
Heb je er wel eens over nagedacht om een fysiek boek uit je kast te pakken en het om te zetten in een perfect vertaalde digitale kopie? Dat is de magie van het OCR en vertalen proces. Het begint met Optical Character Recognition (OCR) om de tekst uit gescande pagina's te halen, en gebruikt vervolgens machinevertaling om het in een nieuwe taal om te zetten. Deze gids gaat veel verder dan eenvoudige apps en legt een professionele workflow uit voor het behandelen van boeken en ander langformaat content met de nauwkeurigheid die ze verdienen.
Je moderne workflow voor digitale boekvertaling
Een gedrukt boek omzetten in een gepolijst, vertaald digitaal bestand is een echt project. Het is geen kwestie van één klik, maar een methodisch proces dat is ontworpen om de originele stem van de auteur intact te houden terwijl het wordt geopend voor een heel nieuw publiek. Je bouwt eigenlijk een brug van de gedrukte pagina naar het digitale scherm, en transformeert statische inkt in dynamische, bewerkbare en doorzoekbare gegevens.
Succes komt echt neer op een reeks zorgvuldige stappen, waarbij elke stap het toneel voorbereidt voor de volgende. Denk eraan als een productielijn voor je boek.
De kernfasen van boekvertaling
De reis van een stapel papier naar een afgewerkt EPUB of PDF bestaat uit enkele verschillende fasen. Dit diagram geeft je een vogelvluchtperspectief van het hele proces, van het scannen van het bronmateriaal tot het opmaken van het uiteindelijke bestand.
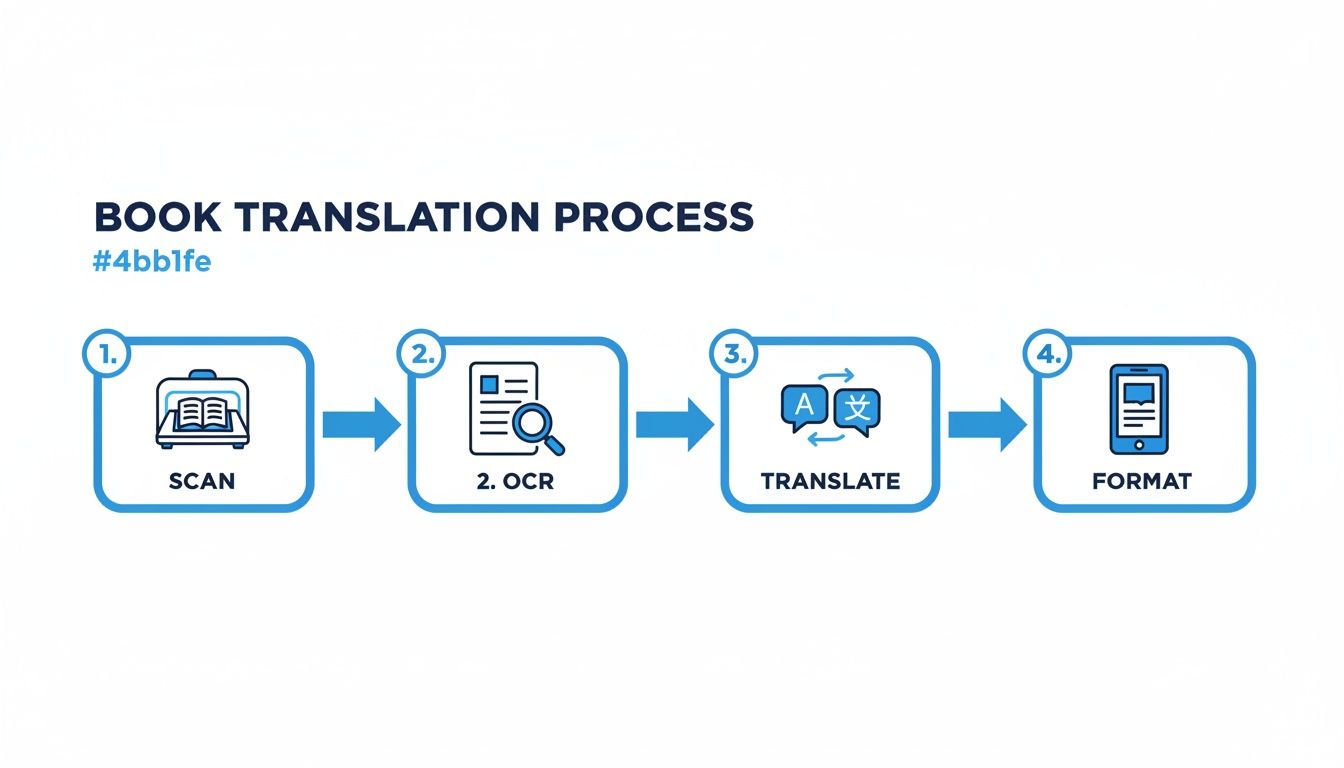
Elk van deze stadia—Scannen, OCR, Vertalen en Opmaken—is een kritieke schakel. De kwaliteit die je uit de ene krijgt, bepaalt rechtstreeks de kwaliteit die je in de volgende kunt stoppen.
