
Varför METEOR är viktigt för AI-boköversättning
METEOR, förkortat för Metric for Evaluation of Translation with Explicit ORdering, är ett översättningsvärderingsverktyg som prioriterar betydelse och meningsflöde framför exakta ordöverenstämmelser. Till skillnad från BLEU, som förlitar sig på strikt ord-för-ord-justering, använder METEOR tekniker som stamming, synonymmatchning och omformulering för att bättre bedöma översättningskvaliteten. Detta gör det särskilt effektivt för bokövesättning, där det är kritiskt att fånga författarens röst, ton och narrativ flöde.
Viktiga insikter:
- Varför BLEU är otillräckligt: BLEUs strikta fokus på exakta ordöverenstämmelser straffar giltiga alternativ, kämpar med synonymer och misslyckas med att utvärdera narrativ sammanhang, vilket gör det olämpligt för litteratur.
- Hur METEOR fungerar: METEOR justerar översättningar med exakta matchningar, ordstammar, synonymer och omformuleringar. Det prioriterar återkallelse (betydelsetäckning) framför precision och tillämpar straff för dålig ordordning.
- Prestanda: METEOR uppnår en korrelation på 0,964 med mänsklig bedömning på korpusnivå, vilket överträffar BLEUs 0,817.
- Påverkan på bokövesättningar: Genom att fokusera på betydelse och flöde säkerställer METEOR att översättningar behåller djupet och läsbarheten i originaltexten, vilket gör den idealisk för AI-driven litterär översättning.
För plattformar som BookTranslator.ai möjliggör METEOR högkvalitativa översättningar över 99+ språk för så lågt som $5,99 per 100 000 ord, vilket gör litteratur tillgänglig för en global publik.
Problem med att utvärdera AI-bokövesättningar
Varför BLEU misslyckas för långformiga översättningar
BLEU (Bilingual Evaluation Understudy), ett mätvärde som infördes 2002, förlitar sig på strikt n-gram-matchning, som ofta misslyckas med att fånga subtiliteterna i litterär översättning.
Kärnan av problemet ligger i BLEUs tillvagagångssätt: det utvärderar kvaliteten genom att matcha 1- till 4-ordssekvenser exakt som de förekommer i en mänsklig referens. Denna stela metod kämpar med den kreativa flexibilitet som krävs för att översätta litteratur. Som NLLB-teamet förklarar:
"BLEU straffar giltiga alternativa översättningar. Om referensen säger 'the car is red' och systemet producerar 'the automobile is red,' straffar BLEU missmatchen även om betydelsen är identisk" [4].
Denna oförmåga att känna igen synonymer är särskilt problematisk för böcker, där ordval ofta bär betydande vikt. Till exempel behandlar BLEU "big" och "large" som helt olika ord, även om de betyder samma sak. På samma sätt tar det inte hänsyn till variationer som "running", "runs" och "ran", och straffar ofta översättningar som är både korrekta och kreativa.
En annan grundläggande begränsning är BLEUs korpusnivådesign. Den utvecklades ursprungligen för att hantera stora datamängder, inte den meningsnivåprecision som är kritisk för litteratur. BLEU saknar också förmågan att utvärdera meningsflöde eller narrativ sammanhang. Som NLLB noterar:
"BLEU tar inte direkt hänsyn till flytande eller betydelsebevarande - det är rent ett n-gram-överlappningsmått" [4].
Detta innebär att en översättning tekniskt sett kunde innehålla alla rätt ord men arrangera dem i en rörig, opålitlig ordning - och fortfarande få höga poäng. Dessa brister belyser behovet av värderingsmetoder som prioriterar sammanhang, sammanhang och den övergripande narrativa upplevelsen.
Varför sammanhang och betydelse är viktiga i böcker
Böcker är mer än bara samlingar av meningar - de är intrikata narrativ där varje ord, meningsstruktur och stilistisk val spelar en roll i att forma läsarens upplevelse. BLEUs snäva fokus på exakta ordöverenstämmelser missar denna större bild, särskilt när det gäller att upprätthålla narrativ flöde och sammanhang.
Gapet för semantisk förståelse är särskilt slående. Michael Brenndoerfer påpekar:
"Två semantiskt motsvarande översättningar kunde få mycket olika BLEU-poäng beroende på deras specifika ordval" [5].
