
Когда-нибудь задумывались о том, чтобы взять физическую книгу с полки и превратить её в идеально переведённую цифровую копию? Это волшебство процесса распознавания текста и перевода. Всё начинается с оптического распознавания символов (OCR) для извлечения текста со сканированных страниц, а затем используется машинный перевод для перевода на новый язык. Это руководство выходит далеко за рамки простых приложений, представляя профессиональный рабочий процесс для работы с книгами и другим контентом большого объёма с той точностью, которую они заслуживают.
Ваш современный рабочий процесс для цифрового перевода книг
Превращение печатной книги в отполированный переведённый цифровой файл — это настоящий проект. Это не одноклик, а методичный процесс, разработанный для сохранения оригинального голоса автора, открывая его совершенно новой аудитории. По сути, вы строите мост от печатной страницы к цифровому экрану, преобразуя статические чернила в динамичные, редактируемые и поддающиеся поиску данные.
Успех действительно зависит от серии тщательных шагов, каждый из которых подготавливает почву для следующего. Думайте об этом как о конвейере для вашей книги.
Основные этапы перевода книги
Путь от стопки бумаги к готовому EPUB или PDF включает несколько отдельных фаз. Эта диаграмма даёт вам общее представление всего процесса, от сканирования исходного материала до форматирования финального файла.
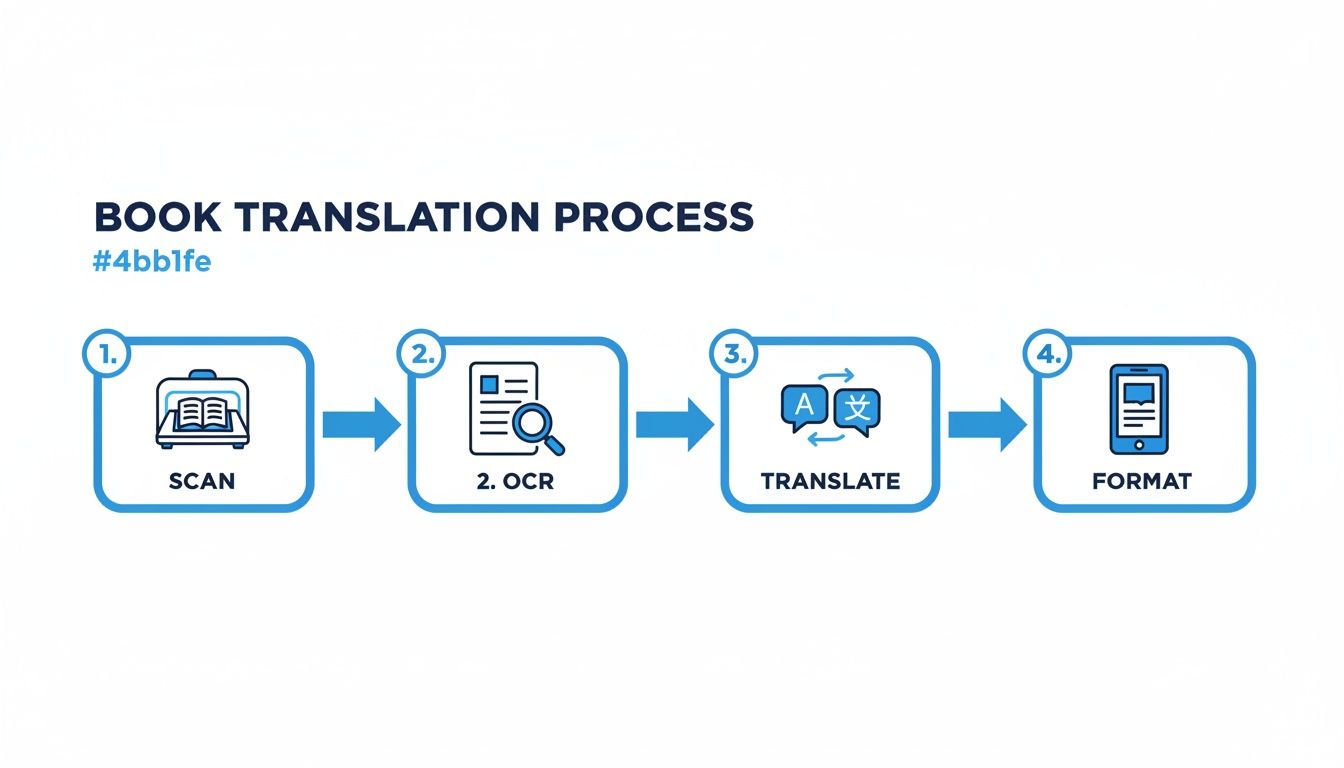
Каждый из этих этапов — сканирование, OCR, перевод и форматирование — это критическое звено. Качество, которое вы получаете на одном этапе, напрямую определяет качество, которое вы можете вложить в следующий.
