
Nauwkeurigheidsmetrieken voor vertalingen: Uitgelegd
Nauwkeurigheidsmetrieken voor vertalingen helpen bij het evalueren hoe goed machinevertaling overeenkomt met door mensen gemaakte referenties. Deze tools zijn cruciaal voor het beoordelen van vertaalkwaliteit, vooral bij grote projecten of gevoelige inhoud. Metrieken vallen in drie categorieën:
- Op strings gebaseerde metrieken: BLEU, METEOR, en TER richten zich op woord- of tekenovereenkomsten.
- Neurale metrieken: COMET en BERTScore analyseren semantische gelijkenis met behulp van AI-modellen.
- Menselijke evaluaties: Directe beoordelingen zoals MQM richten zich op toereikendheid en vloeiendheid.
Belangrijkste punten:
- BLEU: Snel en eenvoudig, maar heeft moeite met synoniemen en diepere betekenis.
- METEOR: Houdt rekening met synoniemen en linguïstische nuances; beter voor literaire werken.
- TER: Meet bewerkingsinspanning, maar negeert semantische kwaliteit.
- COMET & BERTScore: Geavanceerde AI-modellen die goed aansluiten bij menselijke oordelen, geweldig voor genuanceerde teksten.
Voor boekvertalingen zorgt een combinatie van geautomatiseerde tools en menselijke evaluaties voor nauwkeurigheid en behoud van de originele stijl. Platforms zoals BookTranslator.ai gebruiken deze hybride aanpak om betrouwbare resultaten in meer dan 99 talen te leveren.
Veelgebruikte nauwkeurigheidsmetrieken voor vertalingen
BLEU Score
BLEU (Bilingual Evaluation Understudy), geïntroduceerd in 2002, blijft een populaire metriek voor het beoordelen van machinevertaling [4]. Het werkt door n-gram precisie te vergelijken, wat betekent dat wordt geanalyseerd hoe woordreeksen in de output van de machine aansluiten op referentievertalingen. BLEU-scores variëren van 0 tot 1, waarbij hogere getallen betere kwaliteit aangeven. Het grootste voordeel? Snelheid en eenvoud - BLEU kan duizenden vertalingen snel verwerken, wat het zeer praktisch maakt. Deze efficiëntie leverde het zelfs de NAACL 2018 Test-of-Time award op.
Zoals Papineni et al. uitlegden: "Het hoofdidee is om een gewogen gemiddelde te gebruiken van n-gram matches van variabele lengte tussen de vertaling van het systeem en een reeks menselijke referentievertalingen" [4].
BLEU heeft echter een opvallende beperking: het geeft prioriteit aan exacte woordovereenkomsten. Dit betekent dat het vertalingen die dezelfde betekenis overbrengen maar ander formuleren, kan onderschatten. Om dit aan te pakken, streven metrieken zoals METEOR ernaar linguïstische nuances vast te leggen.
