
Метрики точности перевода: объяснение
Метрики точности перевода помогают оценить, насколько хорошо машинные переводы соответствуют эталонам, созданным человеком. Эти инструменты имеют решающее значение для оценки качества перевода, особенно при работе с крупномасштабными проектами или критически важным контентом. Метрики делятся на три категории:
- Строковые метрики: BLEU, METEOR и TER сосредоточены на совпадении слов или символов.
- Нейросетевые метрики: COMET и BERTScore анализируют семантическое сходство с использованием моделей искусственного интеллекта.
- Оценка человеком: Прямые оценки, такие как MQM, сосредоточены на адекватности и беглости.
Ключевые выводы:
- BLEU: Быстрая и простая, но испытывает трудности с синонимами и более глубоким смыслом.
- METEOR: Учитывает синонимы и лингвистические нюансы; лучше подходит для литературных произведений.
- TER: Измеряет усилия редактирования, но игнорирует семантическое качество.
- COMET и BERTScore: Продвинутые модели искусственного интеллекта, которые хорошо согласуются с оценками человека, отлично подходят для текстов с нюансами.
Для переводов книг сочетание автоматизированных инструментов с оценкой человеком обеспечивает точность и сохраняет исходный стиль. Платформы, такие как BookTranslator.ai, используют этот гибридный подход для предоставления надежных результатов более чем на 99 языках.
Распространённые метрики точности перевода
BLEU Score
Введённая в 2002 году, BLEU (Bilingual Evaluation Understudy) остаётся основной метрикой для оценки машинного перевода [4]. Она работает, сравнивая точность n-грамм, что означает анализ того, как последовательности слов в выходных данных машины совпадают с эталонными