
Почему METEOR важен для AI-перевода книг
METEOR, сокращение от Metric for Evaluation of Translation with Explicit ORdering (Метрика для оценки перевода с явным упорядочением), — это инструмент оценки перевода, который приоритизирует смысл и плавность предложения над точным совпадением слов. В отличие от BLEU, которая полагается на строгое выравнивание слово за словом, METEOR использует такие методы, как стемминг, сопоставление синонимов и парафразирование, чтобы лучше оценить качество переводов. Это делает его особенно эффективным для перевода книг, где критически важно передать голос автора, тон и ход повествования.
Ключевые выводы:
- Почему BLEU недостаточен: строгий фокус BLEU на точном совпадении слов штрафует допустимые альтернативы, испытывает трудности с синонимами и не может оценить связность повествования, что делает его непригодным для литературы.
- Как работает METEOR: METEOR выравнивает переводы, используя точные совпадения, корни слов, синонимы и парафразы. Он приоритизирует полноту (охват значения) над точностью и применяет штрафы за плохой порядок слов.
- Производительность: METEOR достигает корреляции 0,964 с человеческим суждением на уровне корпуса, превосходя BLEU с его 0,817.
- Влияние на переводы книг: сосредоточившись на смысле и плавности, METEOR гарантирует, что переводы сохраняют глубину и читаемость исходного текста, что делает его идеальным для AI-управляемых литературных переводов.
Для платформ, таких как BookTranslator.ai, METEOR обеспечивает высококачественные переводы на 99+ языков всего за $5,99 за 100 000 слов, делая литературу доступной для глобальной аудитории.
Проблемы оценки AI-переводов книг
Почему BLEU не работает для длинных переводов
BLEU (Bilingual Evaluation Understudy), метрика, введённая в 2002 году, полагается на строгое сопоставление n-грамм, которое часто не может уловить тонкости литературного перевода.
Суть проблемы заключается в подходе BLEU: она оценивает качество путём сопоставления последовательностей из 1-4 слов точно так, как они появляются в человеческом эталоне. Этот жёсткий метод испытывает трудности с творческой гибкостью, необходимой для перевода литературы. Как объясняет команда NLLB:
"BLEU штрафует допустимые альтернативные переводы. Если эталон говорит «the car is red» (автомобиль красный), а система выдаёт «the automobile is red» (автомобиль красный), BLEU штрафует несовпадение, хотя смысл идентичен" [4].
Эта неспособность распознавать синонимы особенно проблематична для книг, где выбор слова часто имеет значительный вес. Например, BLEU рассматривает "big" и "large" как совершенно разные слова, хотя они означают одно и то же. Аналогично, она не учитывает вариации вроде "running", "runs" и "ran", часто штрафуя переводы, которые одновременно точны и творческие.
Ещё одно основное ограничение — это конструкция BLEU на уровне корпуса. Она была первоначально разработана для работы с большими наборами данных, а не для точности на уровне предложения, которая критична для литературы. BLEU также не может оценить плавность предложения или связность повествования. Как отмечает NLLB:
"BLEU не учитывает текучесть или сохранение смысла напрямую — это чистая мера перекрытия n-грамм" [4].
Это означает, что перевод может технически содержать все правильные слова, но расположить их в запутанном, неловком порядке — и при этом получить хороший балл. Эти недостатки подчёркивают необходимость методов оценки, которые приоритизируют контекст, связность и общий опыт повествования.
Почему контекст и смысл важны в книгах
Книги — это не просто совокупность предложений, это сложные повествования, где каждое слово, структура предложения и стилистический выбор играют роль в формировании опыта читателя. Узкий фокус BLEU на точное совпадение слов упускает эту более широкую картину, особенно когда речь идёт о сохранении плавности повествования и связности.
Разрыв в семантическом понимании особенно вопиющий. Майкл Бренндёрфер указывает:
"Два семантически эквивалентных перевода могли бы получить очень разные баллы BLEU в зависимости от их конкретного выбора слов" [5].
Это создаёт проблемный стимул для AI-систем стремиться к точному совпадению слов вместо того, чтобы добиваться семантической точности или естественной текучести.
