
Waarom METEOR belangrijk is voor AI-boekvertalingen
METEOR, afgekort voor Metric for Evaluation of Translation with Explicit ORdering, is een evaluatietool voor vertalingen die betekenis en zinsvloei prioriteert boven exacte woordovereenkomsten. In tegenstelling tot BLEU, dat afhankelijk is van strikte woord-voor-woord-afstemming, gebruikt METEOR technieken zoals stamming, synoniemenmatching en parafrasering om de kwaliteit van vertalingen beter te beoordelen. Dit maakt het vooral effectief voor het vertalen van boeken, waar het vastleggen van de stem, toon en verhaallijn van de auteur essentieel is.
Belangrijkste inzichten:
- Waarom BLEU tekortschiet: BLEU's strikte focus op exacte woordovereenkomsten bestraft geldige alternatieven, worstelt met synoniemen en kan geen narratieve samenhang evalueren, waardoor het ongeschikt is voor literatuur.
- Hoe METEOR werkt: METEOR stemt vertalingen af met behulp van exacte overeenkomsten, woordstammen, synoniemen en parafrasen. Het prioriteert recall (betekenisdekking) boven precisie en past straffen toe voor slechte woordvolgorde.
- Prestatie: METEOR bereikt een correlatie van 0,964 met menselijk oordeel op corpusniveau, wat BLEU's 0,817 overtreft.
- Impact op boekvertalingen: Door zich op betekenis en vloeibaarheid te concentreren, zorgt METEOR ervoor dat vertalingen de diepte en leesbaarheid van de originele tekst behouden, waardoor het ideaal is voor AI-gestuurde literaire vertalingen.
Voor platforms zoals BookTranslator.ai maakt METEOR vertalingen van hoge kwaliteit mogelijk in meer dan 99 talen voor slechts $5,99 per 100.000 woorden, waardoor literatuur toegankelijk wordt gemaakt voor een wereldwijd publiek.
Problemen met het evalueren van AI-boekvertalingen
Waarom BLEU faalt voor langvormige vertalingen
BLEU (Bilingual Evaluation Understudy), een metriek geïntroduceerd in 2002, vertrouwt op strikte n-gram-matching, die vaak de subtiliteiten van literaire vertaling niet kan vastleggen.
De kern van het probleem ligt in BLEU's benadering: het evalueert kwaliteit door 1- tot 4-woord-sequenties exact af te stemmen zoals ze voorkomen in een menselijke referentie. Deze rigide methode worstelt met de creatieve flexibiliteit die nodig is voor het vertalen van literatuur. Zoals het NLLB-team uitlegt:
"BLEU bestraft geldige alternatieve vertalingen. Als de referentie 'the car is red' zegt en het systeem 'the automobile is red' produceert, bestraft BLEU de mismatch hoewel de betekenis identiek is" [4].
Dit onvermogen om synoniemen te herkennen is vooral problematisch voor boeken, waar woordkeuze vaak significant gewicht draagt. BLEU behandelt bijvoorbeeld "big" en "large" als volledig verschillende woorden, hoewel ze hetzelfde betekenen. Ook houdt het geen rekening met variaties zoals "running", "runs" en "ran", en bestraft het vertalingen die zowel nauwkeurig als creatief zijn.
Een ander kernprobleem is BLEU's corpusniveauontwerp. Het werd oorspronkelijk ontwikkeld om grote datasets af te handelen, niet de zinsniveauprecisie die cruciaal is voor literatuur. BLEU mist ook het vermogen om zinsvloei of narratieve samenhang te evalueren. Zoals NLLB opmerkt:
"BLEU houdt geen rechtstreeks rekening met vloeiendheid of betekenisbehoud - het is zuiver een n-gram-overlapsmeting" [4].
Dit betekent dat een vertaling technisch gezien alle juiste woorden kan bevatten, maar ze in een verwarrende, onhandige volgorde kan rangschikken - en toch goed kan scoren. Deze tekortkomingen benadrukken de behoefte aan evaluatiemethoden die context, samenhang en de algehele narratieve ervaring prioriteren.
Waarom context en betekenis belangrijk zijn in boeken
Boeken zijn meer dan alleen verzamelingen zinnen - het zijn ingewikkelde verhalen waarin elk woord, zinsstructuur en stilistische keuze een rol speelt in het vormgeven van de lezersservaring. BLEU's enge focus op exacte woordovereenkomsten mist dit grotere plaatje, vooral als het gaat om het behoud van verhaallijn en samenhang.
