
AI पुस्तक अनुवाद के लिए METEOR क्यों महत्वपूर्ण है
METEOR, जिसका पूरा नाम Metric for Evaluation of Translation with Explicit ORdering है, एक अनुवाद मूल्यांकन उपकरण है जो सटीक शब्द मिलान की तुलना में अर्थ और वाक्य प्रवाह को प्राथमिकता देता है। BLEU के विपरीत, जो कड़े शब्द-दर-शब्द संरेखण पर निर्भर करता है, METEOR स्टेमिंग, पर्यायवाची मिलान और पैराफ्रेजिंग जैसी तकनीकों का उपयोग करके अनुवाद की गुणवत्ता का बेहतर आकलन करता है। यह पुस्तकों का अनुवाद करने के लिए विशेष रूप से प्रभावी है, जहां लेखक की आवाज, टोन और कथात्मक प्रवाह को पकड़ना महत्वपूर्ण है।
मुख्य अंतर्दृष्टि:
- BLEU क्यों कमजोर है: BLEU का सटीक शब्द मिलान पर कड़ा ध्यान वैध विकल्पों को दंडित करता है, पर्यायवाचियों के साथ संघर्ष करता है, और कथात्मक सुसंगतता का मूल्यांकन करने में विफल रहता है, जिससे यह साहित्य के लिए अनुपयुक्त है।
- METEOR कैसे काम करता है: METEOR सटीक मिलान, शब्द तने, पर्यायवाची और पैराफ्रेज का उपयोग करके अनुवादों को संरेखित करता है। यह परिशुद्धता के बजाय रीकॉल (अर्थ कवरेज) को प्राथमिकता देता है और खराब शब्द क्रम के लिए दंड लागू करता है।
- प्रदर्शन: METEOR कॉर्पस स्तर पर मानव निर्णय के साथ 0.964 सहसंबंध प्राप्त करता है, BLEU के 0.817 को पार करता है।
- पुस्तक अनुवादों पर प्रभाव: अर्थ और प्रवाह पर ध्यान केंद्रित करके, METEOR यह सुनिश्चित करता है कि अनुवाद मूल पाठ की गहराई और पठनीयता को बनाए रखते हैं, जिससे यह AI-संचालित साहित्यिक अनुवादों के लिए आदर्श बन जाता है।
BookTranslator.ai जैसे प्लेटफार्मों के लिए, METEOR 99+ भाषाओं में उच्च-गुणवत्ता वाले अनुवाद सक्षम करता है, जो $5.99 प्रति 100,000 शब्द जितना कम है, जिससे साहित्य को एक वैश्विक दर्शकों तक पहुंचाया जा सकता है।
AI पुस्तक अनुवादों का मूल्यांकन करने की समस्याएं