Литературный перевод требует баланса между точностью и полнотой — не только избегая ошибок, но и сохраняя глубину, тон и эмоциональный резонанс исходного текста. BLEU сильно подчёркивает точность, но книги требуют метрик, которые измеряют, захватывает ли перевод намерение автора и ход повествования. Инструменты, такие как METEOR, которые приоритизируют смысл и плавность, взвешивая полноту в девять раз выше точности, предлагают более подходящий подход для оценки литературных переводов [1].
sbb-itb-0c0385d
METEOR : метрика для машинного перевода
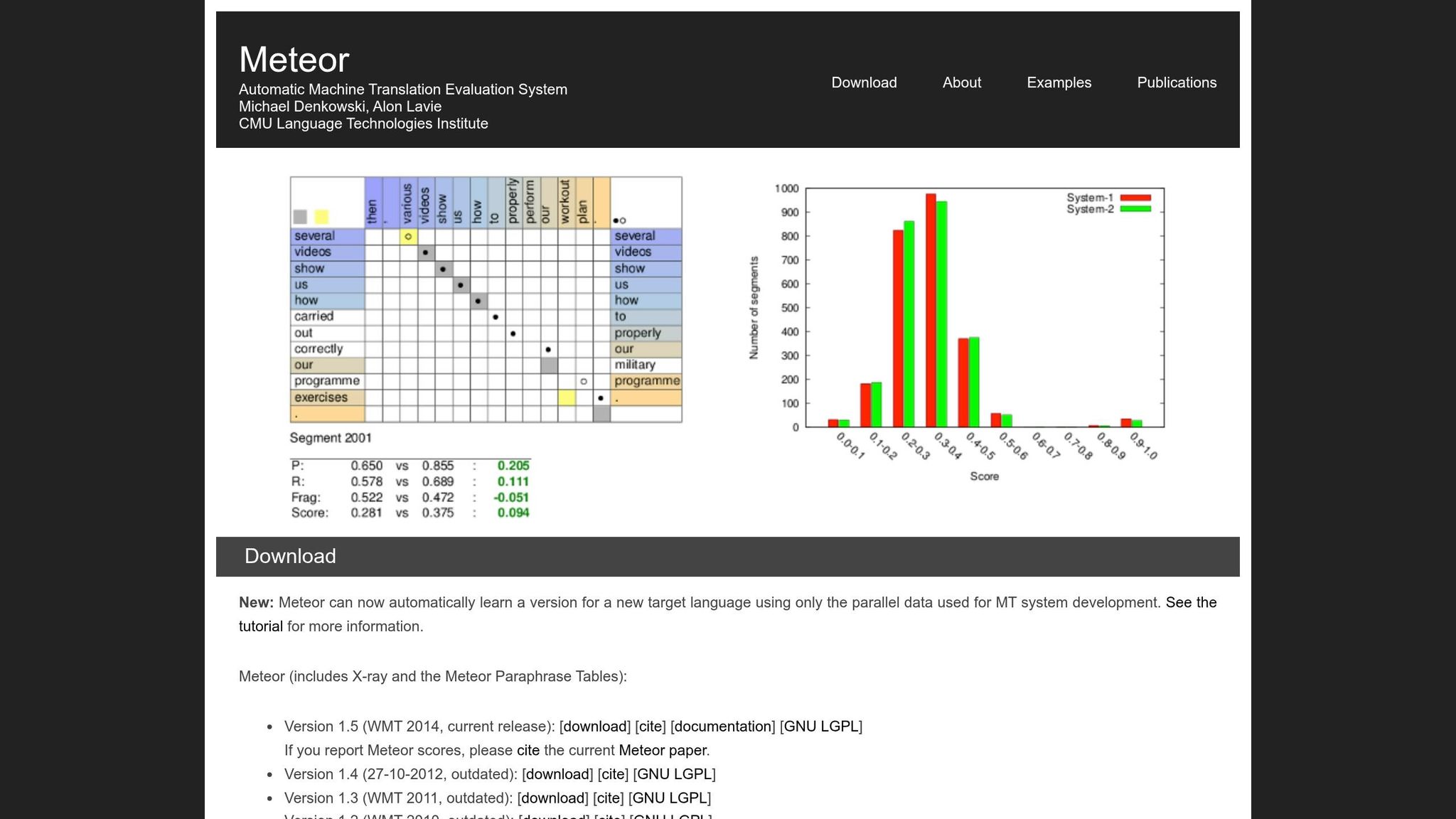
Что такое METEOR и как он работает?
METEOR, сокращение от Metric for Evaluation of Translation with Explicit ORdering, был представлен в 2005 году исследователями Сатанджевом Бэнерджи и Алоном Лави из Университета Карнеги-Меллона. Он был разработан для решения некоторых ограничений BLEU, особенно её жёсткого сопоставления слово за словом. METEOR сосредоточен на сохранении смысла и естественного порядка слов, что делает его особенно полезным для оценки переводов, которые должны сохранять ход повествования — таких как переводы книг.
