
Por que o METEOR é importante para a tradução de livros com IA
METEOR, abreviação de Metric for Evaluation of Translation with Explicit ORdering (Métrica para Avaliação de Tradução com Ordenação Explícita), é uma ferramenta de avaliação de tradução que prioriza o significado e o fluxo de sentença em vez de correspondências exatas de palavras. Diferentemente do BLEU, que depende do alinhamento rigoroso palavra por palavra, o METEOR usa técnicas como stemming, correspondência de sinônimos e paráfrase para avaliar melhor a qualidade das traduções. Isso o torna especialmente eficaz para traduzir livros, onde capturar a voz do autor, o tom e o fluxo narrativo é crítico.
Principais insights:
- Por que o BLEU é insuficiente: O foco rigoroso do BLEU em correspondências exatas de palavras penaliza alternativas válidas, tem dificuldade com sinônimos e falha em avaliar a coerência narrativa, tornando-o inadequado para literatura.
- Como o METEOR funciona: O METEOR alinha traduções usando correspondências exatas, raízes de palavras, sinônimos e paráfrases. Prioriza a cobertura de significado (recall) em vez de precisão e aplica penalidades para ordem de palavras inadequada.
- Desempenho: O METEOR alcança uma correlação de 0,964 com o julgamento humano no nível de corpus, superando o BLEU com 0,817.
- Impacto nas traduções de livros: Ao focar no significado e no fluxo, o METEOR garante que as traduções retenham a profundidade e legibilidade do texto original, tornando-o ideal para traduções literárias impulsionadas por IA.
Para plataformas como BookTranslator.ai, o METEOR permite traduções de alta qualidade em mais de 99 idiomas por apenas $5,99 por 100.000 palavras, tornando a literatura acessível a um público global.
Problemas com a Avaliação de Traduções de Livros com IA
Por que o BLEU Falha em Traduções de Longa Forma
BLEU (Bilingual Evaluation Understudy), uma métrica introduzida em 2002, depende de correspondência rigorosa de n-gramas, que frequentemente falha em capturar as sutilezas da tradução literária.
O cerne da questão está na abordagem do BLEU: ele avalia a qualidade comparando sequências de 1 a 4 palavras exatamente como aparecem em uma referência humana. Este método rígido tem dificuldade com a flexibilidade criativa necessária para traduzir literatura. Como a equipe do NLLB explica:
"O BLEU penaliza traduções alternativas válidas. Se a referência diz 'the car is red' e o sistema produz 'the automobile is red', o BLEU penaliza a discrepância, mesmo que o significado seja idêntico" [4].
Esta incapacidade de reconhecer sinônimos é particularmente problemática para livros, onde a escolha de palavras muitas vezes tem peso significativo. Por exemplo, o BLEU trata "big" e "large" como palavras completamente diferentes, embora signifiquem a mesma coisa. Da mesma forma, não leva em conta variações como "running", "runs" e "ran", frequentemente penalizando traduções que são precisas e criativas.
Outra limitação fundamental é o design de nível de corpus do BLEU. Foi originalmente desenvolvido para lidar com grandes conjuntos de dados, não com a precisão de nível de sentença crítica para literatura. O BLEU também carece da capacidade de avaliar o fluxo de sentença ou coerência narrativa. Como o NLLB observa:
"O BLEU não leva em conta a fluência ou preservação de significado diretamente - é puramente uma medida de sobreposição de n-gramas" [4].
Isso significa que uma tradução poderia tecnicamente incluir todas as palavras corretas, mas organizá-las em uma ordem confusa e desajeitada - e ainda assim obter uma boa pontuação. Essas deficiências destacam a necessidade de métodos de avaliação que priorizem contexto, coerência e a experiência narrativa geral.
Por que Contexto e Significado Importam em Livros
Livros são mais do que apenas coleções de sentenças - são narrativas intrincadas onde cada palavra, estrutura de sentença e escolha estilística desempenha um papel na formação da experiência do leitor. O foco estreito do BLEU em correspondências exatas de palavras perde essa visão maior, especialmente quando se trata de manter fluxo narrativo e coerência.
A lacuna de compreensão semântica é particularmente gritante. Michael Brenndoerfer aponta:
"Duas traduções semanticamente equivalentes poderiam receber pontuações BLEU muito diferentes dependendo de suas escolhas de palavras específicas" [5].