Dit is niet langer alleen een nischevaardigheid; de vraag explodeert. De mondiale Optical Character Recognition markt bereikte USD 13,95 miljard in 2024 en zal naar verwachting voorbij USD 46 miljard in 2033 schieten, allemaal dankzij de massale push voor digitalisering wereldwijd.
Belangrijkste conclusie: Voor elk groot project is een gestructureerde workflow onontbeerlijk. Als je de scan overhaast of bezuinigt op het opschonen van de geëxtraheerde tekst, creëer je alleen massale problemen voor jezelf later, vooral tijdens vertaling en opmaak.
Als onderdeel van elke moderne, professionele workflow is het ook cruciaal om GDPR-conforme AI-integratie te garanderen, vooral wanneer je de inhoud van hele boeken behandelt. Deze gids geeft je het complete projectplan om met vertrouwen grote OCR- en vertaalprojecten van begin tot eind te beheren.
Je boek voorbereiding voor een foutloze scan
Je hele OCR- en vertaalproject hangt af van één ding: de kwaliteit van je initiële scans. Lange voordat je zelfs maar aan het uitvoeren van de tekstherkenningssoftware denkt, moet je deze eerste stap goed doen. Een vage, scheve of slecht verlichte scan creëert een cascade van fouten, waardoor je onleesbare tekst en een vertaalnachtmerrie krijgt.
Denk eraan als koken. De beste chef ter wereld kan geen geweldig gerecht maken met bedorven ingrediënten. Je scans zijn je ingrediënten.

Dit is waar je scanner je belangrijkste gereedschap wordt. Vergeet het idee om een telefoon-app voor een heel boek te gebruiken; je zult nooit de consistentie krijgen die je nodig hebt. Voor een project van deze schaal geeft alleen een flatbedscanner je de controle en kwaliteit die vereist zijn.
Je scannerinstellingen afstemmen
Je scannerinstellingen goed instellen is niet alleen een suggestie—het is absoluut kritiek voor het krijgen van schone, nauwkeurige tekst. Een paar aanpassingen hier kunnen je ontelbare uren pijnlijke handmatige correcties later besparen.
Ik heb honderden boeken gescand, van moderne paperbacks tot eeuwenoude tomen, en de juiste instellingen maken het verschil. Om je op weg te helpen, hier is een snelle gids over wat je moet gebruiken en waarom.
Optimale scannerinstellingen voor boek-OCR
| Instelling | Aanbeveling voor moderne boeken | Aanbeveling voor oudere/complexe boeken | Redenering |
|---|---|---|---|
| Resolutie (DPI) | 300-400 DPI | 400-600 DPI | 300 is het minimum voor duidelijkheid. Ga hoger voor kleine lettertypen, vervaagde inkt of complexe lay-outs om meer detail vast te leggen zonder de bestandsgrootte te vergroten. |
| Kleurmodus | Grijswaarden | Grijswaarden | Grijswaarden leggen tekstnuances beter vast dan harde zwart-witstand en vermijdt de enorme bestandsgroottes en kleurruisen van volkleurenscans. |
| Bestandsindeling | TIFF | TIFF | TIFF is een verliesloze indeling. Het bewaart elke pixel perfect, waardoor compressiefouten die JPEG's creëren en die OCR-nauwkeurigheid kunnen verwoesten, worden voorkomen. |
Deze instellingen zijn je beste gok voor het vastleggen van scherpe tekst. Onthoud dat het doel is om de OCR-software vanaf het begin de schoonste mogelijke gegevens te geven.
Mijn persoonlijke regel: Gebruik nooit, maar dan ook nooit JPEG voor archiefscan. De "verliesrijke" compressie gooit letterlijk gegevens weg om bestanden kleiner te maken, wat fuzzy artefacten rond de letters creëert. Het is een shortcut die je altijd meer tijd kost in correcties.