Метрика работает путём выравнивания отдельных слов в кандидатском переводе с теми, что в эталонном переводе. Когда есть несколько способов выравнивания слов, METEOR выбирает тот, который имеет наименьшее количество "пересечений" (пересечений между линиями отображения). Этот подход помогает сохранить более естественный порядок слов в процессе оценки [1].
Основные возможности METEOR
METEOR выделяется благодаря своему многоуровневому подходу к сопоставлению, который выходит за рамки точного совпадения слов. Он использует четыре последовательных модуля для оценки переводов:
- Точное совпадение: сопоставляет идентичные формы слов.
- Стемминг: сопоставляет слова, которые имеют один корень, такие как "running" и "runs".
- Синонимия: распознаёт слова со схожими значениями, используя WordNet.
- Сопоставление парафраз: сопоставляет фразы со схожим семантическим содержанием.
Этот многоуровневый подход решает проблему BLEU с учётом допустимых вариаций слов и альтернативных выражений [1][2][6].
Система оценки METEOR объединяет два ключевых элемента. Во-первых, она вычисляет взвешенное F-среднее точности и полноты, при этом полнота взвешивается в девять раз больше, чем точность. Это отражает то, как люди склонны оценивать качество перевода, приоритизируя охват исходного смысла над точными совпадениями [1]. Во-вторых, она применяет штраф за фрагментацию, чтобы отговорить переводы, в которых совпадающие слова рассеяны или не по порядку. Если совпадающие слова разбиты на слишком много "фрагментов", балл может быть снижен на 50%. Это гарантирует, что переводы с правильными словами, но плохой структурой — часто называемые "словесной кашей" — получают более низкие баллы [1].
Как METEOR согласуется с человеческим суждением
Исследования показывают, что METEOR лучше коррелирует с человеческим суждением, чем BLEU, достигая коэффициентов корреляции между 0,60 и 0,75, по сравнению с диапазоном BLEU от 0,45 до 0,60 [6].
Эта более сильная согласованность в значительной степени обусловлена фокусом METEOR на уровне предложения. В то время как BLEU предназначена для оценки переводов на уровне корпуса, METEOR оценивает отдельные предложения или сегменты. Это делает его особенно эффективным для оценки плавности и связности, необходимых при переводе книг [1]. Кроме того, METEOR может обрабатывать до 500 сегментов в секунду на ядро CPU, что делает его эффективным и надёжным для практического использования [2]. Его способность тесно соответствовать человеческому суждению укрепила его роль в улучшении AI-управляемых переводов книг.
METEOR vs. BLEU: почему METEOR лучше работает для AI-перевода книг

Сравнение метрик перевода METEOR vs BLEU
Ключевые преимущества METEOR для перевода книг
Когда речь идёт о переводе литературных произведений, METEOR выделяется как более эффективная метрика оценки, чем BLEU. Его уникальные методы выравнивания и фокус на смысле делают его особенно подходящим для тонкостей перевода книг.
Одно из основных различий — это то, как каждая метрика обрабатывает семантическую точность. BLEU полагается на точное совпадение слов, что может несправедливо штрафовать переводы, использующие синонимы или альтернативные формы слов — даже когда смысл остаётся неизменным. METEOR, с другой стороны, включает стемминг и сопоставление синонимов. Например, он распознаёт, что слова вроде "good" и "well" или "runs" и "running" имеют одно и то же семантическое значение. Эта гибкость необходима для литературных переводов, где разнообразный словарь и творческое формулирование часто необходимы для сохранения стиля и намерения автора.
Ещё одно важное различие — это акцент METEOR на полноту над точностью. BLEU приоритизирует точность, измеряя, сколько слов в AI-генерируемом переводе совпадают с теми, что в эталонном тексте. METEOR, однако, уравновешивает точность и полноту, при этом полнота взвешивается в девять раз больше [1]. Это гарантирует, что перевод охватывает полный смысл исходного текста — критический фактор для точной передачи сложных повествований.
METEOR также превосходит в оценке на уровне предложения. В то время как BLEU адаптирована для оценки переводов на уровне корпуса, METEOR разработана для близкого согласования с человеческим суждением на отдельных предложениях или сегментах. Она достигает максимальной корреляции около 0,403 на уровне предложения [1]. Это делает её особенно эффективной для оценки плавности и связности конкретных отрывков, что является ключевым при переводе книг.