De semantische begripsgat is bijzonder opvallend. Michael Brenndoerfer wijst erop:
"Twee semantisch equivalente vertalingen kunnen zeer verschillende BLEU-scores ontvangen afhankelijk van hun specifieke woordkeuzes" [5].
Dit creëert een problematische prikkel voor AI-systemen om exacte woordovereenkomsten na te streven in plaats van naar semantische nauwkeurigheid of natuurlijke vloeiendheid.
Literaire vertaling vereist een evenwicht tussen precisie en recall - niet alleen fouten vermijden, maar ook de diepte, toon en emotionele resonantie van de originele tekst behouden. BLEU benadrukt precisie sterk, maar boeken vereisen maatstaven die meten of de vertaling de intentie van de auteur en verhaallijn vastlegt. Tools zoals METEOR, die betekenis en vloeibaarheid prioriteren door recall negen keer hoger te wegen dan precisie, bieden een meer passende aanpak voor het evalueren van literaire vertalingen [1].
sbb-itb-0c0385d
METEOR : een metriek voor machinevertaling
Wat is METEOR en hoe werkt het?
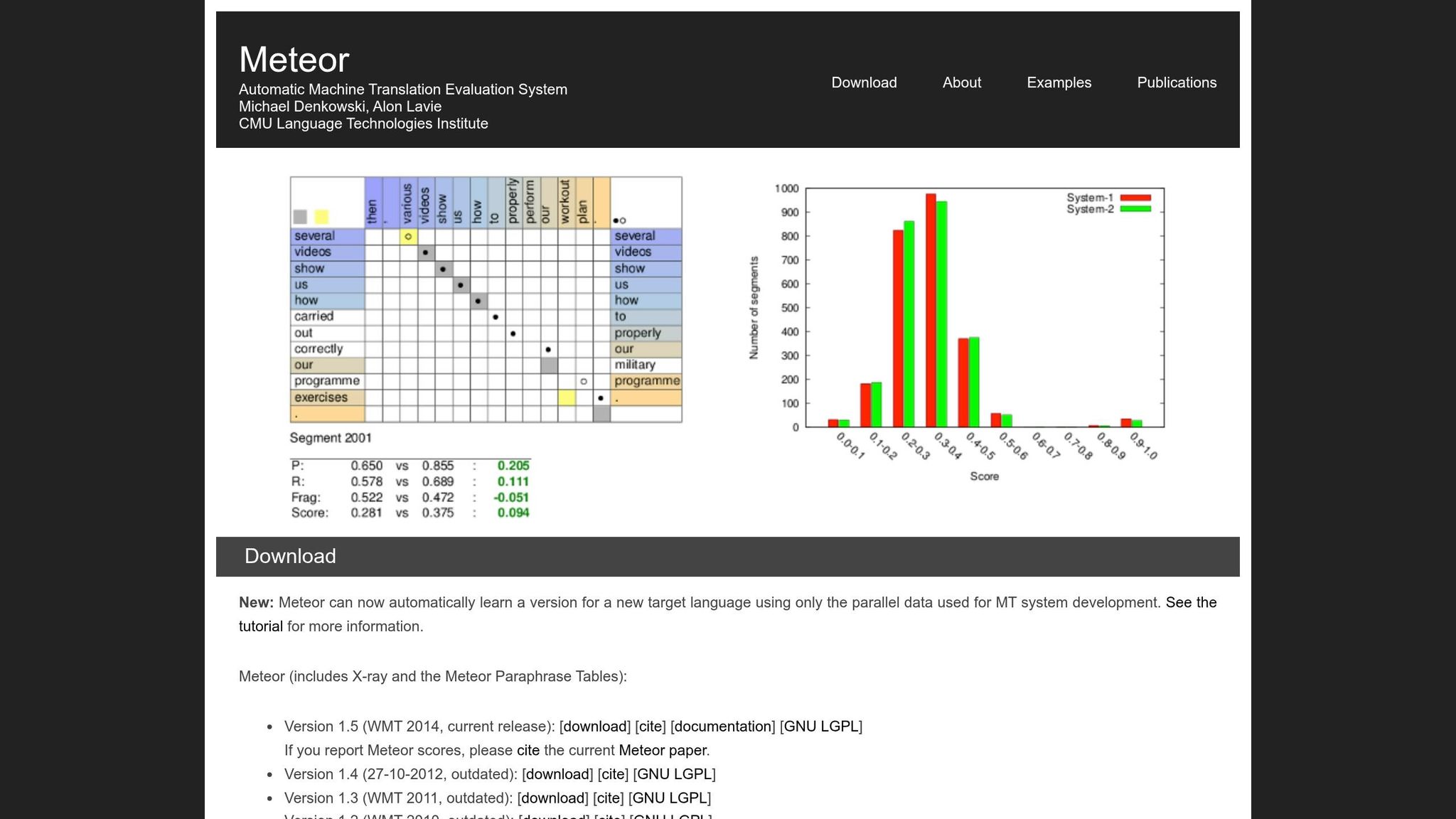
METEOR, afgekort voor Metric for Evaluation of Translation with Explicit ORdering, werd in 2005 geïntroduceerd door onderzoekers Satanjeev Banerjee en Alon Lavie van Carnegie Mellon University. Het werd ontwikkeld om enkele beperkingen van BLEU aan te pakken, met name de rigide woord-voor-woord-matching. METEOR concentreert zich op het behouden van betekenis en natuurlijke woordvolgorde, wat het vooral nuttig maakt voor het evalueren van vertalingen die verhaallijn moeten behouden - zoals boekvertalingen.
