
Har du någonsin tänkt på att ta en fysisk bok från din hylla och förvandla den till en perfekt översatt digital kopia? Det är magin med processen OCR och översättning. Det börjar med optisk teckenigenkänning (OCR) för att hämta texten från skannade sidor, och använder sedan maskinöversättning för att få den till ett nytt språk. Den här guiden går långt bortom enkla appar och presenterar ett professionellt arbetsflöde för att hantera böcker och annat långformat innehål med den precision de förtjänar.
Ditt moderna arbetsflöde för digital boköversättning
Att förvandla en tryckt bok till en polerad, översatt digital fil är ett verkligt projekt. Det är inte en enklickslösning utan en metodisk process utformad för att behålla författarens ursprungliga röst intakt samtidigt som den öppnas för en helt ny publik. Du bygger i princip en bro från den tryckta sidan till den digitala skärmen och förvandlar statisk bläck till dynamisk, redigerbar och sökbar data.
Framgång handlar verkligen om en serie noga genomtänkta steg, där varje steg förbereder vägen för nästa. Tänk på det som ett produktionsflöde för din bok.
De viktigaste stegen i boköversättning
Resan från en bunt papper till en färdig EPUB eller PDF omfattar några olika faser. Det här diagrammet ger dig en fågelöga på hela processen, från att få källmaterialet skannat till att formatera den slutliga filen.
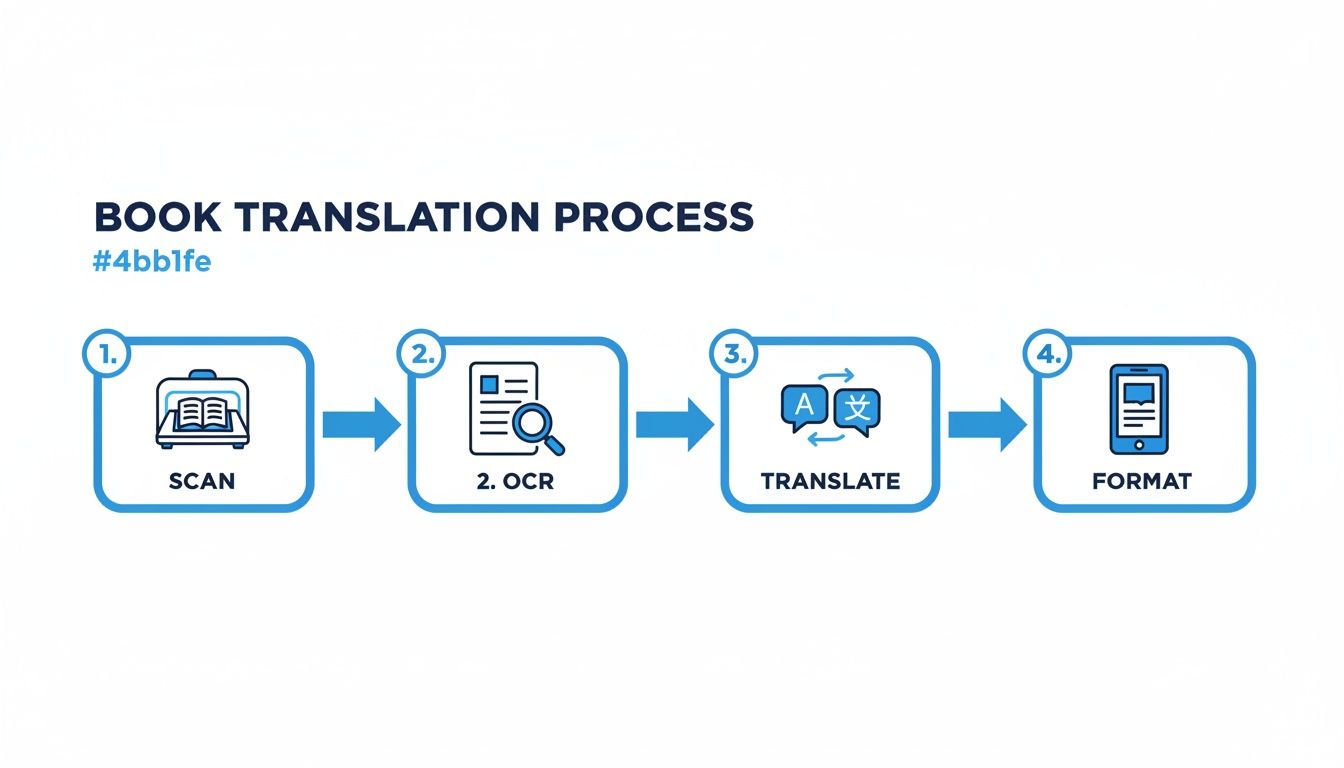
Var och en av dessa steg—Skanna, OCR, Översätta och Formatera—är en kritisk länk. Den kvalitet du får från en bestämmer direkt vilken kvalitet du kan lägga in i nästa.