переводами. Баллы BLEU варьируются от 0 до 1, при этом более высокие числа указывают на лучшее качество. Её главное преимущество? Скорость и простота — BLEU может обрабатывать тысячи переводов быстро, что делает её весьма практичной. Эта эффективность даже принесла ей награду NAACL 2018 Test-of-Time.
Как объяснили Папинени и др., «Основная идея состоит в использовании взвешенного среднего совпадений n-грамм переменной длины между переводом системы и набором эталонных переводов человека» [4].
Однако BLEU имеет заметное ограничение: она приоритизирует точные совпадения слов. Это означает, что она может недооценить переводы, которые передают один и тот же смысл, но используют другую формулировку. Чтобы решить эту проблему, такие метрики как METEOR стремятся уловить лингвистические нюансы.
METEOR Metric
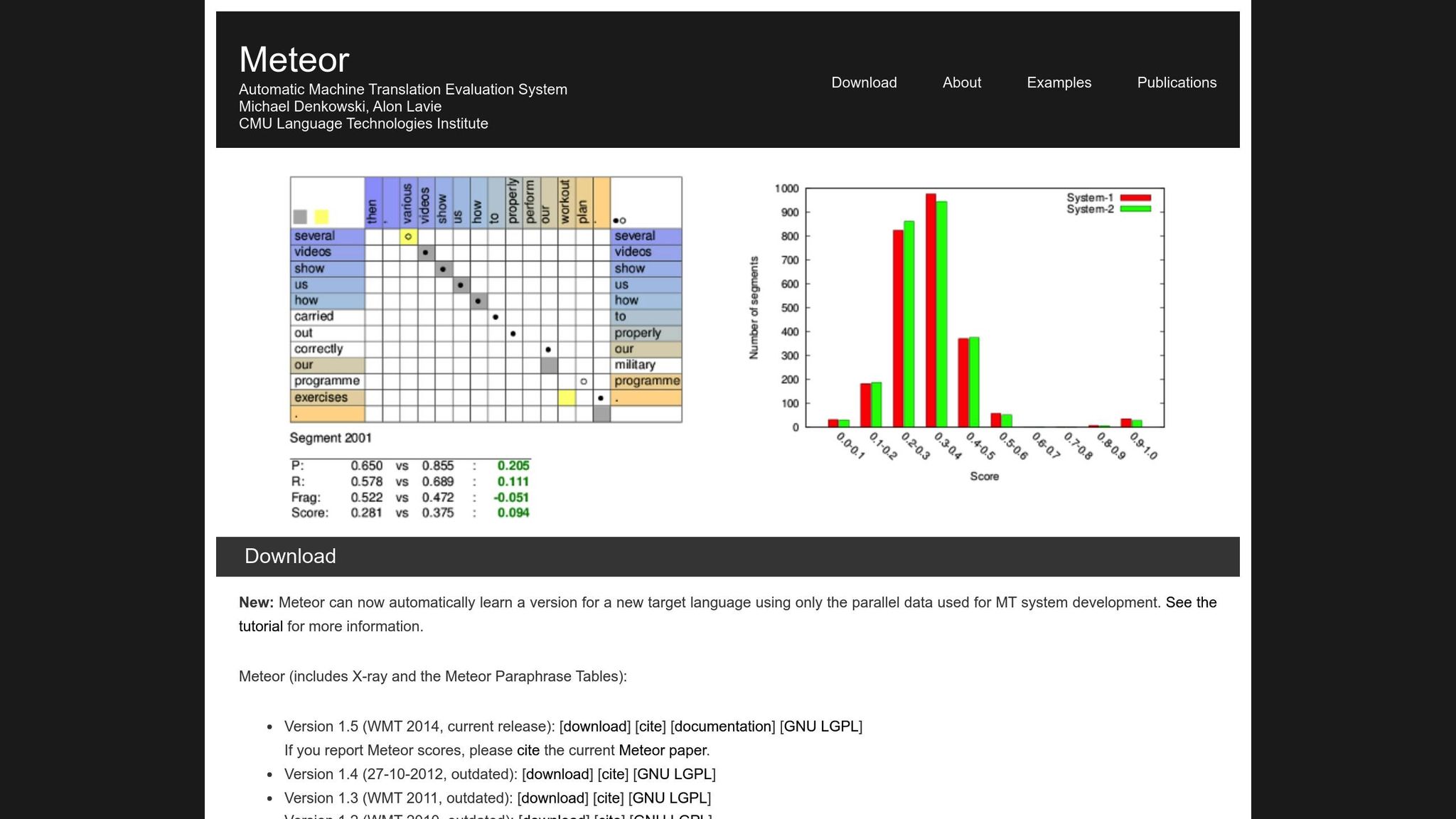
METEOR (Metric for Evaluation of Translation with Explicit ORdering) улучшает BLEU, учитывая точность, полноту, синонимы, основание слова и штрафы за порядок слов [1]. Она обрабатывает вариации, такие как «running» в сравнении с «ran» или «happy» в сравнении с «joyful», что делает её более подходящей для переводов, где смысл имеет наибольшее значение. Например, во время конкурса NIST MetricsMaTr10 METEOR-next-rank достигла корреляции Спирмена 0,92 с оценками человека на уровне системы и 0,84 на уровне документа [1].
При этом METEOR имеет свои собственные трудности. Она требует дополнительных ресурсов, таких как базы данных синонимов и алгоритмы основания слова, что увеличивает её вычислительную нагрузку. Тем не менее, она часто обеспечивает более детальную и надёжную оценку, особенно для определения семантической точности.
