
Métricas de Precisão de Tradução: Explicadas
As métricas de precisão de tradução ajudam a avaliar o quão bem as traduções automáticas correspondem às referências criadas por humanos. Essas ferramentas são cruciais para avaliar a qualidade da tradução, especialmente ao lidar com projetos em larga escala ou conteúdo de alto risco. As métricas se dividem em três categorias:
- Métricas Baseadas em String: BLEU, METEOR e TER focam na sobreposição de palavras ou caracteres.
- Métricas Baseadas em Redes Neurais: COMET e BERTScore analisam similaridade semântica usando modelos de IA.
- Avaliações Humanas: Avaliações diretas como MQM focam em adequação e fluência.
Principais conclusões:
- BLEU: Rápido e simples, mas tem dificuldade com sinônimos e significado mais profundo.
- METEOR: Leva em conta sinônimos e nuances linguísticas; melhor para obras literárias.
- TER: Mede o esforço de edição, mas ignora a qualidade semântica.
- COMET e BERTScore: Modelos de IA avançados que se alinham bem com o julgamento humano, ótimos para textos nuançados.
Para traduções de livros, combinar ferramentas automatizadas com avaliações humanas garante precisão e preserva o estilo original. Plataformas como BookTranslator.ai usam essa abordagem híbrida para entregar resultados confiáveis em mais de 99 idiomas.
Métricas Comuns de Precisão de Tradução
BLEU Score
Introduzido em 2002, o BLEU (Bilingual Evaluation Understudy) continua sendo uma métrica preferida para avaliar a tradução automática [4]. Funciona comparando precisão de n-gramas, o que significa analisar como sequências de palavras na saída da máquina se alinham com traduções de referência. Os scores BLEU variam de 0 a 1, com números mais altos sinalizando melhor qualidade. Seu maior ponto forte? Velocidade e simplicidade - BLEU pode processar milhares de traduções rapidamente, tornando-o altamente prático. Essa eficiência até lhe rendeu o prêmio NAACL 2018 Test-of-Time.