Det här är inte längre bara en nischfärdighet; efterfrågan exploderar. Den globala marknaden för optisk teckenigenkänning nådde USD 13,95 miljarder 2024 och förväntas skjuta i väg förbi USD 46 miljarder till 2033, allt tack vare det massiva trycket på digitalisering världen över.
Viktig takeaway: För alla större projekt är ett strukturerat arbetsflöde absolut nödvändigt. Om du skyndar på skanningen eller sparar på att rensa upp den extraherade texten, skapar du bara massiva huvudvärk för dig själv senare, särskilt under översättning och formatering.
Som en del av ett modernt, professionellt arbetsflöde är det också avgörande att säkerställa GDPR-kompatibel AI-integrering, särskilt när du hanterar innehållet i hela böcker. Den här guiden ger dig den kompletta projektplanen för att säkert hantera storskaliga OCR- och översättningsprojekt från början till slut.
Förbered din bok för en felfri skanning
Ditt hela OCR- och översättningsprojekt beror på en sak: kvaliteten på dina initiala skanningar. Långt innan du ens tänker på att köra textigenkänningsprogramvaran måste du få detta första steg rätt. En suddig, sned eller dåligt upplyst skanning skapar en kaskad av fel, vilket lämnar dig med skräpig text och en översättningsmardrömm.
Tänk på det som matlagning. Den bästa kocken i världen kan inte göra en bra måltid med förstörd mat. Dina skanningar är dina ingredienser.

Det här är där din skanner blir ditt viktigaste verktyg. Glöm att använda en telefonapp för en hel bok; du får aldrig den konsekvens du behöver. För ett projekt av denna skala ger bara en flackbäddsskanner dig den kontroll och kvalitet som krävs.
Ställ in dina scannerinställningar
Att få dina scannerinställningar rätt är inte bara ett förslag—det är absolut kritiskt för att få ren, korrekt text. Ett par justeringar här kan spara dig otaliga timmar med smärtsamma manuella korrigeringar senare.
Jag har skannat hundratals böcker, från moderna pocketböcker till århundraden gamla volymer, och rätt inställningar gör all skillnad. För att hjälpa dig att komma igång, här är en snabb guide om vad du ska använda och varför.
Optimala scannerinställningar för bok-OCR
| Inställning | Rekommendation för moderna böcker | Rekommendation för äldre/komplexa böcker | Motivering |
|---|---|---|---|
| Upplösning (DPI) | 300-400 DPI | 400-600 DPI | 300 är minimikravet för klarhet. Gå högre för små typsnitt, blekt bläck eller komplexa layouter för att fånga mer detalj utan att öka filstorleken. |
| Färgläge | Gråskala | Gråskala | Gråskala fångar textnyanser bättre än hårt svartvitt läge och undviker de massiva filstorlekarna och färgstöjet från fullfärgsskanningar. |
| Filformat | TIFF | TIFF | TIFF är ett förlustfritt format. Det bevarar varje pixel perfekt och förhindrar komprimeringsartefakter som JPEG skapar, vilket kan förstöra OCR-noggrannheten. |
Dessa inställningar är ditt bästa alternativ för att fånga skarp text. Kom ihåg att målet är att ge OCR-programvaran den renaste möjliga data att arbeta med från början.