Translation Edit Rate (TER)
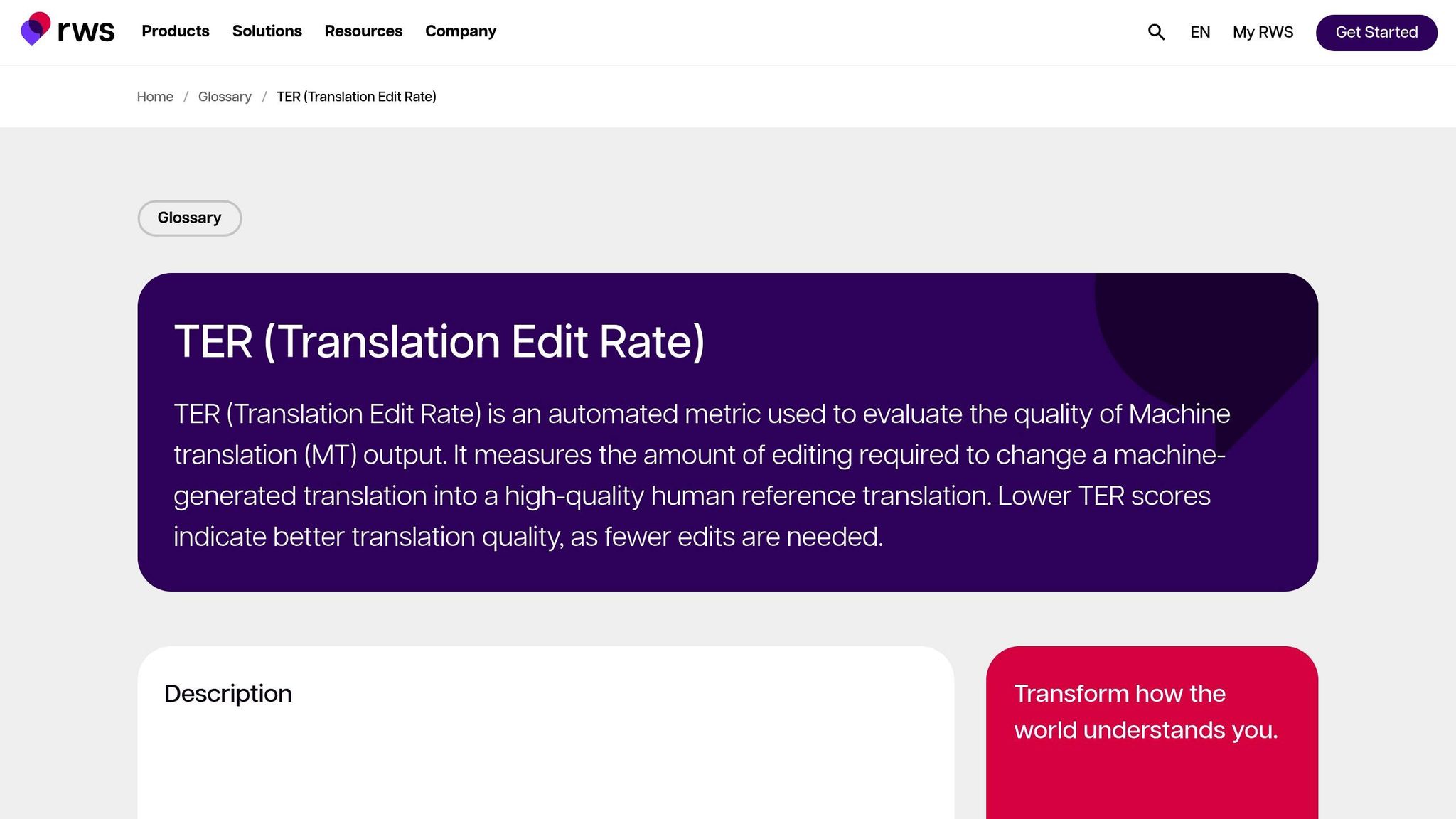
TER оценивает качество перевода, рассчитывая количество правок — вставок, удалений, подстановок и сдвигов — необходимых для преобразования выходных данных машины в эталон. Это делает её особенно полезной для оценки усилий редактирования, необходимых для согласования выходных данных с желаемым результатом. В оценках MetricsMaTr10 TER-v0.7.25 продемонстрировала корреляцию на уровне системы 0,89 с оценками человека семантической адекватности, в то время как TERp показала корреляцию на уровне сегмента 0,68 [1].