METEOR Metriek
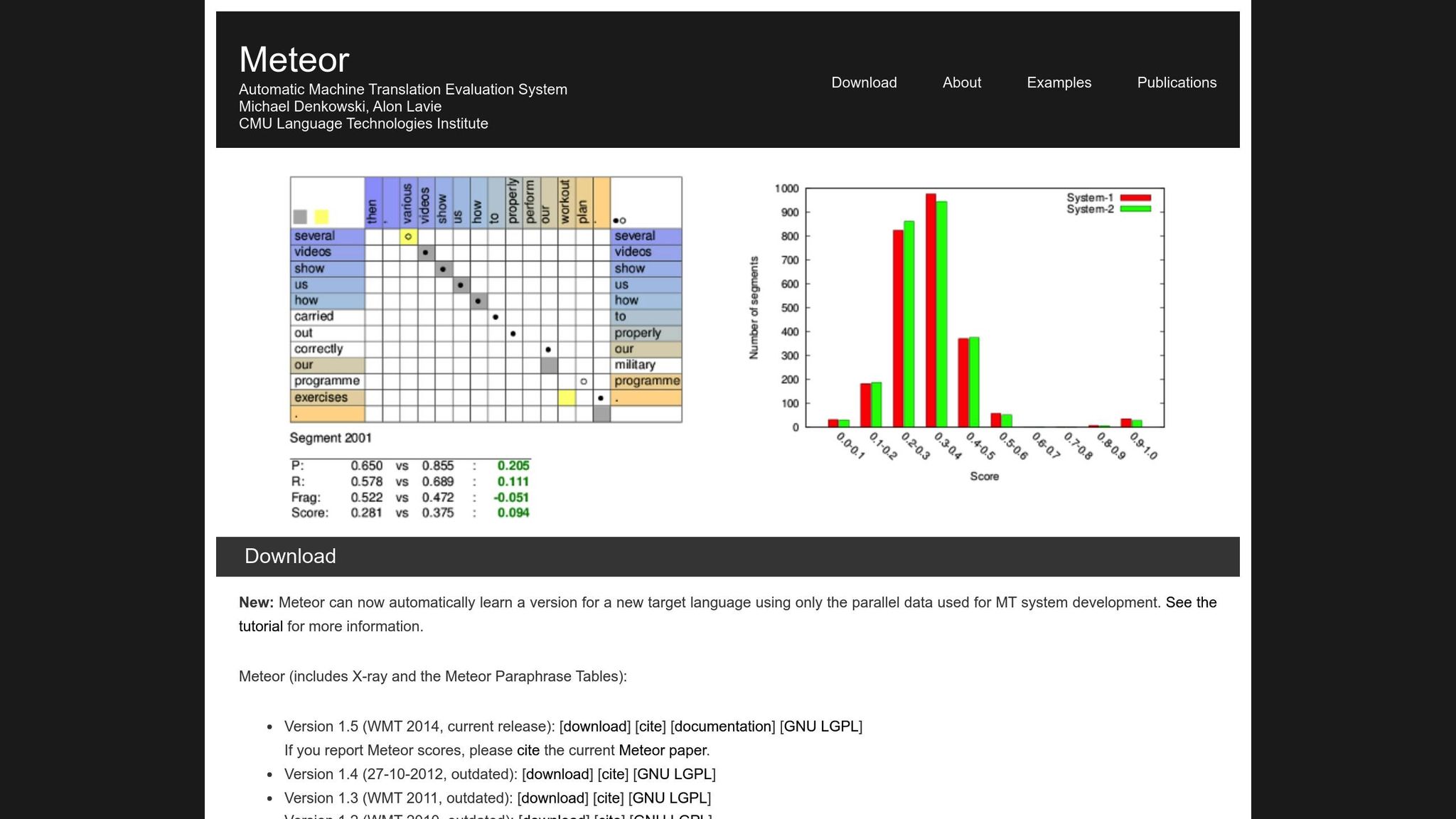
METEOR (Metric for Evaluation of Translation with Explicit ORdering) verbetert BLEU door precisie, herinnering, synoniemen, stammen en woordvolgorde-straffen in te calculeren [1]. Het verwerkt variaties zoals "running" vs. "ran" of "happy" vs. "joyful", waardoor het beter geschikt is voor vertalingen waarbij betekenis het meest telt. Bijvoorbeeld, tijdens de NIST MetricsMaTr10-challenge bereikt METEOR‑next‑rank een Spearman's rho correlatie van 0,92 met menselijke oordelen op systeemniveau en 0,84 op documentniveau [1].
Dat gezegd, METEOR brengt ook zijn eigen uitdagingen met zich mee. Het vereist aanvullende bronnen, zoals synoniemendatabases en stemmingalgoritmen, wat de computationele belasting verhoogt. Toch biedt het vaak een meer genuanceerde en betrouwbare evaluatie, vooral voor het vastleggen van semantische nauwkeurigheid.