Pre-processing: de opschoningsfase
Met je pagina's gedigitaliseerd, ben je nog niet helemaal klaar voor de OCR-engine. Een beetje pre-processing zal de onbewerkte scans opschonen en je resultaten dramatisch verbeteren. De meeste fatsoenlijke scansoftware bevat deze hulpmiddelen, maar een gratis afbeeldingseditor werkt net zo goed.
Dit is wat ik altijd controleer en fix:
- Deskew: Dit is de belangrijkste stap. Het maakt automatisch recht elke pagina die onder een lichte hoek is gescand. Zelfs een kleine 1-graden tilt kan de software verwarren, dus voer dit op elke pagina uit.
- Bijsnijden: Verwijder de zwarte randen en elk deel van het scannerlid dat in de afbeelding terecht is gekomen. Je wilt dat de software zich alleen op de pagina-inhoud concentreert, niet op de rommel eromheen.
- Contrast/Helderheid: Pas deze niveaus aan om de tekst zo donker en de achtergrond zo helder mogelijk te krijgen. Zorg ervoor dat je de letters niet uitwast. Dit is een reddingslijn voor oude boeken met vergeelde pagina's of vervaagde inkt.
Dit zorgvuldige voorbereidingswerk is wat een frustrerend project van een succesvol project onderscheidt.
Zodra je die zuivere tekst hebt geëxtraheerd, kun je nadenken over het uiteindelijke formaat. Als je twijfelt over hoe je je vertaalde boek verpakt, hebben we een handige gids die de voor- en nadelen van EPUB versus PDF voor AI-vertaling uitlegt.
Het juiste OCR-hulpmiddel kiezen voor schone tekstextractie
Met je zuivere scans klaar, is het tijd om naar het hart van de digitale conversie te gaan: het selecteren van de juiste Optical Character Recognition (OCR) engine. Het hulpmiddel dat je nu kiest, beïnvloedt rechtstreeks de kwaliteit van je onbewerkte tekst, die op zijn beurt het fundament voor het hele vertaalproces vormt. Wanneer je een heel boek aanpakt, niet alleen een paar pagina's, zal niet elke OCR-software volstaan.
Je kijkt over het algemeen naar twee paden hier: krachtige desktoptoepassingen of zeer schaalbare cloudgebaseerde services. Elk heeft zijn plaats, en de beste keuze hangt echt af van de specifieke details van je project.

Deze interface van ABBYY FineReader toont een onmisbare functie voor serieus OCR-werk—de mogelijkheid om de originele scan en de herkende tekst naast elkaar te zien. Het maakt het opsporen en repareren van fouten een fluitje van een cent.
Desktopsoftware versus cloudservices
Voor degenen die volledige, granulaire controle over het proces willen, is een desktoptoepassing zoals ABBYY FineReader een langdurig favoriete industrie. Het is briljant in het omgaan met complexe pagina-indeling, herkent een enorme lijst van talen, en geeft je hulpmiddelen om handmatig vakken rond de exacte tekst te tekenen die je wilt vastleggen. Dit is een reddingslijn voor het vertellen van de software om vervelende headers, voetteksten en paginanummers te negeren.
Aan de andere kant heb je cloudpowerhouses zoals Google Cloud Vision OCR en Amazon Textract. Deze services zijn gebouwd voor schaal. In plaats van je eigen computer uren vast te zetten, kun je ze honderden of zelfs duizenden pagina's tegelijk voeren en alleen betalen voor wat je verwerkt. Hun AI-modellen worden voortdurend verfijnd, dus de nauwkeurigheid die je direct uit de doos krijgt, is vaak indrukwekkend.
Mijn twee cent: Als ik aan één boek met een echt eigenzinnig ontwerp werk, blijf ik voor die fijne controle bij een desktophulpmiddel. Maar als het doel is om een hele boekenplank met standaardindeling te digitaliseren, is de pure snelheid en batch-verwerkingskracht van een cloudservice de enige manier.
Je OCR-instellingen afstemmen voor maximale nauwkeurigheid
Ongeacht welk hulpmiddel je kiest, druk niet zomaar op de "Go"-knop. Even de tijd nemen om de instellingen van tevoren in te stellen, bespaart je een wereld van handmatige opschoning later.
Dit zijn de onontbeerlijke zaken:
- Stel de herkenningingstaal in: Dit lijkt voor de hand liggend, maar het is de meest cruciale stap. Expliciet aan de software vertellen wat de brontaal is (bijv. Duits, Japans, Spaans) laadt de juiste tekensets en woordenboeken, waardoor het foutenpercentage drastisch daalt.