Detta skapar ett problematiskt incitament för AI-system att jaga exakta ordöverenstämmelser istället för att sträva efter semantisk noggrannhet eller naturlig flytande.
Litterär översättning kräver en balans mellan precision och återkallelse - inte bara för att undvika fel utan också för att bevara djupet, tonen och den känslomässiga resonansen i originaltexten. BLEU betonar starkt precision, men böcker kräver mätvärden som mäter om översättningen fångar författarens avsikt och narrativ flöde. Verktyg som METEOR, som prioriterar betydelse och flöde genom att väga återkallelse nio gånger högre än precision, erbjuder en mer lämplig metod för att utvärdera litterära översättningar [1].
sbb-itb-0c0385d
METEOR : Ett mätvärde för maskinöversättning
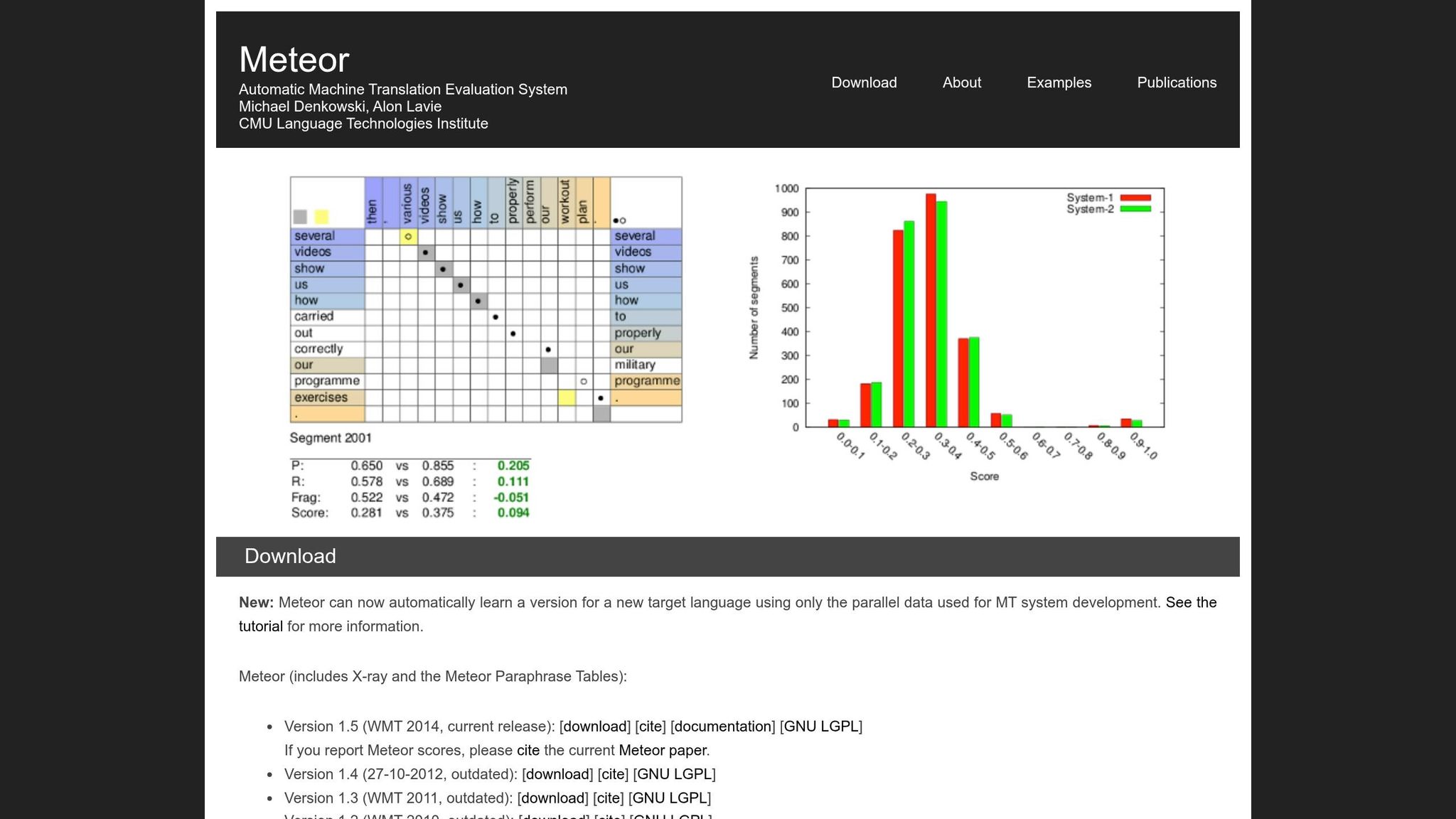
Vad är METEOR och hur fungerar det?