Min personliga regel: Använd aldrig JPEG för arkivala skanningar. Dess "förlustfulla" komprimering kastar bokstavligen bort data för att göra filerna mindre, vilket skapar luddiga artefakter omkring bokstäverna. Det är en genväg som alltid slutar kosta dig mer tid i korrigeringar.
Förbehandling: Rengöringsstadiet
Med dina sidor digitaliserade är du inte helt redo för OCR-motorn. En liten förbehandling rensar upp råskanningarna och ökar dina resultat dramatiskt. De flesta anständiga skanningsprogram innehåller dessa verktyg, men en gratis bildredigerare fungerar lika bra.
Här är vad jag alltid kontrollerar och fixar:
- Deskew: Det här är det viktigaste steget. Det rättar automatiskt ut alla sidor som skannas i en liten vinkel. Även en liten 1-graders lutning kan förvirra programvaran, så kör detta på varje enskild sida.
- Beskär: Bli av med de svarta kanterna och vilken del av scannerlocken som än hamnade i bilden. Du vill att programvaran ska fokusera endast på sidinnehållet, inte på skräpet omkring det.
- Kontrast/Ljusstyrka: Justera dessa nivåer för att få texten så mörk och bakgrunden så ljus som möjligt. Var försiktig så att du inte tvättar ut bokstäverna. Det här är en livräddare för gamla böcker med gula sidor eller blekt bläck.
Det här noggranna förberedelsesarbetet är vad som skiljer ett frustrande projekt från ett framgångsrikt.
När du väl har den pristina texten extraherad kan du tänka på det slutliga formatet. Om du debatterar hur du ska paketera din översatta bok, har vi en användbar guide som bryter ned fördelarna och nackdelarna med EPUB kontra PDF för AI-översättning.
Välja rätt OCR-verktyg för ren textextrahering
Med dina pristina skanningar klara är det dags att gå vidare till hjärtat av den digitala konverteringen: att välja rätt optisk teckenigenkänningsmotor. Det verktyg du väljer nu påverkar direkt kvaliteten på din råtext, vilket i sin tur lägger grunden för hela översättningsprocessen. När du tacklar en hel bok, inte bara någon OCR-programvara, kommer det inte att räcka till.
Du tittar i allmänhet på två vägar här: kraftfulla skrivbordsprogram eller mycket skalbara molnbaserade tjänster. Var och en har sin plats, och det bästa valet beror verkligen på ditt projekts specifika detaljer.

Det här gränssnittet från ABBYY FineReader visar upp en måste-ha-funktion för seriösa OCR-arbeten—möjligheten att se den ursprungliga skanningen och den igenkända texten sida vid sida. Det gör det enkelt att upptäcka och åtgärda fel.
Skrivbordsprogramvara kontra molntjänster
För dem som vill ha fullständig, granulär kontroll över processen är ett skrivbordsprogram som ABBYY FineReader ett långvarigt industrifavorit. Det är briljant på att hantera komplexa sidlayouter, känner igen en enorm lista över språk och ger dig verktyg för att manuellt rita rutor omkring exakt den text du vill fånga. Det här är en livräddare för att berätta för programvaran att ignorera irriterande sidhuvuden, sidfötter och sidnummer.
På andra sidan har du molnkraftpaket som Google Cloud Vision OCR och Amazon Textract. Dessa tjänster är byggda för skala. Istället för att binda upp din egen dator i timmar kan du mata dem hundratals eller till och med tusentals sidor på en gång och betala bara för vad du bearbetar. Deras AI-modeller förfinas konstant, så noggrannheten du får direkt från lådan är ofta imponerande.