- Definieer herkenningszones: Besteed een minuut aan een paar voorbeeldpagina's om vakken rond de hoofdtekst te tekenen. Dit is hoe je de OCR traint om paginanummers, lopende headers en decoratieve randen te negeren die je uiteindelijke tekstbestand alleen zullen vervuilen.
- Schakel woordenboeken in: Als de software deze functie heeft, schakel deze in. Het stelt het hulpmiddel in staat om herkende woorden tegen een bekend vocabulaire te controleren, wat het helpt om veel voorkomende fouten zelf te corrigeren, zoals het verwarren van "rn" met "m".
Deze initiële setup is je eerste verdedigingslinie tegen een rommelig, foutgevuld tekstbestand.
Veel van de beste OCR- en vertaaloplossingen worden nu aangestuurd door geavanceerde AI; het is de moeite waard om verschillende AI-hulpmiddelen voor contentmakers te onderzoeken om te zien wat anders je workflow kan aanvullen. Deze push voor slimmere technologie is een enorme factor in de groeiende markt voor vertaalservices, die in 2024 werd gewaardeerd op $26,7 miljard en op koers ligt om $34,24 miljard in 2029 te bereiken. De snelle groei laat zien hoeveel vraag er is naar hoogwaardige, efficiënte lokalisatie over de hele wereld.
Inhoud vertalen zonder de stem van de auteur kwijt te raken
Schone tekst uit je OCR-proces krijgen is een enorme stap, maar nu komt de echte uitdaging: vertaling. Als je de tekst eenvoudig in een standaard vertaalhulpmiddel dumpt, krijg je woorden terug, maar de ziel van de auteur zal weg zijn. Het resultaat is vaak technisch correct maar emotioneel plat, ontdaan van de zeer persoonlijkheid die het boek in de eerste plaats aantrekkelijk maakte.
Het doel is niet alleen om woorden van de ene taal naar de andere om te zetten. Het gaat erom betekenis, stijl en toon getrouw over te dragen. De beste manier om dit voor elkaar te krijgen is met een hybride benadering—een die de ruwe kracht van AI combineert met de onvervangbare nuance van een menselijk expert.
AI-snelheid combineren met menselijk inzicht
Moderne vertaalplatforms zoals DeepL hebben het spel volledig veranderd. Ze zijn ongelooflijk goed in het begrijpen van context en zinsstructuur, en produceren vertalingen die veel natuurlijker voelen dan de klunzige, letterlijke outputs van oudere systemen. Dit geeft je een fantastische eerste concept, waarbij je in minuten doet wat een menselijke vertaler weken zou kosten.
Maar ondanks al zijn verfijning struikelt AI nog steeds over de subtiliteiten. Het begrijpt idiomatische uitdrukkingen, culturele binnengrappen of de unieke stilistische eigenaardigheden die een auteur definiëren niet helemaal. Een speelse woordspeling in het Spaans kan bijvoorbeeld gemakkelijk stijf en overdreven formeel in het Engels worden als het letterlijk wordt vertaald.
Dit is precies waarom een uiteindelijke menselijke beoordeling absoluut essentieel is voor een resultaat van hoge kwaliteit. De ideale workflow is een partnerschap:
- Krijg het AI-eerste concept: Begin door je schone, OCR-geëxtraheerde tekst door een eersteklas machine-vertaalengine te voeren.
- Breng de menselijke expert: Een vloeiende spreker leest vervolgens zorgvuldig de vertaalde tekst door, vergelijkt deze met het origineel om te zien wat de machine heeft gemist.
- Verfijn en polijst: De reviewer maakt onhandige formuleringen glad, corrigeert culturele misvertalingen en stemt de toon fijn af totdat deze perfect overeenkomt met de bedoeling van de auteur.
Deze één-twee-slag geeft je de ongelooflijke efficiëntie van AI zonder het hart van het originele werk op te offeren. We duiken eigenlijk veel dieper in dit onderwerp in ons artikel over AI versus menselijke vertalers en het behoud van literaire stijl.
Woordenlijsten en stijlgidsen gebruiken voor consistentie
Wanneer je aan een project zo groot als een boek werkt, is consistentie alles. Niets trekt een lezer sneller uit het verhaal dan het zien van de naam van een hoofdpersoon of een fictieve stad anders gespeld van het ene hoofdstuk naar het andere. Het voelt gewoon slordig.
Gelukkig geven moderne CAT (Computer-Assisted Translation) hulpmiddelen je een manier om consistentie af te dwingen. Ze laten je projectspecifieke bronnen bouwen die de hele vertaling begeleiden, of het nu AI of een mens is die het werk doet.