Это больше не узкоспециальный навык; спрос стремительно растёт. Глобальный рынок оптического распознавания символов достиг 13,95 млрд USD в 2024 году и, как ожидается, превысит 46 млрд USD к 2033 году, благодаря массовому толчку к цифровизации во всём мире.
Ключевой вывод: Для любого крупного проекта структурированный рабочий процесс — это обязательное условие. Если вы поспешите со сканированием или сэкономите на очистке извлечённого текста, вы просто создаёте себе огромные проблемы в дальнейшем, особенно во время перевода и форматирования.
В рамках любого современного профессионального рабочего процесса также важно обеспечить интеграцию ИИ в соответствии с GDPR, особенно когда вы работаете с контентом целых книг. Это руководство даст вам полный план проекта для уверенного управления крупномасштабными проектами OCR и перевода от начала до конца.
Подготовка книги к безупречному сканированию
Весь ваш проект OCR и перевода зависит от одного: качества ваших первоначальных сканов. Задолго до того, как вы даже начнёте думать о запуске программного обеспечения распознавания текста, вам нужно сделать этот первый шаг правильно. Размытый, искривлённый или плохо освещённый скан создаст каскад ошибок, оставляя вас с искажённым текстом и кошмаром перевода.
Думайте об этом как о кулинарии. Лучший шеф-повар в мире не может приготовить отличное блюдо из испорченных ингредиентов. Ваши сканы — это ваши ингредиенты.

Здесь ваш сканер становится вашим наиболее важным инструментом. Забудьте об использовании приложения для телефона для целой книги; вы никогда не получите необходимую последовательность. Для проекта такого масштаба только планшетный сканер даёт вам необходимый контроль и качество.
Настройка параметров сканера
Правильная настройка параметров сканера — это не просто предложение, это абсолютно критично для получения чистого, точного текста. Несколько изменений здесь могут сэкономить вам бесчисленные часы болезненных ручных исправлений в дальнейшем.
Я отсканировал сотни книг, от современных мягких обложек до многовековых томов, и правильные настройки имеют решающее значение. Чтобы помочь вам начать, вот краткое руководство о том, что использовать и почему.
Оптимальные параметры сканера для OCR книг
| Параметр | Рекомендация для современных книг | Рекомендация для старых/сложных книг | Обоснование |
|---|---|---|---|
| Разрешение (DPI) | 300–400 DPI | 400–600 DPI | 300 — это минимум для чёткости. Увеличивайте для мелких шрифтов, выцветших чернил или сложных макетов, чтобы захватить больше деталей без раздутия размера файла. |
| Цветовой режим | Оттенки серого | Оттенки серого | Оттенки серого лучше захватывают нюансы текста, чем жёсткий чёрно-белый режим, и избегают огромных размеров файлов и цветного шума полноцветных сканов. |
| Формат файла | TIFF | TIFF | TIFF — это формат без потерь. Он идеально сохраняет каждый пиксель, предотвращая артефакты сжатия, которые создают JPEG и могут испортить точность OCR. |
Эти параметры — ваш лучший выбор для захвата чёткого текста. Помните, цель — дать программному обеспечению OCR самые чистые возможные данные с самого начала.