Нейросетевые метрики: BERTScore, COMET и GEMBA
Нейросетевые метрики поднимают оценку перевода на новый уровень, сосредоточиваясь на семантическом анализе, а не на точных совпадениях слов. Вот краткий обзор:
- BERTScore: Использует контекстные вложения для измерения сходства между переводами.
- COMET: Интегрирует исходный текст, гипотезу и эталонные переводы в нейросетевую структуру, обученную на аннотациях человека. Она достигла некоторых из самых высоких корреляций с оценками качества человека [5].
- GEMBA: Использует большие языковые модели для оценки качества без обучения, предлагая более близкое приближение к оценке человека.
Хотя эти метрики мощные, они имеют компромиссы. В отличие от BLEU и TER, которые могут работать на стандартных процессорах за миллисекунды, нейросетевые метрики, такие как BERTScore и COMET, часто требуют ускорения GPU для эффективной обработки больших наборов данных. GEMBA, в частности, может включать высокие затраты на API и потенциальные предубеждения от больших языковых моделей, что делает её менее доступной для некоторых пользователей.
Автоматические метрики для оценки систем машинного перевода
Сравнение метрик перевода

Сравнение метрик точности перевода: BLEU, METEOR, TER, BERTScore, COMET и GEMBA
Таблица сравнения метрик
Выбор правильной метрики перевода часто зависит от направления вашей оценки и доступных ресурсов. Традиционные метрики, такие как BLEU, быстрые и требуют минимальных ресурсов, но испытывают трудности с захватом более глубокого семантического смысла. С другой стороны, нейросетевые метрики преуспевают в понимании контекста и смысла, но требуют больше вычислительной мощности.
Недавние исследования предлагают отойти от метрик, основанных на перекрытии. Например, результаты WMT22 рекомендуют отказаться от метрик, таких как BLEU, в пользу нейросетевых подходов [6]. Исследование выделяет, что метрики перекрытия, такие как BLEU, spBLEU и chrF, плохо коррелируют с оценками экспертов-людей.
Вот быстрое сравнение ключевых метрик перевода, охватывающее области их применения, методы оценки, корреляцию с оценкой человеком, ограничения и пригодность для переводов книг:
| Метрика | Область применения | Диапазон оценок | Корреляция с оценкой человеком | Ограничения | Пригодность для переводов книг |
|---|---|---|---|---|---|
| BLEU | Точность N-грамм | 0 до 1 (или 0-100) | Низкая до средней | Испытывает трудности с синонимами [7][8] | Низкая; не способна захватить литературный стиль |
| METEOR | Точность, полнота, синонимы, порядок слов | 0 до 1 | Высокая | Требует языкоспецифичных ресурсов [7] | Средняя; полезна для согласованной терминологии |
| TER | Расстояние редактирования (усилия пост-редактирования) | 0 до 1 (ниже лучше) | Средняя | Игнорирует семантическое качество [7] | Низкая; сосредоточена на механике, не на «голосе» |
| BERTScore | Семантическое сходство через контекстные вложения | 0 до 1 | Высокая | Требует много ресурсов [7] | Высокая; захватывает более глубокий смысл и контекст |
| COMET | Семантическое сходство и беглость | 0 до 1 (0.5-0.8 типичные) | Очень высокая | Требует предварительно обученные модели [7][8] | Высокая; сохраняет стиль и нюансированный смысл |
| GEMBA | Комплексная оценка на основе LLM | Варьируется | Высокая | Сложная настройка; дорогостоящие API [7] | Высокая; предлагает «похожий на человека» комплексный обзор |
Эта таблица подчёркивает, как различные метрики соответствуют конкретным потребностям перевода. Для технических переводов метрики, такие как BLEU и TER, обеспечивают быстрые базовые ориентиры. Однако для литературных переводов — где стиль, тон и нюансированный смысл имеют решающее значение — нейросетевые метрики, такие как BERTScore и COMET, работают намного лучше. Эти инструменты особенно хороши в захватывании глубины и артистизма литературных текстов, которые традиционные метрики часто упускают [7].