Isso cria um incentivo problemático para os sistemas de IA perseguirem correspondências exatas de palavras em vez de buscar precisão semântica ou fluência natural.
A tradução literária exige um equilíbrio entre precisão e recall - não apenas evitar erros, mas também preservar a profundidade, tom e ressonância emocional do texto original. O BLEU enfatiza muito a precisão, mas livros exigem métricas que meçam se a tradução captura a intenção do autor e o fluxo narrativo. Ferramentas como o METEOR, que priorizam significado e fluxo ponderando o recall nove vezes mais do que a precisão, oferecem uma abordagem mais adequada para avaliar traduções literárias [1].
sbb-itb-0c0385d
METEOR : Uma métrica para tradução automática
O que é METEOR e Como Funciona?
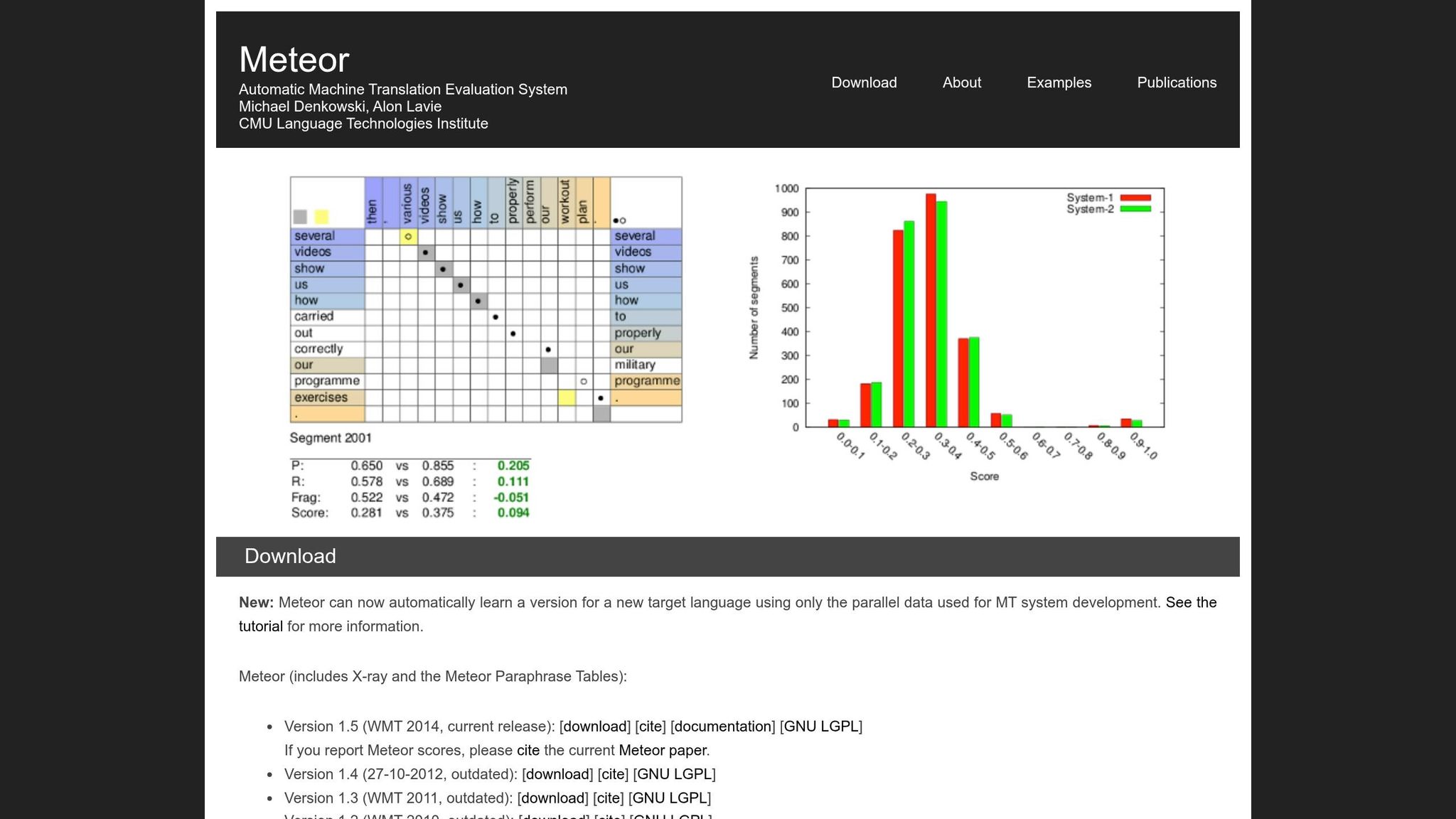
METEOR, abreviação de Metric for Evaluation of Translation with Explicit ORdering (Métrica para Avaliação de Tradução com Ordenação Explícita), foi introduzido em 2005 por pesquisadores Satanjeev Banerjee e Alon Lavie na Carnegie Mellon University. Foi desenvolvido para abordar algumas das limitações do BLEU, particularmente sua correspondência rígida palavra por palavra. O METEOR se concentra em preservar o significado e a ordem natural das palavras, o que o torna especialmente útil para avaliar traduções que precisam manter fluxo narrativo - como traduções de livros.