Translation Edit Rate (TER)
TER beoordeelt vertaalkwaliteit door het aantal bewerkingen te berekenen - invoegingen, verwijderingen, vervangingen en verschuivingen - nodig om machineoutput om te zetten in de referentie. Dit maakt het vooral nuttig voor het inschatten van de bewerkingsinspanning die nodig is om de output af te stemmen op het gewenste resultaat. In de MetricsMaTr10-evaluaties toonde TER-v0.7.25 een systeemniveaucorrelatie van 0,89 met menselijke beoordelingen van semantische toereikendheid, terwijl TERp een segmentniveaucorrelatie van 0,68 aantoonde [1].
Neurale metrieken: BERTScore, COMET, en GEMBA
Neurale metrieken brengen vertaalevaluatie naar het volgende niveau door zich te concentreren op semantische analyse in plaats van exacte woordovereenkomsten. Hier is een snel overzicht:
- BERTScore: Gebruikt contextuele embeddings om gelijkenis tussen vertalingen te meten.
- COMET: Integreert brontekst, hypothese en referentievertalingen in een neuraal framework getraind op menselijke aantekeningen. Het heeft enkele van de hoogste correlaties met menselijke kwaliteitsoordelen bereikt [5].
- GEMBA: Maakt gebruik van grote taalmodellen voor zero-shot kwaliteitsbepaling, wat een nauwere benadering van menselijke evaluatie biedt.
Hoewel deze metrieken krachtig zijn, brengen zij afwegingen met zich mee. In tegenstelling tot BLEU en TER, die op standaard CPU's in milliseconden kunnen draaien, vereisen neurale metrieken zoals BERTScore en COMET vaak GPU-versnelling om grote datasets efficiënt te verwerken. GEMBA in het bijzonder kan hoge API-kosten met zich meebrengen en mogelijke vooroordelen van grote taalmodellen, wat het voor sommige gebruikers minder toegankelijk maakt.
Automatische metrieken voor het evalueren van MT-systemen
Vertalingsmetrieken vergelijken

Vergelijking nauwkeurigheidsmetrieken voor vertalingen: BLEU, METEOR, TER, BERTScore, COMET en GEMBA
Metriekenvergelijking tabel
Het kiezen van de juiste vertaalmetriek hangt vaak af van de focus van uw evaluatie en de beschikbare middelen. Traditionele metrieken zoals BLEU zijn snel en vereisen minimale middelen, maar hebben moeite om diepere semantische betekenis vast te leggen. Aan de andere kant blinken neurale metrieken uit in het begrijpen van context en betekenis, maar vereisen meer computerkracht.
Recent onderzoek suggereert weg te gaan van op overlap gebaseerde metrieken. Bijvoorbeeld, WMT22-bevindingen bevelen aan metrieken zoals BLEU te verlaten ten gunste van neurale benaderingen [6]. De studie benadrukt dat overlapmetrieken zoals BLEU, spBLEU en chrF slecht correleren met evaluaties van menselijke experts.