Например, платформы, такие как BookTranslator.ai, которые стремятся сбалансировать эффективность и качество, значительно выигрывают от нейросетевых метрик. Инструменты, такие как BERTScore и COMET, обеспечивают сохранение как семантической точности, так и литературного стиля.
Чтобы поставить вещи в перспективу, «хороший» балл BLEU обычно составляет от 30 до 40, при этом баллы выше 40 считаются сильными, а всё выше 50 указывает на высокое качество перевода [8]. Для COMET баллы обычно варьируются от 0.5 до 0.8, при этом значения ближе к 1.0 отражают качество перевода, близкое к человеческому [8]. Нейросетевые метрики не только работают последовательно для различных типов текстов, но и лучше адаптируются к различным контекстам по сравнению с чувствительными к домену метриками, такими как BLEU [6].
sbb-itb-0c0385d
Методы оценки человеком
Автоматизированные метрики могут предложить скорость и согласованность, но они часто упускают тонкие детали, которые определяют качество перевода. Именно здесь вступает человеческая оценка как золотой стандарт[2]. Хотя это медленнее и дороже, человеческая оценка раскрывает более глубокие причины проблем качества — вещи, которые метрики, такие как BLEU или COMET, просто не могут выявить[9].
Есть два основных подхода к оценке человеком. Один — это Непосредственно выраженное суждение (DEJ), когда переводы оцениваются по шкалам, таким как беглость и адекватность. Другой включает методы без DEJ, которые сосредоточены на выявлении и категоризации конкретных ошибок, часто используя структуры, такие как MQM[12]. Хотя аналитические методы разбивают отдельные ошибки и их серьёзность, целостные методы рассматривают общее качество. Вместе эти подходы образуют основу структур, таких как MQM.
MQM (Многомерные метрики качества)

Когда автоматизированные инструменты оказываются недостаточными, MQM предлагает более детальную и практичную альтернативу. Она разбивает ошибки перевода на категории, такие как Точность, Беглость, Терминология, Локальные соглашения и Дизайн/Разметка, а не суммирует качество одним числом[18, 17].
«В отличие от этого, автоматизированные метрики обычно предоставляют только число без указания на то, как улучшить результаты.»
– Комитет MQM[10]
Ошибки оцениваются по серьёзности: Нейтральная (отмечена, но приемлема, без штрафа), Незначительная (немного заметна, вес штрафа 1), Серьёзная (влияет на понимание, вес штрафа 5) и Критическая (делает текст непригодным, вес штрафа 25)[11]. Для критических переводов, таких как юридические документы, пороги прохождения могут быть установлены так высоко, как 99.5 по шкале сырых баллов[11].
Что делает MQM особенно полезной, так это её способность выявлять конкретные проблемные области. Например, если литературный перевод получает низкую оценку, MQM может выявить, заключается ли проблема в неловкой формулировке или несогласованной терминологии. Этот уровень детализации особенно ценен для платформ, таких как BookTranslator.ai, где захватывание как смысла, так и литературного стиля имеет существенное значение.
Оценка адекватности и беглости
Опираясь на структурированные структуры, такие как MQM, оценивающие также сосредоточены на двух ключевых аспектах качества перевода: адекватности и беглости. Адекватность измеряет, насколько хорошо перевод передаёт смысл исходного текста, в то время как беглость оценивает, насколько естественно и читаемо он звучит для носителей языка. Эти аспекты часто оцениваются по пятибалльным шкалам[9].
Балансировка этих двух измерений может быть сложной, особенно в литературных переводах. Сохранение голоса исходного автора при обеспечении гладкого чтения текста на целевом языке требует тщательного внимания.
Чтобы уточнить этот процесс, оценивающие используют Прямую оценку (DA), которая оценивает переводы в одноязычном, двуязычном или основанном на эталоне форматах[9]. Скалярная метрика качества (SQM