A métrica funciona alinhando palavras individuais na tradução candidata com as da tradução de referência. Quando há múltiplas maneiras de alinhar as palavras, o METEOR escolhe aquela com o menor número de "cruzamentos" (intersecções entre linhas de mapeamento). Esta abordagem ajuda a manter uma ordem de palavras mais natural no processo de avaliação [1].
Características Principais do METEOR
O METEOR se destaca por sua abordagem de correspondência em camadas, que vai além da correspondência exata de palavras. Usa quatro módulos sequenciais para avaliar traduções:
- Correspondência exata: Corresponde a formas de palavras idênticas.
- Stemming: Corresponde a palavras que compartilham a mesma raiz, como "running" e "runs".
- Sinonímia: Reconhece palavras com significados semelhantes usando WordNet.
- Correspondência de paráfrase: Corresponde a frases com conteúdo semântico semelhante.
Esta abordagem em camadas aborda a dificuldade do BLEU em levar em conta variações válidas de palavras e expressões alternativas [1][2][6].
O sistema de pontuação do METEOR combina dois elementos principais. Primeiro, ele calcula uma F-média ponderada de precisão e recall, com recall ponderado nove vezes mais pesadamente do que a precisão. Isso reflete como os humanos tendem a avaliar a qualidade da tradução, priorizando a cobertura do significado original em vez de correspondências exatas [1]. Segundo, aplica uma penalidade de fragmentação para desencorajar traduções em que palavras correspondidas estão espalhadas ou fora de ordem. Se as palavras correspondidas forem divididas em muitos "chunks", a pontuação pode ser penalizada em até 50%. Isso garante que traduções com palavras corretas, mas estrutura inadequada - frequentemente referidas como "word salad" - recebam pontuações mais baixas [1].
Como o METEOR Se Alinha com o Julgamento Humano
Estudos mostram que o METEOR se correlaciona melhor com o julgamento humano do que o BLEU, alcançando coeficientes de correlação entre 0,60 e 0,75, comparado ao intervalo do BLEU de 0,45 a 0,60 [6].
Este alinhamento mais forte deve-se em grande parte ao foco de nível de sentença do METEOR. Enquanto o BLEU é projetado para avaliar traduções no nível de corpus, o METEOR avalia sentenças ou segmentos individuais. Isso o torna particularmente eficaz para avaliar o fluxo e coerência necessários em traduções de livros [1]. Além disso, o METEOR pode processar até 500 segmentos por segundo por núcleo de CPU, tornando-o eficiente e confiável para uso prático [2]. Sua capacidade de corresponder de perto ao julgamento humano solidificou seu papel na melhoria das traduções de livros impulsionadas por IA.
METEOR vs. BLEU: Por que o METEOR Funciona Melhor para Tradução de Livros com IA

Comparação de Métricas de Tradução: METEOR vs BLEU
Principais Vantagens do METEOR para Tradução de Livros
Quando se trata de traduzir obras literárias, o METEOR se destaca como uma métrica de avaliação mais eficaz do que o BLEU. Seus métodos de alinhamento únicos e foco no significado o tornam especialmente adequado para as nuances da tradução de livros.