De metriek werkt door afzonderlijke woorden in de kandidaatvertaling af te stemmen met die in de referentievertaling. Wanneer er meerdere manieren zijn om de woorden af te stemmen, kiest METEOR degene met het minste aantal "kruisingen" (snijpunten tussen toewijzingslijnen). Deze benadering helpt een meer natuurlijke woordvolgorde in het evaluatieproces te behouden [1].
Kernfuncties van METEOR
METEOR valt op door zijn gelaagde matchingbenadering, die verder gaat dan exacte woordovereenkomsten. Het gebruikt vier opeenvolgende modules om vertalingen te evalueren:
- Exacte matching: Stemt identieke woordvormen af.
- Stamming: Stemt woorden af die dezelfde wortel delen, zoals "running" en "runs."
- Synoniemen: Herkent woorden met vergelijkbare betekenissen met behulp van WordNet.
- Parafrasematching: Stemt zinsdelen met vergelijkbare semantische inhoud af.
Deze gelaagde benadering lost BLEU's moeite op om rekening te houden met geldige woordvariaties en alternatieve uitdrukkingen [1][2][6].
METEOR's scoresysteem combineert twee belangrijke elementen. Ten eerste berekent het een gewogen F-gemiddelde van precisie en recall, waarbij recall negen keer zwaarder wordt gewogen dan precisie. Dit weerspiegelt hoe mensen de kwaliteit van vertaling evalueren, waarbij dekking van de originele betekenis wordt geprioriteerd boven exacte overeenkomsten [1]. Ten tweede past het een fragmentatiepenalty toe om vertalingen te ontmoedigen waarbij gematcte woorden verspreid of buiten volgorde zijn. Als gematcte woorden in te veel "chunks" zijn verdeeld, kan de score met tot 50% worden bestraft. Dit zorgt ervoor dat vertalingen met juiste woorden maar slechte structuur - vaak aangeduid als "woordsalade" - lagere scores ontvangen [1].
Hoe METEOR aansluit bij menselijk oordeel
Studies tonen aan dat METEOR beter correleert met menselijk oordeel dan BLEU, met correlatiecoëfficiënten tussen 0,60 en 0,75, vergeleken met BLEU's bereik van 0,45 tot 0,60 [6].
Deze sterkere afstemming is grotendeels te wijten aan METEOR's zinsniveaufocus. Terwijl BLEU is ontworpen om vertalingen op corpusniveau te beoordelen, evalueert METEOR afzonderlijke zinnen of segmenten. Dit maakt het vooral effectief voor het beoordelen van de vloeibaarheid en samenhang die nodig is in boekvertalingen [1]. Bovendien kan METEOR tot 500 segmenten per seconde per CPU-kern verwerken, waardoor het zowel efficiënt als betrouwbaar is voor praktisch gebruik [2]. Het vermogen om menselijk oordeel nauw te benaderen heeft zijn rol in het verbeteren van AI-gestuurde boekvertalingen versterkt.
METEOR versus BLEU: Waarom METEOR beter werkt voor AI-boekvertalingen

METEOR versus BLEU-vergelijking van vertalingsmaatstaven
Belangrijkste voordelen van METEOR voor boekvertaling
Als het gaat om het vertalen van literaire werken, onderscheidt METEOR zich als een effectievere evaluatiemetriek dan BLEU. De unieke afstemingsmethoden en focus op betekenis maken het vooral geschikt voor de nuances van boekvertaling.