दीर्घ-रूप अनुवादों के लिए BLEU क्यों विफल होता है
BLEU (Bilingual Evaluation Understudy), एक मेट्रिक जो 2002 में पेश किया गया था, कड़े n-ग्राम मिलान पर निर्भर करता है, जो अक्सर साहित्यिक अनुवाद की सूक्ष्मताओं को पकड़ने में विफल रहता है।
समस्या का मूल BLEU के दृष्टिकोण में निहित है: यह गुणवत्ता का मूल्यांकन 1- से 4-शब्द अनुक्रमों को बिल्कुल वैसे ही मिलाकर करता है जैसे वे एक मानव संदर्भ में दिखाई देते हैं। यह कठोर विधि साहित्य का अनुवाद करने के लिए आवश्यक रचनात्मक लचीलेपन के साथ संघर्ष करती है। जैसा कि NLLB टीम बताती है:
"BLEU वैध वैकल्पिक अनुवादों को दंडित करता है। यदि संदर्भ कहता है 'the car is red' और सिस्टम 'the automobile is red' का उत्पादन करता है, तो BLEU बेमेल को दंडित करता है भले ही अर्थ समान हो" [4]।
पर्यायवाचियों को पहचानने में यह असमर्थता पुस्तकों के लिए विशेष रूप से समस्याग्रस्त है, जहां शब्द चयन अक्सर महत्वपूर्ण वजन रखता है। उदाहरण के लिए, BLEU "big" और "large" को पूरी तरह अलग शब्दों के रूप में मानता है, भले ही उनका अर्थ समान हो। इसी तरह, यह "running", "runs" और "ran" जैसी भिन्नताओं को ध्यान में नहीं रखता है, अक्सर उन अनुवादों को दंडित करता है जो सटीक और रचनात्मक दोनों हों।
एक अन्य मुख्य सीमा BLEU का कॉर्पस-स्तरीय डिज़ाइन है। इसे मूल रूप से बड़े डेटासेट को संभालने के लिए विकसित किया गया था, साहित्य के लिए महत्वपूर्ण वाक्य-स्तरीय सटीकता के लिए नहीं। BLEU में वाक्य प्रवाह या कथात्मक सुसंगतता का मूल्यांकन करने की क्षमता का भी अभाव है। जैसा कि NLLB नोट करता है:
"BLEU सीधे तरलता या अर्थ संरक्षण के लिए खाता नहीं है - यह विशुद्ध रूप से एक n-ग्राम ओवरलैप माप है" [4]।