Uma das principais diferenças é como cada métrica lida com precisão semântica. O BLEU depende de correspondências exatas de palavras, o que pode penalizar injustamente traduções que usam sinônimos ou formas alternativas de palavras - mesmo quando o significado permanece intacto. O METEOR, por outro lado, incorpora stemming e correspondência de sinônimos. Por exemplo, reconhece que palavras como "good" e "well" ou "runs" e "running" compartilham o mesmo valor semântico. Esta flexibilidade é essencial para traduções literárias, onde vocabulário diverso e fraseado criativo são frequentemente necessários para preservar o estilo e intenção do autor.
Outra distinção importante é a ênfase do METEOR em recall em vez de precisão. O BLEU prioriza a precisão medindo quantas palavras na tradução gerada por IA correspondem àquelas no texto de referência. O METEOR, no entanto, equilibra precisão e recall, com recall ponderado nove vezes mais pesadamente [1]. Isso garante que a tradução capture o significado completo do texto original - um fator crítico para transmitir narrativas complexas com precisão.
O METEOR também se destaca na avaliação de nível de sentença. Enquanto o BLEU é adaptado para avaliar traduções no nível de corpus, o METEOR é projetado para se alinhar de perto com o julgamento humano em sentenças ou segmentos individuais. Alcança uma correlação máxima de cerca de 0,403 no nível de sentença [1]. Isso o torna particularmente eficaz para avaliar o fluxo e coerência de passagens específicas, o que é fundamental na tradução de livros.
Uma das características mais destacadas do METEOR é sua penalidade de fragmentação, que aborda a ordem das palavras e estrutura da sentença. Se as palavras correspondidas na tradução estão espalhadas em muitos chunks, a pontuação pode cair até 50% [1]. Este mecanismo garante que as traduções mantenham uma estrutura natural e coerente - algo que o BLEU frequentemente ignora. Ao focar nesses detalhes, o METEOR ajuda a preservar o significado nuançado do texto original e a legibilidade.
Tabela de Comparação: METEOR vs. BLEU
| Característica | BLEU | METEOR |
|---|---|---|
| Foco Principal | Precisão (sobreposição exata de palavras) | Recall (significado e cobertura de conteúdo) |
| Critérios de Correspondência | Correspondência exata de n-gramas | Exata, stemming, sinônimos e paráfrases |
| Precisão Semântica | Baixa (apenas correspondências exatas de palavras) | Alta (inclui sinônimos e stemming) |
| Correlação Humana | Mais forte no nível de corpus | Forte em níveis de sentença e corpus |
| Estrutura de Sentença | Indireta (via sobreposições de n-gramas) | Direta (via penalidade de fragmentação e alinhamento) |
| Flexibilidade | Rígida; penaliza fraseado criativo | Flexível; recompensa equivalência semântica |
| Tratamento de Recall | Indireto (penalidade de brevidade) | Direto (cálculo de recall ponderado 9x mais) |
Como o METEOR é Usado em Plataformas de Tradução de Livros com IA
Garantindo Qualidade com o METEOR
Plataformas de tradução impulsionadas por IA alavancam o METEOR para manter a precisão semântica e preservar as nuances delicadas de obras literárias. O processo começa com mapeamento de alinhamento, onde o sistema identifica conexões entre a tradução gerada por IA e um texto de referência. Isso envolve reconhecer correspondências exatas, raízes de palavras, sinônimos e até paráfrases [2]. Tal mapeamento detalhado garante que a tradução reflita o significado original, mesmo que a fraseologia seja diferente.
Para lidar com as complexidades de diferentes idiomas, o METEOR é configurado com ferramentas específicas de idioma, como stemmers e tabelas de paráfrase. Por exemplo, plataformas como BookTranslator.ai, que suporta mais de 99 idiomas, usam esses recursos para abordar as estruturas linguísticas únicas de idiomas diversos. Seja em idiomas românicos como espanhol e francês ou em idiomas mais intricados como árabe e tcheco, essas ferramentas são vitais para capturar variações morfológicas [2].