Моё личное правило: Никогда, никогда не используйте JPEG для архивных сканов. Его «сжатие с потерями» буквально выбрасывает данные, чтобы сделать файлы меньше, создавая нечёткие артефакты вокруг букв. Это ярлык, который всегда обходится вам дороже в исправлениях.
Предварительная обработка: этап очистки
С оцифрованными страницами вы ещё не совсем готовы к двигателю OCR. Небольшая предварительная обработка очистит необработанные сканы и значительно повысит ваши результаты. Большинство приличного программного обеспечения для сканирования включает эти инструменты, но бесплатный редактор изображений работает так же хорошо.
Вот что я всегда проверяю и исправляю:
- Выпрямление: Это самый важный шаг. Он автоматически выпрямляет любую страницу, которая была отсканирована под небольшим углом. Даже небольшой наклон в 1 градус может сбить программное обеспечение, поэтому запустите это на каждой странице.
- Кадрирование: Избавьтесь от чёрных границ и любой части крышки сканера, которая попала в изображение. Вы хотите, чтобы программное обеспечение сосредоточилось только на содержимом страницы, а не на мусоре вокруг.
- Контрастность/яркость: Отрегулируйте эти уровни, чтобы текст был как можно более тёмным, а фон как можно более светлым. Будьте осторожны, чтобы не размыть буквы. Это спасение для старых книг с пожелтевшими страницами или выцветшими чернилами.
Эта тщательная подготовительная работа отличает разочаровывающий проект от успешного.
Как только у вас будет безупречный извлечённый текст, вы можете подумать о финальном формате. Если вы размышляете о том, как упаковать переведённую книгу, у нас есть полезное руководство, которое разбирает плюсы и минусы EPUB и PDF для AI-перевода.
Выбор правильных инструментов OCR для чистого извлечения текста
С готовыми безупречными сканами пора переходить к сердцу цифрового преобразования: выбору правильного двигателя оптического распознавания символов (OCR). Выбранный вами инструмент напрямую влияет на качество вашего необработанного текста, что, в свою очередь, создаёт основу для всего процесса перевода. Когда вы работаете над целой книгой, а не просто над фрагментом, не подойдёт любое программное обеспечение OCR.
Вы обычно смотрите на два пути здесь: мощные настольные приложения или высокомасштабируемые облачные сервисы. Каждый имеет своё место, и лучший выбор действительно зависит от особенностей вашего проекта.

Этот интерфейс от ABBYY FineReader демонстрирует обязательную функцию для серьёзной работы OCR — возможность видеть исходный скан и распознанный текст рядом. Это облегчает обнаружение и исправление ошибок.
Настольное программное обеспечение и облачные сервисы
Для тех, кто хочет полный, детальный контроль над процессом, настольное приложение, такое как ABBYY FineReader, является давним любимцем индустрии. Оно блестяще справляется со сложными макетами страниц, распознаёт огромный список языков и предоставляет инструменты для ручного рисования полей вокруг точного текста, который вы хотите захватить. Это спасение для указания программному обеспечению игнорировать надоедливые заголовки, нижние колонтитулы и номера страниц.
С другой стороны, у вас есть облачные гиганты, такие как Google Cloud Vision OCR и Amazon Textract. Эти сервисы построены для масштабирования. Вместо того, чтобы занимать ваш собственный компьютер на часы, вы можете отправить им сотни или даже тысячи страниц одновременно и платить только за то, что вы обрабатываете. Их модели ИИ постоянно совершенствуются, поэтому точность, которую вы получаете прямо из коробки, часто впечатляет.
Мой совет: Если я работаю над одной книгой с действительно своеобразным дизайном, я буду придерживаться настольного инструмента для этого точного контроля. Но если цель — оцифровать целую полку книг со стандартными макетами, чистая скорость и возможность пакетной обработки облачного сервиса — это единственный способ.
