ISO代码(例如 en、es、fr)以确保各种屏幕阅读器的兼容性。
接下来,重要的是决定哪些实例真正受益于语言切换以保持流畅的阅读体验。
何时以及如何切换语言
并非每个外来词都需要语言标签。专有名词、技术术语或英语中常见的词语 - 如"piñata"或"Los Angeles" - 通常在上下文中能被理解,不需要发音改变。但是,另一种语言的完整短语、句子或段落应始终标记以满足WCAG A级标准。
避免标记简短的外来词,如名称,因为这可能会对盲文显示器用户造成不必要的和破坏性的语言切换。如果可能,将 xml:lang 应用于块级元素(如 <p>)而不是内联 <span> 标签,因为这提高了与辅助工具的兼容性。对于非语言内容(如ISBN或零件号),使用代码 zxx 表示内容不是任何人类语言。
非拉丁文字和字符集
处理非拉丁文字对于确保数字出版物的准确显示和功能至关重要。阿拉伯语、中文、希伯来语和西里尔字母等语言需要精确的技术设置以避免显示问题。缺少字体或不正确的语言代码可能导致"豆腐"字符 - 当设备缺少必要字体时出现的令人沮丧的白色方块或问号。为了解决这个问题,EPUB 3对于这些语言通常是必需的。主要零售商,包括Apple Books,对中文、日语、阿拉伯语、希伯来语、达里语、库尔德语、普什图语、旁遮普语、信德语、塔吉克语、维吾尔语和乌兹别克语等语言强制执行此标准 [3]。EPUB 3的原生Unicode支持对于准确呈现这些书写系统至关重要。
为非拉丁文字嵌入字体
嵌入字体确保在各个设备上显示一致。Sigil 和 Calibre 等工具简化了此过程。对于 Sigil,请按以下步骤操作:
-
将您的字体文件(最好是
.ttf格式)添加到"Fonts"文件夹。 -
使用
@font-face规则在CSS样式表中声明字体:@font-face { src: url(../Fonts/yourfont.ttf); font-family: "YourFontName"; } -
将样式表中的所有
font-family引用替换为您定义的名称。
在Calibre中,您可以通过使用"管理字体"工具并选择"嵌入所有字体"来自动化此过程。对于双语出版物,至少包含一种拉丁字体和一种非拉丁字体。始终在行业标准阅读器(如Adobe Digital Editions 3或4.5版本)中测试您的EPUB,以确认字符正确呈现。
避免将非拉丁文本转换为图像也很重要。这样做会使您的内容对屏幕阅读器无法访问,并阻止用户调整文本大小,这可能会损害无障碍性。
关于字体混淆的说明: 目前用于EPUB中字体混淆的SHA-1算法正在被逐步淘汰。根据 W3C发布维护工作组:
NIST建议到2030年底逐步淘汰SHA-1算法 [fips-180-4] 的使用。发布维护工作组不打算在该日期之后支持EPUB出版物中的字体混淆,因为它依赖于SHA-1 [4]。
嵌入字体后,下一步是确保通用Unicode支持。
Unicode兼容性
EPUB 3需要通用Unicode支持以在所有阅读系统中保持准确的字符数据。这消除了对文本图像的需求并确保无障碍性。为了满足此要求,将所有XHTML和CSS文件编码为UTF-8。
对于阿拉伯语和希伯来语等从右到左的文字,使用 dir 属性(例如 dir="rtl")来控制文本方向。设置 dir="auto" 允许阅读系统应用Unicode双向算法,确保正确的文本流。
| 文字/语言 | 常见传统编码 | Unicode标准 |
|---|---|---|
| 阿拉伯语 | ISO-8859-6, Windows-1256 | UTF-8 / UTF-16 |
| 西里尔字母 | ISO-8859-5, Windows-1251 | UTF-8 / UTF-16 |
| 希伯来语 | ISO-8859-8, Windows-1255 | UTF-8 / UTF-16 |
| 中文(简体) | GB2312, GB18030 | UTF-8 / UTF-16 |
| 中文(繁体) | Big5 | UTF-8 / UTF-16 |
使用Unicode字符而不是图像来保持无障碍性和文本重排能力。对于混合方向内容,如英文句子中的阿拉伯语短语,利用Unicode双向控制字符或适当的HTML标记来确保正确的呈现。这种方法在不同的语言和文字中保持了功能性和可读性。
测试和验证多语言EPUB