O que diferencia o METEOR é sua capacidade de ajustar parâmetros. As plataformas podem calibrar essas configurações para se alinhar com tarefas de avaliação específicas, como medir adequação ou manter um estilo consistente. Este recurso é particularmente valioso em traduções literárias, onde preservar a voz do autor e o ritmo da narrativa é essencial. Além disso, a penalidade de fragmentação do sistema garante que as sentenças fluam naturalmente, evitando a sensação desajeitada e desconectada de uma mera sequência de palavras corretas. Esta atenção à fluidez da sentença é crítica para manter os leitores absortos na história ao longo de centenas de páginas.
Além de melhorar a qualidade das traduções, o METEOR também desempenha um papel fundamental em tornar a literatura mais acessível a um público global.
Melhorando o Acesso Multilíngue à Literatura
Ao salvaguardar o significado e profundidade do texto original, o METEOR não apenas melhora a qualidade da tradução, mas também ajuda a trazer literatura para leitores em suas línguas nativas. Usando dados paralelos, o METEOR permite que as plataformas expandam suas ofertas de idiomas sem sacrificar a qualidade [2]. Esta capacidade de adaptação é especialmente importante para leitores em mercados de idiomas sub-representados.
A abordagem de avaliação focada no humano garante que as traduções pareçam naturais e envolventes. Por exemplo, plataformas como BookTranslator.ai oferecem traduções a partir de $5,99 por 100.000 palavras, tornando as traduções de alta qualidade acessíveis enquanto retêm o charme narrativo da história e sutilezas culturais. Ao priorizar recall em vez de precisão, o METEOR captura a riqueza do texto de origem, incluindo arcos de personagens intricados e camadas temáticas que são essenciais para narrativas cativantes.
Conclusão
METEOR está mudando o jogo na avaliação de tradução de livros com IA, priorizando precisão semântica e legibilidade natural. Diferentemente das métricas tradicionais, o METEOR leva em conta sinônimos, raízes de palavras e paráfrases, alcançando uma impressionante correlação de 0,964 com o julgamento humano no nível de corpus - significativamente mais alta do que o BLEU com 0,817 [1]. Isso garante que as traduções retenham o estilo do autor, consistência narrativa e elementos culturais sutis.
O que diferencia o METEOR é sua pontuação ponderada por recall combinada com uma penalidade de fragmentação, o que garante que as traduções não apenas capturem o significado completo do texto original, mas também leiam suavemente. Isso é especialmente crítico para conteúdo de longa forma, onde manter coerência e fluxo ao longo de uma narrativa extensa é essencial.
Para plataformas como BookTranslator.ai, que suportam mais de 99 idiomas, a capacidade do METEOR de reconhecer variações linguísticas permite traduções de alta qualidade a taxas competitivas - começando em apenas $5,99 por 100.000 palavras. Ao aproveitar dados paralelos para aprender novas línguas de destino [2], o METEOR abre a porta para leitores em regiões mal servidas acessarem literatura em suas línguas nativas.
"O METEOR funciona mais como sistemas modernos de reconhecimento de voz que entendem diferentes maneiras de dizer a mesma coisa. Ele avalia traduções com flexibilidade, espelhando o julgamento humano." - Iterate.ai [3]
Perguntas Frequentes
O METEOR é suficiente para avaliar a qualidade da tradução de um livro?
O METEOR é uma ferramenta útil para medir a qualidade da tradução, especialmente quando se trata de identificar nuances semânticas e detalhes linguísticos. No entanto, confiar apenas nele não é suficiente para avaliar completamente a qualidade da tradução de um livro. Combinar o METEOR com avaliações humanas oferece uma maneira mais equilibrada e completa de avaliar a qualidade da tradução.
Como o METEOR lida com idiomas e fraseado criativo?
O METEOR aborda os desafios de idiomas e fraseado criativo através de correspondência de sinônimos, stemming e avaliação linguística adaptável. Essas ferramentas permitem que ele compreenda expressões sutis e não-literais, garantindo que as traduções preservem tanto o significado pretendido quanto o estilo original.
O METEOR pode detectar problemas de consistência em um romance inteiro?
O METEOR é capaz de detectar problemas de consistência em um romance examinando semelhanças semânticas e detalhes linguísticos em todo o texto. Isso ajuda a garantir que a tradução preserve um significado, tom e estilo consistentes em todo o livro.