METEOR, förkortat för Metric for Evaluation of Translation with Explicit ORdering, introducerades 2005 av forskarna Satanjeev Banerjee och Alon Lavie vid Carnegie Mellon University. Det utvecklades för att ta itu med vissa begränsningar i BLEU, särskilt dess stela ord-för-ord-matchning. METEOR fokuserar på att bevara betydelse och naturlig ordordning, vilket gör det särskilt användbart för att utvärdera översättningar som behöver upprätthålla narrativ flöde - som bokövesättningar.
Måttet fungerar genom att justera enskilda ord i den kandidatöversättningen med ord i referensöversättningen. När det finns flera sätt att justera orden på väljer METEOR det med det minsta antalet "korsningar" (skärningar mellan kartläggninslinjer). Detta tillvagagångssätt hjälper till att upprätthålla en mer naturlig ordordning i värderingsprocessen [1].
Huvudfunktioner i METEOR
METEOR sticker ut på grund av sin nivåindelad matchningsmetod, som går bortom exakt ordmatchning. Det använder fyra sekventiella moduler för att utvärdera översättningar:
- Exakt matchning: Matchar identiska ordformer.
- Stamning: Matchar ord som delar samma rot, som "running" och "runs".
- Synonymi: Känner igen ord med liknande betydelser med hjälp av WordNet.
- Omformuleringmatchning: Matchar fraser med liknande semantiskt innehål.
Detta skiktade tillvagagångssätt tar itu med BLEUs kamp för att ta hänsyn till giltiga ordvariationer och alternativa uttryck [1][2][6].
METEORs poängsystem kombinerar två viktiga element. Först beräknar det ett vägt F-medelvärde av precision och återkallelse, där återkallelse vägs nio gånger tyngre än precision. Detta återspeglar hur människor tenderar att utvärdera översättningskvalitet, prioritera täckning av originalbetydelsen framför exakta matchningar [1]. För det andra tillämpar det en fragmenteringsstraff för att motverka översättningar där matchade ord är spridda eller ur ordning. Om de matchade orden är uppdelade i för många "bitar" kan poängen straffas med upp till 50%. Detta säkerställer att översättningar med rätt ord men dålig struktur - ofta kallad "ordgröt" - får lägre poäng [1].
Hur METEOR överensstämmer med mänsklig bedömning
Studier visar att METEOR korrelerar med mänsklig bedömning bättre än BLEU, och uppnår korrelationskoefficienter mellan 0,60 och 0,75, jämfört med BLEUs intervall på 0,45 till 0,60 [6].
Denna starkare överensstämmelse beror till stor del på METEORs meningsnivåfokus. Medan BLEU är utformat för att bedöma översättningar på korpusnivå, utvärderar METEOR enskilda meningar eller segment. Detta gör det särskilt effektivt för att bedöma det flöde och sammanhang som behövs i bokövesättningar [1]. Dessutom kan METEOR bearbeta upp till 500 segment per sekund per CPU-kärna, vilket gör det både effektivt och tillförlitligt för praktisk användning [2]. Dess förmåga att nära matcha mänsklig bedömning har befäst dess roll i att förbättra AI-driven bokövesättning.
METEOR kontra BLEU: Varför METEOR fungerar bättre för AI-bokövesättning

METEOR kontra BLEU Jämförelse av översättningsmätvärden
Viktiga fördelar med METEOR för bokövesättning
När det gäller att översätta litterära verk sticker METEOR ut som ett mer effektivt värderingsmätvärde än BLEU. Dess unika justeringsmetoder och fokus på betydelse gör det särskilt lämpat för nyanserna i bokövesättning.