Como Papineni et al. explicaram, "A ideia principal é usar uma média ponderada de correspondências de n-gramas de comprimento variável entre a tradução do sistema e um conjunto de traduções de referência humanas" [4].
No entanto, BLEU tem uma limitação notável: prioriza correspondências exatas de palavras. Isso significa que pode subestimar traduções que transmitem o mesmo significado, mas usam palavras diferentes. Para resolver isso, métricas como METEOR visam capturar nuances linguísticas.
METEOR Métrica
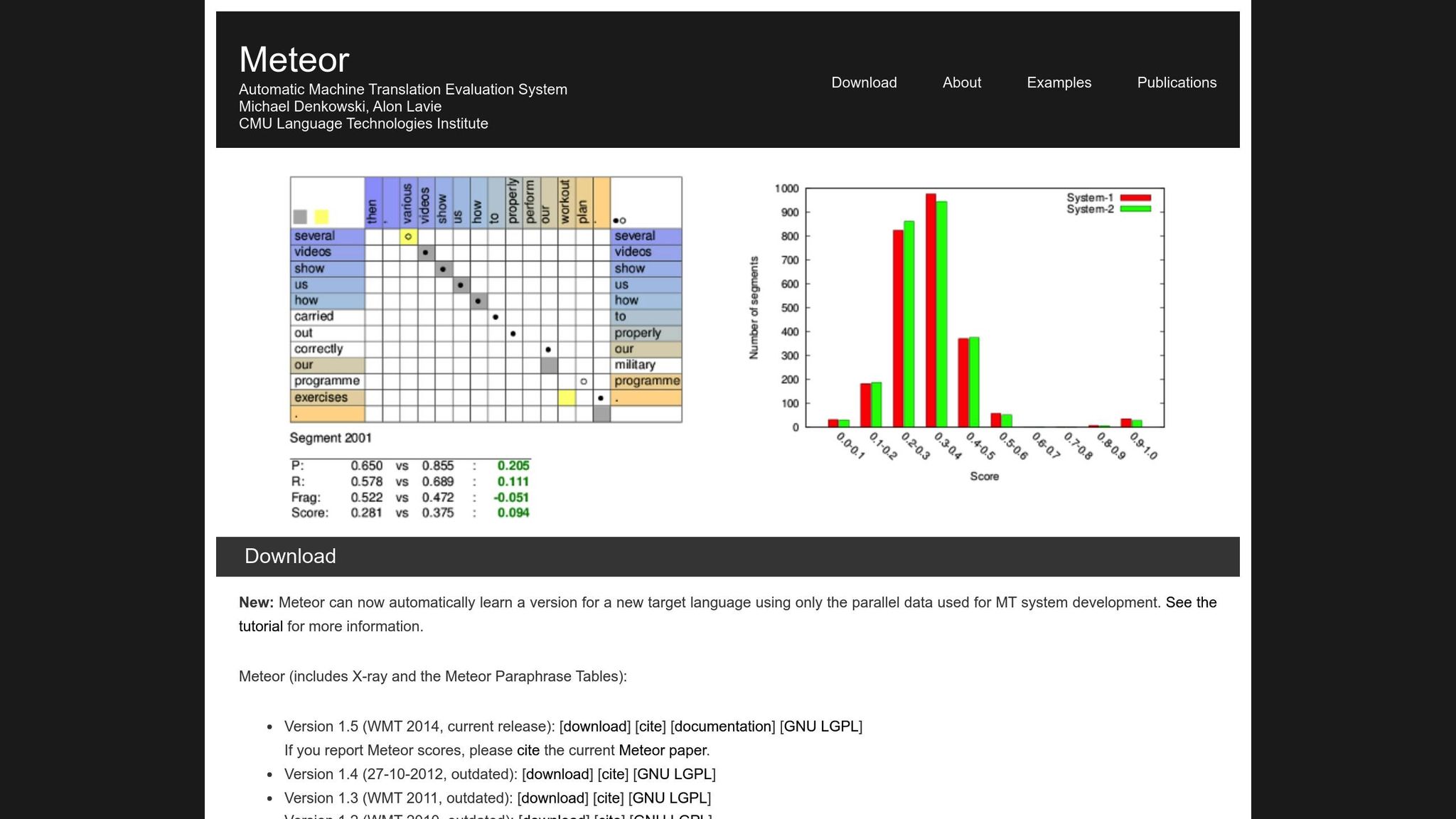
METEOR (Metric for Evaluation of Translation with Explicit ORdering) melhora o BLEU ao levar em conta precisão, recall, sinônimos, stemming e penalidades de ordem de palavras [1]. Ele lida com variações como "running" vs. "ran" ou "happy" vs. "joyful", tornando-o mais adequado para traduções em que o significado é mais importante. Por exemplo, durante o desafio NIST MetricsMaTr10, METEOR‑next‑rank alcançou uma correlação de Spearman's rho de 0,92 com julgamentos humanos no nível do sistema e 0,84 no nível do documento [1].
Dito isso, METEOR tem seus próprios desafios. Requer recursos adicionais, como bancos de dados de sinônimos e algoritmos de stemming, o que aumenta sua carga computacional. Ainda assim, frequentemente fornece uma avaliação mais nuançada e confiável, especialmente para capturar precisão semântica.
Taxa de Edição de Tradução (TER)
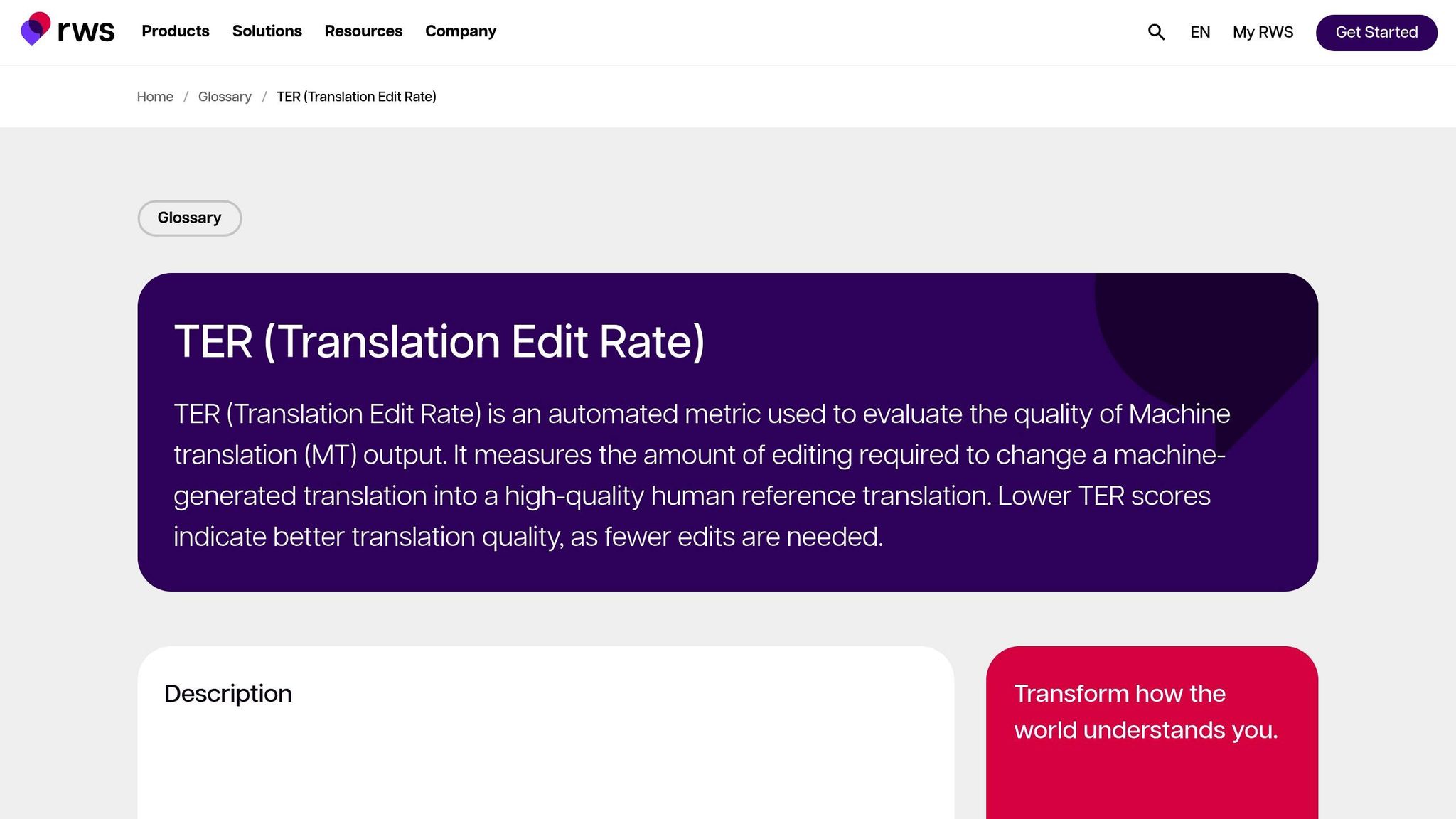