इसका मतलब है कि एक अनुवाद तकनीकी रूप से सभी सही शब्दों को शामिल कर सकता है लेकिन उन्हें एक अस्पष्ट, अजीब क्रम में व्यवस्थित कर सकता है - और फिर भी अच्छा स्कोर प्राप्त कर सकता है। ये कमियां संदर्भ, सुसंगतता और समग्र कथात्मक अनुभव को प्राथमिकता देने वाली मूल्यांकन विधियों की आवश्यकता को उजागर करती हैं।
पुस्तकों में संदर्भ और अर्थ क्यों महत्वपूर्ण हैं
पुस्तकें केवल वाक्यों का संग्रह नहीं हैं - वे जटिल आख्यान हैं जहां हर शब्द, वाक्य संरचना और शैलीगत पसंद पाठक के अनुभव को आकार देने में एक भूमिका निभाती है। BLEU का सटीक शब्द मिलान पर संकीर्ण ध्यान इस बड़ी तस्वीर को याद करता है, विशेष रूप से कथात्मक प्रवाह और सुसंगतता को बनाए रखने के मामले में।
शब्दार्थ समझ का अंतराल विशेष रूप से स्पष्ट है। Michael Brenndoerfer बताते हैं:
"दो शब्दार्थ रूप से समकक्ष अनुवाद अपनी विशिष्ट शब्द पसंद के आधार पर बहुत अलग BLEU स्कोर प्राप्त कर सकते हैं" [5]।
यह AI सिस्टम के लिए शब्दार्थ सटीकता या प्राकृतिक तरलता के लिए प्रयास करने के बजाय सटीक शब्द मिलान का पीछा करने के लिए एक समस्याग्रस्त प्रोत्साहन बनाता है।
साहित्यिक अनुवाद परिशुद्धता और रीकॉल के बीच संतुलन की मांग करता है - न केवल त्रुटियों से बचना बल्कि मूल पाठ की गहराई, टोन और भावनात्मक गूंज को संरक्षित करना। BLEU भारी रूप से परिशुद्धता पर जोर देता है, लेकिन पुस्तकों को ऐसी मेट्रिक्स की आवश्यकता होती है जो मापती हैं कि क्या अनुवाद लेखक के इरादे और कथात्मक प्रवाह को पकड़ता है। METEOR जैसे उपकरण, जो रीकॉल को परिशुद्धता की तुलना में नौ गुना अधिक वजन देते हुए अर्थ और प्रवाह को प्राथमिकता देते हैं, साहित्यिक अनुवादों का मूल्यांकन करने के लिए एक अधिक उपयुक्त दृष्टिकोण प्रदान करते हैं [1]।
sbb-itb-0c0385d
METEOR : मशीन अनुवाद के लिए एक मेट्रिक
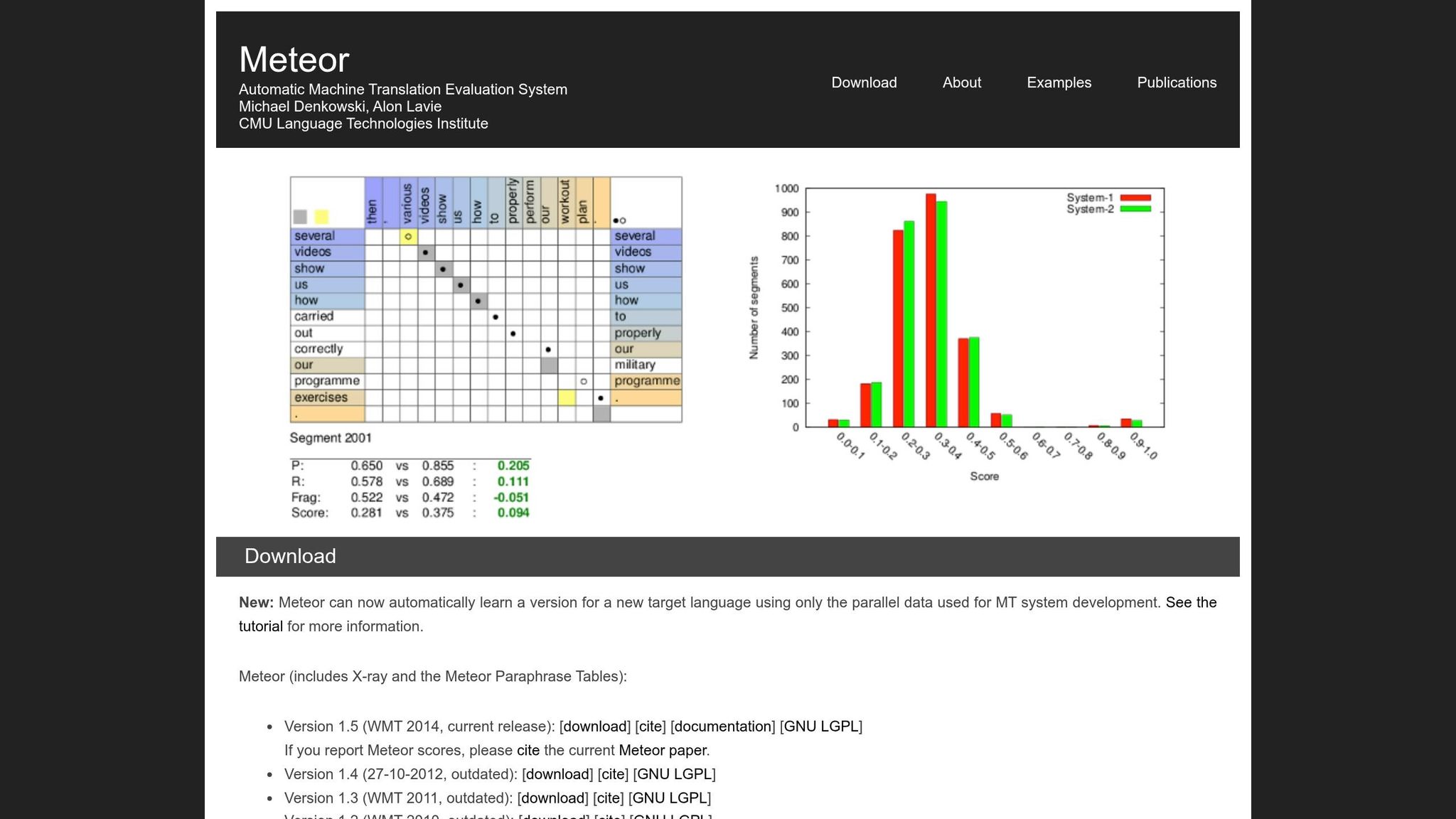
METEOR क्या है और यह कैसे काम करता है?