Настройка параметров OCR для максимальной точности
Независимо от того, какой инструмент вы выберете, не просто нажимайте кнопку «Начать». Потратив несколько минут на предварительную настройку параметров, вы сэкономите себя от мира ручной очистки позже.
Вот обязательные пункты:
- Установите язык распознавания: Это кажется очевидным, но это самый важный шаг. Явное указание программному обеспечению исходного языка (например, немецкий, японский, испанский) загружает правильные наборы символов и словари, резко снижая частоту ошибок.
- Определите зоны распознавания: Потратьте минуту на несколько примеров страниц, рисуя поля вокруг основного текста. Это то, как вы обучаете OCR игнорировать номера страниц, работающие заголовки и декоративные границы, которые только загрязнят ваш финальный текстовый файл.
- Включите словари: Если программное обеспечение имеет эту функцию, включите её. Это позволяет инструменту проверять распознанные слова в известном словаре, что помогает ему самостоятельно исправлять распространённые ошибки, такие как спутывание «rn» с «m».
Эта начальная настройка — ваша первая линия защиты от беспорядочного, полного ошибок текстового файла.
Многие из лучших решений OCR и перевода теперь работают на основе сложного ИИ; стоит изучить различные инструменты ИИ для создателей контента, чтобы увидеть, что ещё может дополнить ваш рабочий процесс. Этот толчок к более умным технологиям — огромный фактор в растущем рынке услуг перевода, который оценивался в 26,7 млрд долларов в 2024 году и, как ожидается, достигнет 34,24 млрд долларов к 2029 году. Быстрый рост просто показывает, насколько велик спрос на высокое качество и эффективную локализацию по всему миру.
Перевод контента без потери голоса автора
Получить чистый текст из процесса OCR — это огромный шаг, но теперь наступает настоящий вызов: перевод. Если вы просто бросите текст в стандартный инструмент перевода, вы получите слова в ответ, но душа автора исчезнет. Результат часто технически правильный, но эмоционально плоский, лишённый той самой личности, которая делала книгу привлекательной.
Цель — это не просто заменить слова с одного языка на другой. Речь идёт о верном переносе смысла, стиля и тона. Лучший способ это сделать — это гибридный подход, который сочетает в себе сырую мощь ИИ с незаменимыми нюансами человеческого эксперта.
Сочетание скорости ИИ с человеческим пониманием
Современные платформы переводов, такие как DeepL, полностью изменили игру. Они невероятно хороши в понимании контекста и структуры предложения, создавая переводы, которые кажутся намного более естественными, чем громоздкие, буквальные результаты старых систем. Это даёт вам фантастический первый вариант, часто выполняя за минуты то, что заняло бы у человеческого переводчика недели.
Но при всей своей сложности ИИ всё ещё спотыкается на тонкостях. Он не совсем понимает идиоматические выражения, культурные внутренние шутки или уникальные стилистические особенности, которые определяют голос автора. Игривый оборот фразы по-испански, например, может легко стать жёстким и чрезмерно формальным по-английски, если переводить буквально.
Это именно то, почему окончательный человеческий пересмотр абсолютно необходим для высокого качества результата. Идеальный рабочий процесс — это партнёрство:
- Получите первый вариант ИИ: Начните с запуска вашего чистого, извлечённого OCR текста через первоклассный двигатель машинного перевода.
- Привлеките человеческого эксперта: Свободно говорящий человек затем внимательно прочитает переведённый текст, сравнивая его с оригиналом, чтобы поймать то, что пропустила машина.
- Уточните и отполируйте: Рецензент разглаживает неловкие фразы, исправляет культурные неправильные переводы и точно настраивает тон, пока он идеально не совпадёт с намерением автора.
Это одно-двойной удар даёт вам невероятную эффективность ИИ без ущерба для сердца оригинальной работы. Мы фактически гораздо глубже погружаемся в эту тему в нашей статье о ИИ и человеческих переводчиках и сохранении литературного стиля.