嵌入字体并确保Unicode兼容性后,下一步是验证多语言EPUB的无障碍性。此过程确保您的内容对所有读者无缝工作,包括那些依赖屏幕阅读器或文本转语音引擎等辅助技术的读者。测试有助于识别和修复可能限制访问的任何障碍。
使用验证工具测试语言标记
首先运行 EPUBCheck,EPUB 2和3的官方符合性检查器。此工具识别可能中断呈现的结构错误 [7]。如果您更喜欢图形界面,请考虑使用 Pagina EPUB-Checker 以便于导航 [9]。
EPUBCheck确认您的文件无错误后,继续使用 Ace by DAISY。此工具根据EPUB无障碍规范评估无障碍性。Kobo的内容销售经理Simon Collinson强调了其重要性:
关于Ace真正重要的是它使无障碍成为具有清晰步骤和严重程度层次的具体目标 [5]。
Ace用途广泛 - 它可以用作桌面应用程序或通过其命令行版本集成到自动工作流中 [5]。
为了确保正确处理语言切换和文本转语音(TTS)性能,使用 Thorium Reader 测试您的EPUB。此应用程序在epubtest.org的非视觉阅读中获得了完美分数 [8],特别适合进行这些检查。在"常规"选项卡中启用"增强屏幕阅读器体验"设置,以验证JAWS、NVDA或VoiceOver等屏幕阅读器是否正确为不同的语言标签切换语音 [6]。此外,测试"朗读"功能以确保正确的暂停和准确的发音,特别是对于非拉丁文字。这些步骤确认您的语言标签和元数据正确地指导辅助技术。
这些技术和无障碍测试完成后,继续进行更详细的WCAG合规性审查。
检查WCAG合规性
虽然Ace by DAISY等自动化工具提供了坚实的基础,但它们无法完全评估WCAG合规性。手动审查至关重要 [5]。首先系统地解决Ace报告中标记的任何问题,重点关注重复ID等区域,这可能会破坏ARIA属性引用和表格标题 - 两者对辅助技术都至关重要。
接下来,在Thorium Reader中直观地检查您的EPUB,以确认布局、字体和导航符合WCAG标准 [6][10]。对于多语言技术文档,特别要注意 MathML呈现和导航,因为这些对于使EPUB 3出版物无障碍至关重要 [8]。请记住,EPUBCheck有其局限性 - 它不会完全验证CSS或检测可能影响可用性的JavaScript问题 [9]。
为多语言EPUB使用 BookTranslator.ai
BookTranslator.ai简化了EPUB文件的翻译,同时确保无障碍性永远不会受到损害。创建无障碍的多语言EPUB时,保持原始结构、格式和语言标记至关重要。此平台无缝处理所有这些,提供超过99种语言的翻译,同时保持辅助技术所依赖的布局和功能。
该工具遵守BCP 47标准,确保翻译中的语言标记一致且准确。它使用精确的代码(如 en-US 或 en-GB)表示区域变体,以及脚本标签(如 zh-Hans 和 zh-Hant)表示不同的书写系统。为什么这很重要?正确的语言标记确保辅助技术可以平稳地切换语言并正确发音文本。如 DAISY联盟 所解释的:
"设置语言确保辅助技术正确解释和呈现文本,并且阅读系统可以为用户提供语言增强功能。"
- DAISY联盟
BookTranslator.ai不仅仅进行简单翻译。它保留原始布局、正确的语言标签(如 xml:lang 和 lang)以及正确的阅读顺序,以满足WCAG 2.x A级标准。具体来说,它符合成功标准3.1.1(页面语言)和3.1.2(部分语言),确保无障碍性融入每个翻译的EPUB中。
该服务也具有成本效益,基本计划起价为每100,000字$5.99,专业计划为每100,000字$9.99。它支持最大50MB的文件,甚至提供退款保证。这种经济性、效率和无障碍性的结合使其成为希望扩大多语言EPUB生产而不削减成本的出版商的绝佳选择。
结论
使多语言EPUB无障碍确保所有读者,无论其语言或阅读偏好如何,都可以与内容互动。这些步骤很简单但至关重要:在元数据中指定主要语言,对语言变化使用 xml:lang 属性,包含覆盖所有必要Unicode字符的字体,以及使用EPUBCheck和屏幕阅读器等工具验证您的EPUB。
满足 WCAG 2.x A级合规性 也至关重要,如法律框架所要求的 [2]。为了实现这一点,您的EPUB应包括三个关键Schema.org元数据属性:accessModeSufficient、accessibilityFeature 和 accessibilityHazard [2]。如W3C EPUB无障碍1.2规范所强调的:
"只有通过提供丰富的元数