METEOR, जिसका पूरा नाम Metric for Evaluation of Translation with Explicit ORdering है, को 2005 में Carnegie Mellon University के शोधकर्ताओं Satanjeev Banerjee और Alon Lavie द्वारा पेश किया गया था। इसे BLEU की कुछ सीमाओं को संबोधित करने के लिए विकसित किया गया था, विशेष रूप से इसके कठोर शब्द-दर-शब्द मिलान। METEOR अर्थ और प्राकृतिक शब्द क्रम को संरक्षित करने पर ध्यान केंद्रित करता है, जो उन अनुवादों का मूल्यांकन करने के लिए विशेष रूप से उपयोगी है जिन्हें कथात्मक प्रवाह को बनाए रखने की आवश्यकता है - जैसे पुस्तक अनुवाद।
मेट्रिक उम्मीदवार अनुवाद में व्यक्तिगत शब्दों को संदर्भ अनुवाद में उन शब्दों के साथ संरेखित करके काम करता है। जब शब्दों को संरेखित करने के कई तरीके होते हैं, तो METEOR वह चुनता है जिसमें "crosses" की सबसे कम संख्या होती है (मानचित्रण लाइनों के बीच चौराहे)। यह दृष्टिकोण मूल्यांकन प्रक्रिया में अधिक प्राकृतिक शब्द क्रम बनाए रखने में मदद करता है [1]।
METEOR की मुख्य विशेषताएं
METEOR अपनी स्तरीय मिलान दृष्टिकोण के कारण अलग है, जो सटीक शब्द मिलान से परे जाता है। यह अनुवादों का मूल्यांकन करने के लिए चार अनुक्रमिक मॉड्यूल का उपयोग करता है:
- सटीक मिलान: समान शब्द रूपों से मेल खाता है।
- स्टेमिंग: उन शब्दों से मेल खाता है जो समान मूल साझा करते हैं, जैसे "running" और "runs"।
- पर्यायवाची: WordNet का उपयोग करके समान अर्थ वाले शब्दों को पहचानता है।
- पैराफ्रेज मिलान: समान शब्दार्थ सामग्री वाले वाक्यांशों से मेल खाता है।
यह स्तरीय दृष्टिकोण BLEU के वैध शब्द भिन्नताओं और वैकल्पिक अभिव्यक्तियों को खाते में लेने के संघर्ष को संबोधित करता है [1][2][6]।
METEOR की स्कोरिंग प्रणाली दो मुख्य तत्वों को जोड़ती है। पहला, यह परिशुद्धता और रीकॉल का एक भारित F-माध्य की गणना करता है, रीकॉल को परिशुद्धता की तुलना में नौ गुना अधिक भारी किया जाता है। यह प्रतिबिंबित करता है कि मनुष्य अनुवाद की गुणवत्ता का मूल्यांकन कैसे करते हैं, सटीक मिलान पर मूल अर्थ के कवरेज को प्राथमिकता देते हैं [1]। दूसरा, यह उन अनुवादों को हतोत्साहित करने के लिए एक विखंडन दंड लागू करता है जहां मेल खाने वाले शब्द बिखरे हुए हैं या क्रम से बाहर हैं। यदि मेल खाने वाले शब्दों को बहुत से "chunks" में तोड़ा जाता है, तो स्कोर 50% तक दंडित किया जा सकता है। यह सुनिश्चित करता है कि सही शब्दों वाले लेकिन खराब संरचना वाले अनुवाद - अक्सर "word salad" के रूप में संदर्भित - को कम स्कोर मिलते हैं [1]।
METEOR मानव निर्णय के साथ कैसे संरेखित होता है
अध्ययनों से पता चलता है कि METEOR BLEU की तुलना में मानव निर्णय के साथ बेहतर संबंध रखता है, 0.60 और 0.75 के बीच सहसंबंध गुणांक प्राप्त करता है, BLEU की 0.45 से 0.60 की तुलना में [6]।