TER avalia a qualidade da tradução calculando o número de edições - inserções, exclusões, substituições e deslocamentos - necessárias para transformar a saída da máquina na referência. Isso a torna particularmente útil para avaliar o esforço de edição necessário para alinhar a saída com o resultado desejado. Nas avaliações MetricsMaTr10, TER-v0.7.25 demonstrou uma correlação em nível de sistema de 0,89 com avaliações humanas de adequação semântica, enquanto TERp mostrou uma correlação em nível de segmento de 0,68 [1].
Métricas Baseadas em Redes Neurais: BERTScore, COMET e GEMBA
As métricas baseadas em redes neurais levam a avaliação de tradução para o próximo nível, focando na análise semântica em vez de correspondências exatas de palavras. Aqui está um resumo rápido:
- BERTScore: Usa embeddings contextuais para medir a similaridade entre traduções.
- COMET: Integra texto de origem, hipótese e traduções de referência em uma estrutura neural treinada em anotações humanas. Alcançou algumas das correlações mais altas com julgamentos de qualidade humana [5].
- GEMBA: Aproveita modelos de linguagem grande para estimativa de qualidade zero-shot, oferecendo uma aproximação mais próxima da avaliação humana.
Embora essas métricas sejam poderosas, elas têm desvantagens. Ao contrário de BLEU e TER, que podem ser executados em CPUs padrão em milissegundos, as métricas baseadas em redes neurais como BERTScore e COMET frequentemente requerem aceleração de GPU para lidar com grandes conjuntos de dados de forma eficiente. GEMBA, em particular, pode envolver custos de API altos e possíveis vieses de modelos de linguagem grande, tornando-o menos acessível para alguns usuários.