En av de huvudsakliga skillnaderna är hur varje mätvärde hanterar semantisk noggrannhet. BLEU förlitar sig på exakta ordöverenstämmelser, vilket kan orättvist straffa översättningar som använder synonymer eller alternativa ordformer - även när betydelsen förblir intakt. METEOR, å andra sidan, innehåller stamning och synonymmatchning. Till exempel känner det igen att ord som "good" och "well" eller "runs" och "running" delar samma semantiska värde. Denna flexibilitet är väsentlig för litterära översättningar, där varierande ordförråd och kreativ formulering ofta är nödvändiga för att bevara författarens stil och avsikt.
En annan viktig skillnad är METEORs betoning på återkallelse framför precision. BLEU prioriterar precision genom att mäta hur många ord i den AI-genererade översättningen matchar ord i referenstexten. METEOR balanserar dock precision och återkallelse, med återkallelse vägt nio gånger tyngre [1]. Detta säkerställer att översättningen fångar hela betydelsen av originaltexten - en kritisk faktor för att korrekt förmedla komplexa narrativ.
METEOR utmärker sig också i meningsnivåutvärdering. Medan BLEU är anpassat för att utvärdera översättningar på korpusnivå, är METEOR utformat för att överensstämma nära med mänsklig bedömning på enskilda meningar eller segment. Det uppnår en maximal korrelation på cirka 0,403 på meningsnivå [1]. Detta gör det särskilt effektivt för att bedöma flödet och sammanhangen för specifika passager, vilket är nyckeln i bokövesättning.
En av METEORs framstående funktioner är dess fragmenteringsstraff, som tar itu med ordordning och meningsstruktur. Om matchade ord i översättningen är spridda i för många bitar kan poängen sjunka med så mycket som 50% [1]. Denna mekanism säkerställer att översättningar upprätthåller en naturlig och sammanhängande struktur - något som BLEU ofta förbiser. Genom att fokusera på dessa detaljer hjälper METEOR till att bevara originaltextens nyanserade betydelse och läsbarhet.
Jämförelsetabell: METEOR kontra BLEU
| Funktion | BLEU | METEOR |
|---|---|---|
| Primärt fokus | Precision (exakt ordöverläggning) | Återkallelse (betydelse och innehållstäckning) |
| Matchningskriterier | Exakt n-gram-matchning | Exakt, stamning, synonymer och omformuleringar |
| Semantisk noggrannhet | Låg (endast exakta ordöverenstämmelser) | Hög (inkluderar synonymer och stamning) |
| Mänsklig korrelation | Starkare på korpusnivå | Stark på både menings- och korpusnivå |
| Meningsstruktur | Indirekt (via n-gram-överlappningar) | Direkt (via fragmenteringsstraff och justering) |
| Flexibilitet | Stel; straffar kreativ formulering | Flexibel; belönar semantisk ekvivalens |
| Återkallelsehantring | Indirekt (brevitystraff) | Direkt (återkallelsberäkning vägt 9x mer) |
Hur METEOR används i AI-bokövesättningsplattformar
Säkerställande av kvalitet med METEOR
AI-drivna översättningsplattformar använder METEOR för att upprätthålla semantisk noggrannhet och upprätthålla de känsliga nyanserna i litterära verk. Processen börjar med justeringsmappning, där systemet identifierar anslutningar mellan den AI-genererade översättningen och en referenstext. Detta innebär att erkänna exakta matchningar, ordstammar, synonymer och till och med omformuleringar [2]. Sådan detaljerad mappning säkerställer att översättningen återspeglar originalbetydelsen, även om formuleringen skiljer sig.
För att hantera komplexiteten i olika språk konfigureras METEOR med språkspecifika verktyg som stammer och omformuleringtabeller. Till exempel använder plattformar som BookTranslator.ai, som stöder över 99 språk, dessa resurser för att ta itu med de unika lingvistiska strukturerna i olika språk. Oavsett om det är romanska språk som spanska och franska eller mer invecklade som arabiska och tjeckiska, är dessa verktyg viktiga för att fånga morfologiska variationer [2].