Een van de belangrijkste verschillen is hoe elke metriek semantische nauwkeurigheid afhandelt. BLEU vertrouwt op exacte woordovereenkomsten, die vertalingen die synoniemen of alternatieve woordvormen gebruiken oneerlijk kunnen bestraffen - zelfs wanneer de betekenis intact blijft. METEOR daarentegen incorporeert stamming en synoniemenmatching. Het herkent bijvoorbeeld dat woorden zoals "good" en "well" of "runs" en "running" dezelfde semantische waarde delen. Deze flexibiliteit is essentieel voor literaire vertalingen, waar diverse woordenschat en creatieve formulering vaak nodig zijn om de stijl en intentie van de auteur te behouden.
Een ander belangrijk verschil is METEOR's nadruk op recall boven precisie. BLEU prioriteert precisie door te meten hoeveel woorden in de door AI gegenereerde vertaling overeenkomen met die in de referentietekst. METEOR daarentegen balanceert precisie en recall, met recall negen keer zwaarder gewogen [1]. Dit zorgt ervoor dat de vertaling de volledige betekenis van de originele tekst vastlegt - een kritieke factor voor het nauwkeurig overbrengen van complexe verhalen.
METEOR blinkt ook uit in zinsniveauevaluatie. Terwijl BLEU is afgestemd op het evalueren van vertalingen op corpusniveau, is METEOR ontworpen om nauw aan te sluiten bij menselijk oordeel over afzonderlijke zinnen of segmenten. Het bereikt een maximale correlatie van ongeveer 0,403 op zinsniveau [1]. Dit maakt het vooral effectief voor het beoordelen van de vloeibaarheid en samenhang van specifieke passages, wat essentieel is in boekvertaling.
Een van METEOR's opvallende kenmerken is zijn fragmentatiepenalty, die woordvolgorde en zinsstructuur aanpakt. Als gematcte woorden in de vertaling in te veel chunks zijn verspreid, kan de score tot 50% dalen [1]. Dit mechanisme zorgt ervoor dat vertalingen een natuurlijke en samenhangende structuur behouden - iets wat BLEU vaak over het hoofd ziet. Door op deze details te concentreren, helpt METEOR de genuanceerde betekenis en leesbaarheid van de originele tekst te behouden.
Vergelijkingstabel: METEOR versus BLEU
| Functie | BLEU | METEOR |
|---|---|---|
| Primaire focus | Precisie (exacte woordoverlap) | Recall (betekenis- en inhoudsdekking) |
| Matchingcriteria | Exacte n-gram-matching | Exact, stamming, synoniemen en parafrasen |
| Semantische nauwkeurigheid | Laag (alleen exacte woordovereenkomsten) | Hoog (inclusief synoniemen en stamming) |
| Menselijke correlatie | Sterker op corpusniveau | Sterk op zowel zins- als corpusniveau |
| Zinsstructuur | Indirect (via n-gram-overlaps) | Direct (via fragmentatiepenalty en afstemming) |
| Flexibiliteit | Rigide; bestraft creatieve formulering | Flexibel; beloont semantische equivalentie |
| Recall-afhandeling | Indirect (kortheidspenalty) | Direct (recall-berekening 9x zwaarder gewogen) |
Hoe METEOR wordt gebruikt in AI-boekvertalingsplatforms
Kwaliteit waarborgen met METEOR
AI-gestuurde vertalingsplatforms benutten METEOR om semantische nauwkeurigheid te handhaven en de delicate nuances van literaire werken te behouden. Het proces begint met afstemming, waarbij het systeem verbindingen tussen de door AI gegenereerde vertaling en een referentietekst identificeert. Dit omvat het herkennen van exacte overeenkomsten, woordstammen, synoniemen en zelfs parafrasen [2]. Dergelijke gedetailleerde mapping zorgt ervoor dat de vertaling de originele betekenis weerspiegelt, zelfs als de formulering verschilt.
Om de complexiteiten van verschillende talen af te handelen, is METEOR geconfigureerd met taalspecifieke tools zoals stemmers en parafrasentabellen. Platforms zoals BookTranslator.ai, die meer dan 99 talen ondersteunen, gebruiken deze bronnen om de unieke linguïstische structuren van diverse talen aan te pakken. Of het nu gaat om Romaanse talen zoals Spaans en Frans of ingewikkelder talen zoals Arabisch en Tsjechisch, deze tools zijn essentieel voor het vastleggen van morfologische variaties [2].