Métricas Automáticas para Avaliar Sistemas de TM
Comparando Métricas de Tradução

Comparação de Métricas de Precisão de Tradução: BLEU, METEOR, TER, BERTScore, COMET e GEMBA
Tabela de Comparação de Métricas
Escolher a métrica de tradução certa geralmente depende do foco de sua avaliação e dos recursos disponíveis. Métricas tradicionais como BLEU são rápidas e requerem recursos mínimos, mas têm dificuldade em capturar significado semântico mais profundo. Por outro lado, as métricas neurais se destacam na compreensão de contexto e significado, mas exigem mais poder computacional.
Pesquisas recentes sugerem se afastar de métricas baseadas em sobreposição. Por exemplo, os achados do WMT22 recomendam abandonar métricas como BLEU em favor de abordagens neurais [6]. O estudo destaca que métricas de sobreposição como BLEU, spBLEU e chrF têm correlação fraca com avaliações de especialistas humanos.
Aqui está uma comparação rápida das principais métricas de tradução, cobrindo suas áreas de foco, métodos de pontuação, correlação com avaliação humana, limitações e adequação para traduções de livros:
| Métrica | Área de Foco | Intervalo de Pontuação | Correlação com Avaliação Humana | Limitações | Adequação para Traduções de Livros |
|---|---|---|---|---|---|
| BLEU | Precisão de n-gramas | 0 a 1 (ou 0-100) | Baixa a Moderada | Tem dificuldade com sinônimos [7][8] | Baixa; falta capacidade de capturar estilo literário |
| METEOR | Precisão, recall, sinônimos, ordem de palavras | 0 a 1 | Alta | Requer recursos específicos do idioma [7] | Moderada; útil para terminologia consistente |
| TER | Distância de edição (esforço de pós-edição) | 0 a 1 (menor é melhor) | Moderada | Ignora qualidade semântica [7] | Baixa; foca em mecânica, não em "voz" |
| BERTScore | Similaridade semântica via embeddings contextuais | 0 a 1 | Alta | Intensiva em recursos [7] | Alta; captura significado mais profundo e contexto |
| COMET | Similaridade semântica e fluência | 0 a 1 (0,5-0,8 típico) | Muito Alta | Requer modelos pré-treinados [7][8] | Alta; preserva estilo e significado nuançado |
| GEMBA | Avaliação holística baseada em LLM | Varia | Alta | Configuração complexa; APIs caras [7] | Alta; oferece uma revisão abrangente "semelhante à humana" |
Esta tabela ressalta como diferentes métricas se alinham com necessidades de tradução específicas. Para traduções técnicas, métricas como BLEU e TER fornecem benchmarks rápidos e básicos. No entanto, para traduções literárias - onde estilo, tom e significado nuançado são críticos - métricas neurais como BERTScore e COMET funcionam muito melhor. Essas ferramentas são particularmente adeptas em capturar a profundidade e o artísmo de textos literários, que as métricas tradicionais frequentemente ignoram [7].
Por exemplo, plataformas como BookTranslator.ai, que visam equilibrar eficiência e qualidade, se beneficiam significativamente de métricas neurais. Ferramentas como BERTScore e COMET garantem que tanto a precisão semântica quanto o estilo literário sejam preservados.
Para colocar as coisas em perspectiva, um score BLEU "bom" normalmente cai entre 30 e 40, com scores acima de 40 considerados fortes e qualquer coisa acima de 50 indicando tradução de alta qualidade [8]. Para COMET, os scores geralmente variam de 0,5 a 0,8, com valores mais próximos de 1,0 refletindo qualidade de tradução quase humana [8]. As métricas neurais não apenas funcionam consistentemente em diferentes tipos de texto, mas também se adaptam melhor a contextos variados em comparação com métricas sensíveis a domínio como BLEU [6].
sbb-itb-0c0385d
Métodos de Avaliação Humana
Métricas automatizadas podem oferecer velocidade e consistência, mas frequentemente perdem os detalhes sutis que definem a qualidade da tradução. É aí que a avaliação humana entra em cena como o padrão ouro[2]. Embora seja mais lenta e cara, a avaliação humana descobre as razões mais profundas por trás dos problemas de qualidade - coisas que métricas como BLEU ou COMET simplesmente não conseguem identificar[9].
Existem duas abordagens principais para avaliação humana. Uma é Julgamento Diretamente Expresso (DEJ), onde as traduções são avaliadas em escalas como fluência e adequação. A outra envolve métodos não-DEJ, que focam em identificar e categorizar erros específicos, frequentemente usando estruturas como MQM[12]. Enquanto métodos analíticos decompõem erros individuais e sua severidade, métodos holísticos analisam a qualidade geral. Juntas, essas abordagens formam a base de estruturas como MQM.