यह मजबूत संरेखण बड़े हिस्से में METEOR के वाक्य-स्तरीय ध्यान के कारण है। जबकि BLEU कॉर्पस स्तर पर अनुवादों का आकलन करने के लिए डिज़ाइन किया गया है, METEOR व्यक्तिगत वाक्यों या खंडों का मूल्यांकन करता है। यह पुस्तक अनुवादों में आवश्यक प्रवाह और सुसंगतता का आकलन करने के लिए विशेष रूप से प्रभावी है [1]। इसके अलावा, METEOR प्रति CPU कोर प्रति सेकंड 500 खंडों तक संसाधित कर सकता है, जिससे यह व्यावहारिक उपयोग के लिए दक्ष और विश्वसनीय दोनों है [2]। मानव निर्णय के साथ निकटता से मेल खाने की इसकी क्षमता ने AI-संचालित पुस्तक अनुवादों में सुधार में इसकी भूमिका को मजबूत किया है।
METEOR बनाम BLEU: AI पुस्तक अनुवाद के लिए METEOR बेहतर क्यों काम करता है

METEOR बनाम BLEU अनुवाद मेट्रिक्स तुलना
पुस्तक अनुवाद के लिए METEOR के मुख्य लाभ
साहित्यिक कार्यों का अनुवाद करने के मामले में, METEOR BLEU की तुलना में एक अधिक प्रभावी मूल्यांकन मेट्रिक के रूप में सामने आता है। इसके अद्वितीय संरेखण विधियां और अर्थ पर ध्यान पुस्तक अनुवाद की सूक्ष्मताओं के लिए विशेष रूप से उपयुक्त हैं।
मुख्य अंतरों में से एक यह है कि प्रत्येक मेट्रिक शब्दार्थ सटीकता को कैसे संभालता है। BLEU सटीक शब्द मिलान पर निर्भर करता है, जो पर्यायवाचियों या वैकल्पिक शब्द रूपों का उपयोग करने वाले अनुवादों को अनुचित रूप से दंडित कर सकता है - भले ही अर्थ बना रहे। दूसरी ओर, METEOR *स्टेमिंग* और *पर्यायवाची मिलान* को शामिल करता है। उदाहरण के लिए, यह पहचानता है कि "good" और "well" या "runs" और "running" जैसे शब्द समान शब्दार्थ मूल्य साझा करते हैं। यह लचीलापन साहित्यिक अनुवादों के लिए आवश्यक है, जहां विविध शब्दावली और रचनात्मक वाक्यांश अक्सर लेखक की शैली और इरादे को संरक्षित करने के लिए आवश्यक होते हैं।
एक अन्य महत्वपूर्ण अंतर METEOR का परिशुद्धता पर रीकॉल पर जोर है। BLEU परिशुद्धता को प्राथमिकता देता है कि AI-उत्पादित अनुवाद में कितने शब्द संदर्भ पाठ में उन शब्दों से मेल खाते हैं। METEOR, हालांकि, परिशुद्धता और रीकॉल को संतुलित करता है, रीकॉल को नौ गुना अधिक भारी किया जाता है [1]। यह सुनिश्चित करता है कि अनुवाद मूल पाठ के पूर्ण अर्थ को पकड़ता है - जटिल आख्यानों को सटीक रूप से व्यक्त करने के लिए एक महत्वपूर्ण कारक।
METEOR वाक्य-स्तरीय मूल्यांकन में भी उत्कृष्ट है। जबकि BLEU कॉर्पस स्तर पर अनुवादों का मूल्यांकन करने के लिए तैयार है, METEOR व्यक्तिगत वाक्यों या खंडों पर मानव निर्णय के साथ निकटता से संरेखित करने के लिए डिज़ाइन किया गया है। यह वाक्य स्तर पर लगभग 0.403 का अधिकतम सहसंबंध प्राप्त करता है [1]। यह विशिष्ट मार्गों के प्रवाह और सुसंगतता का आकलन करने के लिए विश