Hier is een snelle vergelijking van belangrijke vertalingsmetrieken, met aandacht voor hun focusgebieden, scoringsmethoden, correlatie met menselijke evaluatie, beperkingen en geschiktheid voor boekvertalingen:
| Metriek | Focusgebied | Scoringsbereik | Correlatie met menselijke evaluatie | Beperkingen | Geschiktheid voor boekvertalingen |
|---|---|---|---|---|---|
| BLEU | N-gram precisie | 0 tot 1 (of 0-100) | Laag tot gemiddeld | Heeft moeite met synoniemen [7][8] | Laag; kan literaire stijl niet vastleggen |
| METEOR | Precisie, herinnering, synoniemen, woordvolgorde | 0 tot 1 | Hoog | Vereist taalspecifieke middelen [7] | Gemiddeld; nuttig voor consistente terminologie |
| TER | Bewerkingsafstand (post-editing inspanning) | 0 tot 1 (lager is beter) | Gemiddeld | Negeert semantische kwaliteit [7] | Laag; richt zich op mechanica, niet op "stem" |
| BERTScore | Semantische gelijkenis via contextuele embeddings | 0 tot 1 | Hoog | Zeer hulpbronintensief [7] | Hoog; legt diepere betekenis en context vast |
| COMET | Semantische gelijkenis en vloeiendheid | 0 tot 1 (0,5-0,8 typisch) | Zeer hoog | Vereist voorgetrainde modellen [7][8] | Hoog; bewaart stijl en genuanceerde betekenis |
| GEMBA | Holistische LLM-gebaseerde evaluatie | Varieert | Hoog | Complexe setup; dure API's [7] | Hoog; biedt een "mensachtig" uitgebreid overzicht |
Deze tabel onderstreept hoe verschillende metrieken aansluiten bij specifieke vertaalbehoeften. Voor technische vertalingen bieden metrieken zoals BLEU en TER snelle, basale benchmarks. Voor literaire vertalingen echter - waar stijl, toon en genuanceerde betekenis cruciaal zijn - presteren neurale metrieken zoals BERTScore en COMET veel beter. Deze tools zijn bijzonder geschikt om de diepte en artisticiteit van literaire teksten vast te leggen, wat traditionele metrieken vaak over het hoofd zien [7].
Bijvoorbeeld, platforms zoals BookTranslator.ai, die streven naar een evenwicht tussen efficiëntie en kwaliteit, profiteren aanzienlijk van neurale metrieken. Tools zoals BERTScore en COMET zorgen ervoor dat zowel semantische nauwkeurigheid als literaire stijl behouden blijven.
Om dingen in perspectief te plaatsen, een "goede" BLEU-score ligt meestal tussen de 30 en 40, met scores boven de 40 als sterk beschouwd, en alles boven de 50 duidt op vertaling van hoge kwaliteit [8]. Voor COMET variëren scores over het algemeen van 0,5 tot 0,8, waarbij waarden dichter bij 1,0 vertaling van bijna menselijk niveau weerspiegelen [8]. Neurale metrieken presteren niet alleen consistent over verschillende teksttypen, maar passen zich ook beter aan aan variërende contexten in vergelijking met domeinspecifieke metrieken zoals BLEU [6].
sbb-itb-0c0385d
Menselijke evaluatiemethoden
Geautomatiseerde metrieken bieden misschien snelheid en consistentie, maar ze missen vaak de subtiele details die vertaalkwaliteit bepalen. Daar komt menselijke evaluatie om de hoek als de gouden standaard[2]. Hoewel het langzamer en duurder is, ontdekt menselijke evaluatie de diepere redenen achter kwaliteitsproblemen - dingen die metrieken zoals BLEU of COMET gewoon niet kunnen identificeren[9].
Er zijn twee hoofdbenaderingen voor menselijke evaluatie. Een is Directly Expressed Judgment (DEJ), waarbij vertalingen worden beoordeeld op schalen zoals vloeiendheid en toereikendheid. De ander betreft non-DEJ methoden, die zich richten op het opsporen en categoriseren van specifieke fouten, vaak met behulp van frameworks zoals MQM[12]. Hoewel analytische methoden individuele fouten en hun ernst uiteen zetten, kijken holistische methoden naar de algehele kwaliteit. Samen vormen deze benaderingen de ruggengraat van frameworks zoals MQM.
MQM (Multidimensionale kwaliteitsmetrieken)

Wanneer geautomatiseerde tools tekortschieten, biedt MQM een meer gedetailleerd en actionabel alternatief. Het splitst vertaalfouten op in categorieën zoals Nauwkeurigheid, Vloeiendheid, Terminologie, Landinstellingsconventies en Ontwerp/Opmaak, in plaats van kwaliteit samen te vatten met één getal[18, 17].
"Daarentegen geven geautomatiseerde metrieken meestal slechts een getal zonder aanwijzing hoe je resultaten kunt verbeteren."