Min två cents: Om jag arbetar med en enda bok med en verkligen konstigt design, håller jag mig till ett skrivbordsverktyg för den finjusterade kontrollen. Men om målet är att digitalisera en hel hylla med böcker med standardlayouter, är den rena hastigheten och batch-bearbetningskraften för en molntjänst det enda sättet att gå.
Ställ in dina OCR-inställningar för maximal noggrannhet
Oavsett vilket verktyg du landar på, tryck inte bara på "Kör"-knappen. Att ta några minuter för att konfigurera inställningarna i förväg sparar dig från en värld av manuell rengöring senare.
Här är det icke-förhandlingsbar:
- Ställ in igenkänningsspråket: Det här verkar uppenbart, men det är det viktigaste steget. Genom att uttryckligen berätta för programvaran källspråket (t.ex. tyska, japanska, spanska) läses in rätt teckenuppsättningar och ordböcker, vilket drastiskt minskar felfrekvensen.
- Definiera igenkänningszoner: Spendera en minut på några exempelsidor med att rita rutor omkring huvudtexten. Det här är hur du tränar OCR att ignorera sidnummer, löpande sidhuvuden och dekorativa gränser som bara kommer att förorena din slutliga textfil.
- Aktivera ordböcker: Om programvaran har denna funktion, slå på den. Det tillåter verktyget att kontrollera igenkända ord mot ett känt ordförråd, vilket hjälper det att själv korrigera vanliga misstag, som att blanda ihop "rn" med "m".
Denna initiala inställning är ditt första försvarslinje mot en rörig, felrik textfil.
Många av de bästa OCR- och översättningslösningarna drivs nu av sofistikerad AI; det är värt att titta på olika AI-verktyg för innehållsskapare för att se vad annat som kan komplettera ditt arbetsflöde. Detta tryck för smartare teknik är en enorm faktor i den växande översättningstjänstmarknaden, som värderades till 26,7 miljarder dollar 2024 och är på väg att nå 34,24 miljarder dollar till 2029. Den snabba tillväxten visar bara hur mycket efterfrågan det finns på högkvalitativ, effektiv lokalisering över hela världen.
Översätta innehål utan att förlora författarens röst
Att få ren text från din OCR-process är ett enormt steg, men nu kommer den verkliga utmaningen: översättning. Om du helt enkelt dumpar texten i ett standardöversättningsverktyg får du ord tillbaka, men författarens själ kommer att vara borta. Resultatet är ofta tekniskt korrekt men känslomässigt plant, strippat från den mycket personlighet som gjorde boken övertygande i första hand.
Målet är inte bara att byta ord från ett språk till ett annat. Det handlar om att troget överföra betydelse, stil och ton. Det bästa sättet att åstadkomma detta är med en hybridmetod—en som kombinerar den råa kraften i AI med den irreplaceerbara nyanseringen av en mänsklig expert.
Kombinera AI-hastighet med mänsklig insikt
Moderna översättningsplattformar som DeepL har helt förändrat spelet. De är otroligt bra på att förstå sammanhang och meningsstruktur och producerar översättningar som känns mycket mer naturliga än de klumpiga, bokstavliga resultaten från äldre system. Detta ger dig ett fantastiskt första utkast, ofta som slår ut på några minuter vad som skulle ta en mänsklig översättare veckor att slutföra.
Men för all sin sofistikering haltar AI fortfarande över subtiliteterna. Det förstår inte riktigt idiomatiska uttryck, kulturella insidor eller de unika stilistiska särdragen som definierar en författares röst. En lekfull vändning på spanska kan till exempel lätt bli stum och alltför formell på engelska om den översätts bokstavligt.
Det är exakt därför som en slutlig mänsklig granskning är absolut väsentlig för ett högkvalitativt resultat. Det ideala arbetsflödet är ett partnerskap:
- Få AI-förstaversionen: Börja med att köra din rena, OCR-extraherade text genom en toppmodern maskinöversättningsmotor.
- Hämta in människoexperten: En flytande talare läser sedan noggrant den översatta texten och jämför den med originalet för att fånga vad maskinen missade.