Det som sätter METEOR isär är dess förmåga att finjustera parametrar. Plattformar kan kalibrera dessa inställningar för att överensstämma med specifika värderingsuppgifter, såsom mätning av tillräcklighet eller upprätthållande av en konsekvent stil. Denna funktion är särskilt värdefull i litterära översättningar, där att bevara författarens röst och narrativets rytm är väsentligt. Dessutom säkerställer systemets fragmenteringsstraff att meningar flödar naturligt, vilket undviker den opålitliga, osammanhängande känslan av en enkel sträng av rätt ord. Denna uppmärksamhet på meningsflytande är kritisk för att hålla läsare absorberade i historien över hundratals sidor.
Bortom att förbättra översättningskvaliteten spelar METEOR också en central roll i att göra litteratur mer tillgänglig för en global publik.
Förbättring av flerspråkig tillgång till litteratur
Genom att skydda betydelsen och djupet i originaltexten förbättrar METEOR inte bara översättningskvaliteten utan hjälper också till att föra litteratur till läsare på deras modersmål. Med hjälp av parallella data möjliggör METEOR plattformar att expandera sitt språkutbud utan att offra kvalitet [2]. Denna förmåga att anpassa sig är särskilt viktig för läsare på underrepresenterade språkmarknader.
Det människocentrerade värderingssättet säkerställer att översättningar känns naturliga och engagerande. Till exempel tillhandahåller plattformar som BookTranslator.ai översättningar från $5,99 per 100 000 ord, vilket gör högkvalitativa översättningar överkomliga samtidigt som de behåller historiens narrativa charm och kulturella subtilitet. Genom att prioritera återkallelse framför precision fångar METEOR rikedomen i källtexten, inklusive intrikata karaktärsvägar och tematiska lager som är väsentliga för övertygande berättande.
Slutsats
METEOR förändrar spelet i AI-bokövesättningsutvärdering genom att prioritera semantisk noggrannhet och naturlig läsbarhet. Till skillnad från traditionella mätvärden tar METEOR hänsyn till synonymer, ordstammar och omformuleringar, och uppnår en imponerande korrelation på 0,964 med mänsklig bedömning på korpusnivå - betydligt högre än BLEUs 0,817 [1]. Detta säkerställer att översättningar behåller författarens stil, narrativ konsistens och subtila kulturella element.
Det som sätter METEOR isär är dess återkallelseviktade poäng kombinerat med ett fragmenteringsstraff, vilket säkerställer att översättningar inte bara fångar originaltextens fulla betydelse utan också läses smidigt. Detta är särskilt kritiskt för långformigt innehål, där att upprätthålla sammanhang och flöde över ett omfattande narrativ är väsentligt.
För plattformar som BookTranslator.ai, som stöder över 99 språk, möjliggör METEORs förmåga att känna igen språkliga variationer högkvalitativa översättningar till konkurrenskraftiga priser - från bara $5,99 per 100 000 ord. Genom att utnyttja parallella data för att lära sig nya målspråk [2] öppnar METEOR dörren för läsare i underförsörjda regioner att få tillgång till litteratur på sitt modersmål.
"METEOR fungerar mer som moderna röstigenknäckningssystem som förstår olika sätt att säga samma sak. Det utvärderar översättningar med flexibilitet, vilket speglar mänsklig bedömning." - Iterate.ai [3]
Vanliga frågor
Är METEOR tillräckligt för att bedöma kvaliteten på en bokövesättning?
METEOR är ett användbart verktyg för att mäta översättningskvalitet, särskilt när det gäller att identifiera semantiska nyanser och språkliga detaljer. Men att förlita sig på det ensamt är inte tillräckligt för att fullt ut utvärdera kvaliteten på en bokövesättning. Att para METEOR med mänsklig evaluering erbjuder ett mer balanserat och grundligt sätt att bedöma översättningskvalitet.
Hur hanterar METEOR idiom och kreativ formulering?
METEOR tacklar utmaningarna med idiom och kreativ formulering genom synonymmatchning, stamning och anpassningsbar språklig evaluering. Dessa verktyg gör det möjligt för den att förstå subtila, icke-bokstavliga uttryck, vilket säkerställer att översättningar bevarar både den avsedda betydelsen och den ursprungliga stilen.
Kan METEOR fånga konsistensfel under en hel roman?
METEOR är kapabel att upptäcka