– MQM Commissie[10]
Fouten worden ingedeeld naar ernst: Neutraal (gemarkeerd maar aanvaardbaar, geen straf), Minor (licht opvallend, strafgewicht 1), Major (beïnvloedt begrip, strafgewicht 5), en Kritiek (maakt de tekst onbruikbaar, strafgewicht 25)[11]. Voor kritieke vertalingen, zoals juridische documenten, kunnen doorlaatdrempels zo hoog worden ingesteld als 99,5 op een onbewerkte scoreschaal[11].
Wat MQM bijzonder nuttig maakt, is het vermogen om specifieke probleemgebieden aan te wijzen. Bijvoorbeeld, als een literaire vertaling slecht scoort, kan MQM onthullen of het probleem ligt in onhandige formulering of inconsistente terminologie. Dit detailniveau is bijzonder waardevol voor platforms zoals BookTranslator.ai, waar het vastleggen van zowel de betekenis als de literaire stijl essentieel is.
Toereikendheid en vloeiendheid scoren
Voortbouwend op gestructureerde frameworks zoals MQM, richten evaluators zich ook op twee belangrijke dimensies van vertaalkwaliteit: toereikendheid en vloeiendheid. Toereikendheid meet hoe goed de vertaling de betekenis van de brontekst overbrengt, terwijl vloeiendheid evalueert hoe natuurlijk en leesbaar het is voor moedertaalsprekers. Deze aspecten worden vaak op vijfpuntsschalen beoordeeld[9].
Het balanceren van deze twee dimensies kan lastig zijn, vooral in literaire vertalingen. Het behouden van de stem van de originele auteur terwijl de tekst vloeiend leest in de doeltaal vereist zorgvuldige aandacht.
Om dit proces te verfijnen, gebruiken evaluators Direct Assessment (DA), wat vertalingen in monolinguale, bilinguale of referentie-gebaseerde formaten scoort[9]. De Scalar Quality Metric (SQM) gaat hier nog een stap verder met een zevenpuntsschaal, waarmee beoordelaars individuele segmenten in de context van het hele document kunnen evalueren. Voor boeken is deze contextfocus cruciaal - kwaliteit hangt vaak af van hoe goed een hoofdstuk personages ontwikkelt of plotcontinuïteit handhaaft.
Metrieken gebruiken voor boekvertaling
Boeken vertalen is een unieke uitdaging. In tegenstelling tot instructiehandleidingen of marketingmaterialen vereisen boeken een balans tussen semantische nauwkeurigheid - ervoor zorgen dat de betekenis correct is - en stilistische instandhouding - het behouden van de stem en toon van de auteur. Het evalueren van boekvertalingen vereist een op maat gesneden aanpak, met metrieken gekozen voor het specifieke type inhoud dat wordt vertaald.
Technische versus literaire vertalingen
Niet alle boekvertalingen hebben dezelfde vereisten. Technische teksten, zoals academische of instructiematerialen, geven prioriteit aan precisie en consistentie. Hiervoor zijn metrieken zoals TER (Translation Edit Rate) bijzonder effectief, omdat ze de hoeveelheid bewerking meten die nodig is om de vertaling perfect te maken.
Literaire werken zijn echter een ander verhaal. Romans, memoires en soortgelijke genres zijn sterk afhankelijk van narratieve flow en emotionele resonantie. In deze gevallen blinkt METEOR uit omdat het synoniemen en subtiele semantische verschillen in aanmerking neemt, met correlaties met menselijke evaluaties zo hoog als 0,92 op systeemniveau [1]. Hoewel BLEU een snelle baseline kan bieden, mist het vaak de diepere nuances die een vertaling van hoge kwaliteit op literair vlak bepalen.
Automatische en menselijke evaluatie combineren
Gezien de uiteenlopende eisen van boekvertaling werkt een hybride evaluatiebenadering het best. Neurale metrieken zoals COMET en BERTScore bieden een snelle manier om vertaalkwaliteit in te schatten en sluiten goed aan bij menselijk oordeel