- Förfina och polera: Granskaren slätar ut otymplig formulering, korrigerar kulturella misstranslationer och finjusterar tonen tills den perfekt matchar författarens avsikt.
Denna en-två-kombination ger dig den otroliga effektiviteten hos AI utan att offra originalverkets hjärta. Vi dyker faktiskt mycket djupare in i det här ämnet i vår artikel om AI kontra mänskliga översättare och bevarade litterär stil.
Använda ordlistor och stilguider för konsekvens
När du arbetar på ett projekt så stort som en bok är konsekvens allt. Ingenting drar en läsare ur berättelsen snabbare än att se en huvudkaraktärs namn eller en fiktiv stad stavad annorlunda från ett kapitel till nästa. Det känns bara slarvigt.
Lyckligtvis ger moderna CAT-verktyg (datorstödd översättning) dig ett sätt att framtvinga konsekvens. De låter dig bygga projektspecifika resurser som vägleder hela översättningen, oavsett om det är en AI eller en människa som gör jobbet.
- Översättningsordlistor: Tänk på det här som en anpassad ordbok för din bok. Du kan definiera exakt hur nyckeltermer, teckens namn och specifika fraser måste översättas varje gång de visas.
- Stilguider: Det här är där du sätter lagen på ton och formalitet. Bör prosan vara samtalande eller akademisk? Finns det specifika fraser du vill undvika? En stilguide säkerställer att boken läses som en sammanhängande helhet, inte en samling av frånkopplade kapitel.
Genom att bygga en enkel ordlista framtvingar du konsekvens och minskar drastiskt den tid som spenderas på manuella korrigeringar. Det säkerställer att "El Bosque de las Sombras" alltid översätts som "The Forest of Shadows" och aldrig "The Woods of Shade."
Motorn som driver allt detta, Machine Translation (MT), är ett område som växer otroligt snabbt. Värderat till USD 1,12 miljarder 2025, förväntas marknaden nästan fördubblas till USD 2 miljarder till 2030. Denna boom drivs av Neural Machine Translation (NMT), som innehar en dominerande 48,67% marknadsandel tack vare sin överlägsna noggrannhet. Som du kan se från uppgången av MT-teknik från Global Growth Insights, gör denna teknik sofistikerade ocr och översätta arbetsflöden mer kraftfulla än någonsin. Att omfamna detta smarta, hybridtillvägagångssätt är ditt bästa alternativ för att skapa en slutprodukt som verkligen hedrar originalverket.
Sätt ihop det igen: Skapa din slutliga digitala bok
Du har gjort det. Skanningen, OCR-rengöringen och den noggranna översättningen är alla klara. Nu har du ett rent, översatt manuskript, och det är dags för den mest givande delen av processen: att bygga om det till en polerad, professionell digital bok.
Det här är där allt det noggranna förberedelsearbetet lönar sig. Du är i princip en digital typograf som tar råtexten och förvandlar den till en elegant EPUB eller en skarp PDF som läsare kommer att älska. Denna slutliga montering är vad som höjer en enkel textfil till en verkligt högkvalitativ läsupplevelse.
Från vanlig text till en strukturerad e-bok
Först och främst måste du föra din översatta text till ett e-bokskapningsverktyg. För att skapa reflowable EPUB:er—standarden för de flesta e-läsare som Kindle och Kobo—kan du inte gå fel med kraftfulla, kostnadsfria alternativ som Calibre eller Sigil. Om ditt projekt kräver en fast layout som efterliknar en tryckt bok, är Adobe InDesign industristandarden för jobbet.
Med din text importerad börjar det verkliga hantverket. Det här är inte bara ett copy-paste-jobb; du bygger systematiskt om bokens arkitektur för att säkerställa att den är läsbar och navigerbar.
- Kapitelbrytningar: Du måste infoga rena divisioner för att vägleda läsaren genom berättelsen.
- Rubriker och underrubriker: Att tillämpa rätt H1, H2 och H3-taggar skapar en logisk hierarki och en funktionell innehållsförteckning.