Wat METEOR onderscheidt, is het vermogen om parameters af te stemmen. Platforms kunnen deze instellingen kalibreren om aan te sluiten bij specifieke evaluatietaken, zoals het meten van geschiktheid of het behoud van een consistente stijl. Dit kenmerk is vooral waardevol in literaire vertalingen, waar het behoud van de stem van de auteur en het ritme van het verhaal essentieel is. Bovendien zorgt de fragmentatiepenalty van het systeem ervoor dat zinnen natuurlijk vloeien, waardoor de onhandige, losgeslagen uitstraling van slechts een reeks juiste woorden wordt vermeden. Deze aandacht voor zinsglad is cruciaal om lezers over honderden pagina's in het verhaal betrokken te houden.
Naast het verbeteren van de kwaliteit van vertalingen, speelt METEOR ook een cruciale rol in het toegankelijker maken van literatuur voor een wereldwijd publiek.
Meertalige toegang tot literatuur verbeteren
Door de betekenis en diepte van de originele tekst te beschermen, verbetert METEOR niet alleen de vertaalkwaliteit, maar helpt het ook literatuur naar lezers in hun moedertaal te brengen. Met behulp van parallelle gegevens stelt METEOR platforms in staat hun taalaanbod uit te breiden zonder kwaliteit in te leveren [2]. Dit aanpassingsvermogen is vooral belangrijk voor lezers in ondervertegenwoordigde taalmarkten.
De mensgerichte evaluatiebenadering zorgt ervoor dat vertalingen natuurlijk en boeiend voelen. Platforms zoals BookTranslator.ai bieden bijvoorbeeld vertalingen vanaf $5,99 per 100.000 woorden, wat vertalingen van hoge kwaliteit betaalbaar maakt terwijl de narratieve charme en culturele nuances van het verhaal behouden blijven. Door recall boven precisie te prioriteren, vangt METEOR de rijkdom van de brontekst, inclusief ingewikkelde karakterbogen en thematische lagen die essentieel zijn voor boeiend verhaalvertellen.
Conclusie
METEOR verandert het spel in AI-boekvertaalevaluatie door semantische nauwkeurigheid en natuurlijke leesbaarheid te prioriteren. In tegenstelling tot traditionele maatstaven houdt METEOR rekening met synoniemen, woordstammen en parafrasen, bereikt het een indrukwekkende correlatie van 0,964 met menselijk oordeel op corpusniveau - aanzienlijk hoger dan BLEU's 0,817 [1]. Dit zorgt ervoor dat vertalingen de stijl, narratieve consistentie en subtiele culturele elementen van de auteur behouden.
Wat METEOR onderscheidt, is zijn recall-gewogen scoring gecombineerd met een fragmentatiepenalty, die zorgt ervoor dat vertalingen niet alleen de volledige betekenis van de originele tekst vastleggen, maar ook soepel lezen. Dit is vooral cruciaal voor langvormige inhoud, waar het behoud van samenhang en vloeibaarheid over een uitgebreid verhaal essentieel is.
Voor platforms zoals BookTranslator.ai, die meer dan 99 talen ondersteunen, stelt METEOR's vermogen om linguïstische variaties te herkennen vertalingen van hoge kwaliteit tegen concurrerende tarieven mogelijk - vanaf slechts $5,99 per 100.000 woorden. Door parallelle gegevens te gebruiken om nieuwe doeltalen te leren [2], opent METEOR de deur voor lezers in ondergerepresenteerde regio's om literatuur in hun moedertaal te openen.
"METEOR werkt meer als moderne spraakherkenningssystemen die verschillende manieren van het zeggen van hetzelfde ding begrijpen. Het evalueert vertalingen met flexibiliteit, wat menselijk oordeel weerspiegelt." - Iterate.ai [3]
Veelgestelde vragen
Is METEOR voldoende om de kwaliteit van een boekvertaling te beoordelen?
METEOR is een handig hulpmiddel voor het meten van vertaalkwaliteit, vooral als het gaat om het identificeren van semantische nuances en linguïstische details. Het is echter niet voldoende om zich alleen hierop te verlaten voor een volledige evaluatie van de kwaliteit van een boekvertaling. Het combineren van METEOR met menselijke evaluaties biedt een meer evenwichtige en grondige manier om de kwaliteit van vertalingen te beoordelen.
Hoe gaat METEOR om met idiomatische uitdrukkingen en creatieve formulering?
METEOR pakt de uitdagingen van idiomatische uitdrukkingen en creatieve formulering aan via synoniemenmatching, stamming en aanpasbare linguïstische evaluatie. Deze tools stellen het in staat subtiele, niet-letterlijke uitdrukkingen te begrijpen, zodat vertalingen zowel de beoogde betekenis als de originele stijl behouden.
Kan METEOR consistentieproblemen in een hele roman opsporen?
METEOR