Использование глоссариев и руководств по стилю для обеспечения согласованности
Когда вы работаете над проектом размером с книгу, согласованность — это всё. Ничто не выбивает читателя из истории быстрее, чем видение имени главного персонажа или вымышленного города, написанного по-разному от одной главы к другой. Это просто выглядит небрежно.
К счастью, современные инструменты CAT (компьютеризированный перевод) дают вам способ обеспечить согласованность. Они позволяют вам создавать специфичные для проекта ресурсы, которые направляют весь перевод, выполняется ли он ИИ или человеком.
- Глоссарии перевода: Думайте об этом как о пользовательском словаре для вашей книги. Вы можете точно определить, как ключевые термины, имена персонажей и конкретные фразы должны переводиться каждый раз, когда они появляются.
- Руководства по стилю: Здесь вы устанавливаете правила по тону и формальности. Должна ли проза быть разговорной или академической? Есть ли конкретные фразы, которых вы хотите избежать? Руководство по стилю гарантирует, что книга читается как связное целое, а не как набор отдельных глав.
Построив простой глоссарий, вы обеспечиваете согласованность и драматически сокращаете время, потраченное на ручные исправления. Это гарантирует, что «El Bosque de las Sombras» всегда переводится как «The Forest of Shadows» и никогда как «The Woods of Shade».
Двигатель, приводящий всё это в действие, машинный перевод (MT), — это область, которая растёт невероятно быстро. Оценивается в 1,12 млрд USD в 2025 году, рынок, как ожидается, почти удвоится до 2 млрд USD к 2030 году. Этот бум вызван нейронным машинным переводом (NMT), который удерживает доминирующую 48,67% долю рынка благодаря его превосходной точности. Как вы видите из роста технологии MT от Global Growth Insights, эта технология делает сложные рабочие процессы распознавания и перевода более мощными, чем когда-либо. Принятие этого умного гибридного подхода — ваш лучший выбор для создания финального продукта, который действительно почитает оригинальную работу.
Собираем всё вместе: создание вашей финальной цифровой книги
Вы добрались. Сканирование, очистка OCR и тщательный перевод — всё сделано. Теперь у вас есть чистая переведённая рукопись, и пришло время для самой полезной части процесса: переделка её в отполированную, профессиональную цифровую книгу.
Здесь вся эта кропотливая подготовительная работа окупается. По сути, вы цифровой наборщик, берущий необработанный текст и преобразующий его в элегантный EPUB или чёткий PDF, который читатели будут любить. Эта финальная сборка — это то, что превращает простой текстовый файл в действительно высокое качество опыт чтения.
От простого текста к структурированной электронной книге
Прежде всего, вам нужно привести переведённый текст в инструмент создания электронных книг. Для создания рефлоуируемых EPUB — стандарта для большинства электронных читалок, таких как Kindle и Kobo — вы не ошибётесь с мощными бесплатными опциями, такими как Calibre или Sigil. Если ваш проект требует фиксированного макета, который имитирует печатную книгу, то Adobe InDesign — это инструмент стандарта индустрии для работы.
С импортированным текстом начинается настоящее мастерство. Это не просто работа копирования и вставки; вы методично перестраиваете архитектуру книги, чтобы убедиться, что она читаема и навигируема.
- Разрывы глав: Вам нужно вставить чистые разделения, чтобы направить читателя через повествование.
- Заголовки и подзаголовки: Применение правильных тегов H1, H2 и H3 создаёт логическую иерархию и функциональное оглавление.
- Стиль текста: Пришло время вернуть намерение оригинального автора, восстановив курсив, жирный текст и любые отличительные цитаты.
- Размещение изображений: Тщательно переинтегрируйте оригинальные иллюстрации, диаграммы или диаграммы в поток текста.

Инструменты, такие как Calibre, дают вам невероятное количество контроля, позволяя вам точно настроить всё, от изображения обложки и метаданных до основного CSS, который определяет внешний вид книги. Для более глубокого погружения ознакомьтесь с нашим руководством по