- Textformatering: Det är dags att återställa originalförfattarens avsikt genom att återställa kursiv, fet text och eventuella distinkta blockcitat.
- Bildplacering: Integrera noggrant originalillustrationer, diagram eller figurer i textflödet.

Verktyg som Calibre ger dig en otrolig mängd kontroll, så att du kan finjustera allt från omslagsbild och metadata till den underliggande CSS som bestämmer bokens utseende. För en djupare dyk, kolla in vår guide om toppverktyg för översättningsvänlig formatering.
Den slutliga QA: Validering och polering
Innan du öppnar champagnen finns det ett sista avgörande steg: en grundlig kvalitetskontroll (QA). En e-bok kan se makulös ut på ditt skrivbord men falla sönder på en faktisk e-läsare. Denna slutliga pass säkerställer att varje läsare får en konsekvent, professionell upplevelse, oavsett enhet.
Ett ord av råd från erfarenhet: Tänk inte ens på att hoppa över det här. En enda bruten bild eller ett missat kapitelbrott kan helt dra en läsare ur berättelsen och undergräva allt ditt hårda arbete.
Här är vad din slutliga QA-checklista bör se ut som:
- En fullständig formateringsgranskning: Gå igenom hela e-boken med en fin tandkam, titta bara på formateringsproblem. Är rubrikerna alla konsekventa? Ser styckeindragen rätt ut? Är bilderna korrekt justerade och bryter de inte över sidor?
- Testa på flera enheter: Det här är icke-förhandlingsbar. Ladda filen på så många enheter och appar som du kan. En Kindle, en Kobo, Apple Books, Google Play Books—se hur det ser ut på alla. Reflowable EPUB:er kan renderas överraskande olika från en plattform till en annan.
- Kör en EPUB-validering: Använd ett officiellt verktyg som EPUBCheck-valideraren för att se till att din fil är tekniskt sund och uppfyller industristandarder. Det här är ditt bästa försvar mot kompatibilitetsproblem som kan få din bok avvisad från onlinebutiker.
Genom att noggrant bygga om och polera din digitala bok skapar du en slutprodukt som verkligen hedrar originalverket. Du har framgångsrikt låst upp det för en helt ny publik genom ocr och översätta processen, och nu är det redo för dem att njuta av det.
Vanliga frågor om bok-OCR och översättning
Även med ett solidt arbetsflöde kan det att ta på sig ett helt boköversionsprojekt kasta några överraskningar på vägen. Låt oss ta itu med några av de vanligaste frågorna som dyker upp, från att navigera juridiska gränser till att sätta realistiska förväntningar på dina verktyg. Att ta reda på det här nu kan spara dig en värld av besvär senare.
Tänk på det som att balansera teknikens möjligheter med projektets praktiska realiteter. En liten framsynthet går långt.
Är det lagligt att skanna och översätta en upphovsrättsskyddad bok?
Det här är det stora, och ärligt talat lever det i ett juridiskt gråområde. På många ställen, inklusive USA, kan skanning av en bok du köpt för eget bruk falla under "rättvis användning"-principerna. Nyckelorden där är personligt bruk.
I det ögonblick du delar, distribuerar eller försöker sälja den översatta kopian, har du klättrat över en mycket tydlig linje in i upphovsrättsintrång. Det är olagligt om du inte har direkt tillstånd från den som innehar upphovsrätten.
Min två cents: Behandla denna hela process som ett sätt att få tillgång till innehål du redan äger. Det är för att läsa böcker du lagligt köpte, men på ditt eget språk. Dela eller sälja aldrig filerna du skapar. Och var alltid medveten om upphovsrättslagarna där du bor.
Hur bör jag hantera komplexa layouter som läroböcker eller tidningar?
Inte alla böcker är enkla, raka textblock. Läroböcker med call-out-boxar, tidningar med flera kolumner eller illustrerade romaner kan vara en mardröm för grundläggande OCR-verktyg. Det här är där professionell skrivbordsprogramv