Одна из выдающихся особенностей METEOR — это штраф за фрагментацию, который решает вопрос порядка слов и структуры предложения. Если совпадающие слова в переводе рассеяны на слишком много фрагментов, балл может упасть на целых 50% [1]. Этот механизм гарантирует, что переводы сохраняют естественную и связную структуру — то, что BLEU часто упускает. Сосредоточившись на этих деталях, METEOR помогает сохранить тонкий смысл и читаемость исходного текста.
Таблица сравнения: METEOR vs. BLEU
| Особенность | BLEU | METEOR |
|---|---|---|
| Основной фокус | Точность (точное совпадение слов) | Полнота (охват смысла и содержания) |
| Критерии сопоставления | Точное сопоставление n-грамм | Точное совпадение, стемминг, синонимы и парафразы |
| Семантическая точность | Низкая (только точные совпадения слов) | Высокая (включает синонимы и стемминг) |
| Корреляция с человеком | Сильнее на уровне корпуса | Сильна на уровне предложения и корпуса |
| Структура предложения | Косвенная (через перекрытие n-грамм) | Прямая (через штраф за фрагментацию и выравнивание) |
| Гибкость | Жёсткая; штрафует творческое формулирование | Гибкая; вознаграждает семантическую эквивалентность |
| Обработка полноты | Косвенная (штраф за краткость) | Прямая (расчёт полноты, взвешенный в 9 раз больше) |
Как METEOR используется в платформах AI-перевода книг
Обеспечение качества с помощью METEOR
Платформы перевода на основе AI используют METEOR для сохранения семантической точности и соблюдения деликатных нюансов литературных произведений. Процесс начинается с выравнивания отображения, где система определяет связи между AI-генерируемым переводом и эталонным текстом. Это включает распознавание точных совпадений, корней слов, синонимов и даже парафраз [2]. Такое детальное отображение гарантирует, что перевод отражает исходный смысл, даже если формулировка отличается.
Для работы со сложностями различных языков METEOR настраивается с помощью языковых инструментов, таких как стеммеры и таблицы парафраз. Например, платформы, такие как BookTranslator.ai, которые поддерживают более 99 языков, используют эти ресурсы для решения уникальных лингвистических структур различных языков. Будь то романские языки, такие как испанский и французский, или более сложные, такие как арабский и чешский, эти инструменты необходимы для захвата морфологических вариаций [2].
Что выделяет METEOR, так это его способность точно настраивать параметры. Платформы могут калибровать эти параметры для согласования с конкретными задачами оценки, такими как измерение адекватности или сохранение последовательного стиля. Эта особенность особенно ценна при литературных переводах, где сохранение голоса автора и ритма повествования необходимо. Кроме того, штраф системы за фрагментацию гарантирует, что предложения текут естественно, избегая неловкого, разрозненного ощущения простой строки правильных слов. Это внимание к плавности предложения критично для того, чтобы читатели оставались поглощены историей на протяжении сотен страниц.
Помимо улучшения качества переводов, METEOR также играет ключевую роль в повышении доступности литературы для глобальной аудитории.
Улучшение многоязычного доступа к литературе
Защищая смысл и глубину исходного текста, METEOR не только улучшает качество перевода, но и помогает донести литературу до читателей на их родных языках. Используя параллельные данные, METEOR позволяет платформам расширять свои языковые предложения без ущерба для качества [2]. Эта способность к адаптации особенно важна для читателей на недостаточно представленных языковых рынках.
Подход оценки, ориентированный на человека, гарантирует, что переводы кажутся естественными и привлекательными. Например, платформы, такие как BookTranslator.ai, предоставляют переводы начиная с $5,99 за 100 000 слов, обеспечивая высококачественные переводы при доступной цене, сохраняя при этом повествовательное очарование и культурные тонкости истории. Приоритизируя полноту над точностью, METEOR охватывает богатство исходного текста, включая сложные дуги персонажей и тематические слои, которые необходимы для убедительного рассказа.
Заключение
METEOR изменяет игру в оценке AI-перевода книг, приоритизируя семантическую точность и естественную читаемость. В отличие от традиционных метрик, METEOR учитывает синонимы, корни слов и парафразы, достигая впечатляющей корреляции 0,964 с человеческим суждением на уровне корпуса — значительно выше, чем 0,817 BLEU [1]. Это гарантирует, что переводы сохраняют стиль автора, последовательность повествования и тонкие культурные элементы.
То, что выделяет METEOR, — это её взвешенная по полноте система оценки в сочетании со штрафом