MQM (Métricas de Qualidade Multidimensional)

Quando as ferramentas automatizadas ficam aquém, MQM oferece uma alternativa mais detalhada e acionável. Ela divide erros de tradução em categorias como Precisão, Fluência, Terminologia, Convenções Locais e Design/Markup, em vez de resumir a qualidade com um único número[18, 17].
"Em contraste, as métricas automatizadas normalmente fornecem apenas um número sem indicação de como melhorar os resultados."
– Comitê MQM[10]
Os erros são classificados por severidade: Neutro (sinalizado mas aceitável, sem penalidade), Menor (ligeiramente perceptível, peso de penalidade de 1), Maior (afeta compreensão, peso de penalidade de 5) e Crítico (torna o texto inutilizável, peso de penalidade de 25)[11]. Para traduções críticas, como documentos legais, os limites de aprovação podem ser definidos tão altos quanto 99,5 em uma escala de score bruto[11].
O que torna MQM especialmente útil é sua capacidade de identificar áreas problemáticas específicas. Por exemplo, se uma tradução literária recebe uma pontuação baixa, MQM pode revelar se o problema está em fraseado desajeitado ou terminologia inconsistente. Esse nível de detalhe é particularmente valioso para plataformas como BookTranslator.ai, onde capturar tanto o significado quanto o estilo literário é essencial.
Pontuação de Adequação e Fluência
Construindo sobre estruturas organizadas como MQM, os avaliadores também focam em duas dimensões-chave da qualidade da tradução: adequação e fluência. Adequação mede o quão bem a tradução transmite o significado do texto de origem, enquanto fluência avalia o quão natural e legível é para falantes nativos. Esses aspectos geralmente são pontuados em escalas de cinco pontos[9].
Equilibrar essas duas dimensões pode ser complicado, especialmente em traduções literárias. Preservar a voz do autor original enquanto garante que o texto flua suavemente no idioma de destino requer atenção cuidadosa.
Para refinar esse processo, os avaliadores usam Avaliação Direta (DA), que pontua traduções em formatos monolíngues, bilíngues ou baseados em referência[9]. A Métrica de Qualidade Escalar (SQM) leva isso um passo adiante com uma escala de sete pontos, permitindo que os avaliadores avaliem segmentos individuais dentro do contexto de todo o documento. Para livros, esse foco contextual é crítico - a qualidade geralmente depende de quão bem um capítulo desenvolve personagens ou mantém continuidade da trama.
Usando Métricas para Tradução de Livros
Traduzir livros é um desafio único. Ao contrário de manuais de instruções ou materiais de marketing, os livros requerem um equilíbrio entre precisão semântica - garantindo que o significado está correto - e preservação estilística - mantendo a voz e o tom do autor. Avaliar traduções de livros exige uma abordagem personalizada, com métricas escolhidas para se adequar ao tipo específico de conteúdo sendo traduzido.
Traduções Técnicas vs. Literárias
Nem todas as traduções de livros têm os mesmos requisitos. Textos técnicos, como materiais acadêmicos ou instrucionais, priorizam precisão e consistência. Para esses, métricas como TER (Taxa de Edição de Tradução) são particularmente eficazes, pois medem a quantidade de edição necessária para aperfeiçoar a tradução.
Obras literárias, por outro lado, são uma história diferente. Romances, memórias e gêneros similares dependem muito do fluxo narrativo e ressonância emocional. Nessas situações, METEOR se destaca porque leva em conta sinônimos e diferenças semânticas sutis, alcançando correlações com avaliações humanas tão altas quanto 0,92 no nível do sistema [1]. Embora BLEU possa fornecer uma linha de base rápida, frequentemente perde as nuances mais profundas que definem traduções literárias de alta qualidade.
Combinando Avaliação Automática e Humana
Dadas as demandas diversas da tradução de livros, uma abordagem de avaliação híbrida funciona melhor. Métricas baseadas em redes neurais como COMET e BERTScore oferecem uma maneira rápida de avaliar a qualidade da tradução e se alinham bem com o julgamento humano [6]. No entanto, essas ferramentas automatizadas têm limitações - não conseguem capturar totalmente o valor prático e artístico de uma tradução.