- Vertaalwoordenlijsten: Denk hieraan als een aangepast woordenboek voor je boek. Je kunt precies definiëren hoe sleutelwoorden, karakternamen en specifieke zinnen elke keer dat ze voorkomen, moeten worden vertaald.
- Stijlgidsen: Dit is waar je de wet stelt over toon en formaliteit. Moet de proza conversationeel of academisch zijn? Zijn er specifieke zinnen die je wilt vermijden? Een stijlgids zorgt ervoor dat het boek als een samenhangend geheel leest, niet als een verzameling losse hoofdstukken.
Door een eenvoudige woordenlijst te bouwen, dwing je consistentie af en verminder je drastisch de tijd die aan handmatige correcties wordt besteed. Het zorgt ervoor dat "El Bosque de las Sombras" altijd wordt vertaald als "The Forest of Shadows" en nooit "The Woods of Shade."
De engine die dit allemaal aandrijft, Machine Translation (MT), is een veld dat ongelooflijk snel groeit. Gewaardeerd op USD 1,12 miljard in 2025, zal de markt naar verwachting bijna verdubbelen tot USD 2 miljard in 2030. Deze boom wordt aangestuurd door Neural Machine Translation (NMT), die een dominante 48,67% marktaandeel heeft dankzij zijn superieure nauwkeurigheid. Zoals je kunt zien in de opkomst van MT-technologie van Global Growth Insights, maakt deze technologie geavanceerde ocr en vertaal workflows krachtiger dan ooit. Het omarmen van deze slimme, hybride benadering is je beste gok om een eindproduct te creëren dat het originele werk echt eert.
Het allemaal weer samenstellen: je uiteindelijke digitale boek maken
Je bent er. Het scannen, de OCR-opschoning en de zorgvuldige vertaling zijn allemaal klaar. Nu heb je een schoon, vertaald manuscript, en het is tijd voor het meest bevredigende deel van het proces: het herbouwen in een gepolijst, professioneel digitaal boek.
Dit is waar al dat zorgvuldige voorbereidingswerk zijn vruchten afwerpt. Je bent eigenlijk een digitale zetter, die de onbewerkte tekst omzet in een elegant EPUB of een scherpe PDF die lezers zullen liefhebben. Deze uiteindelijke montage is wat een eenvoudig tekstbestand omzet in een echt hoogwaardige leeservaring.
Van platte tekst naar een gestructureerde e-book
Eerst dingen eerst, je moet je vertaalde tekst in een e-bookaanmaakgereedschap brengen. Voor het maken van reflowable EPUB's—de standaard voor de meeste e-readers zoals Kindle en Kobo—kun je niet fout gaan met krachtige, gratis opties zoals Calibre of Sigil. Als je project een vaste indeling vereist die een gedrukt boek nabootst, dan is Adobe InDesign het industriestandaardhulpmiddel voor de klus.
Met je tekst geïmporteerd, begint het echte ambacht. Dit is niet zomaar een kopieer-plakwerk; je herbouwt methodisch de architectuur van het boek om ervoor te zorgen dat het leesbaar en navigeerbaar is.
- Hoofdstukonderbrekingen: Je moet schone divisies invoegen om de lezer door het verhaal te leiden.
- Koppen en subkoppen: Het toepassen van juiste H1-, H2- en H3-tags creëert een logische hiërarchie en een functionele inhoudsopgave.
- Tekststijl: Het is tijd om de bedoeling van de originele auteur terug te brengen door cursief, vetgedrukte tekst en alle onderscheidende blokquotes te herstellen.
- Afbeeldingsplaatsing: Zorg voorzichtig dat je de originele illustraties, grafieken of diagrammen terug in de tekststroom integreert.

Hulpmiddelen zoals Calibre geven je een ongelooflijke hoeveelheid controle, waarmee je alles kunt fijnafstemmen van de omslagafbeelding en metagegevens tot de onderliggende CSS die het uiterlijk van het boek bepaalt. Voor een diepere duik, bekijk onze gids over de top hulpmiddelen voor vertaalgvriendelijke opmaak.
De uiteindelijke QA: validatie en polijsten
Voordat je de champagne opentrek, is er nog één cruciale stap: een grondige kwaliteitsborgingscontrole (QA). Een e-book kan op je desktop foutloos lijken, maar valt uit elkaar op een echte e-reader. Deze uiteindelijke controle zorgt ervoor dat elke lezer een consistente, professionele ervaring krijgt, ongeacht hun apparaat.
Een advies uit ervaring: Denk er niet eens aan om dit over te slaan. Een enkele verbroken afbeelding of een gemist hoofdstuk kan een lezer volledig uit het verhaal trekken en al je harde werk ondermijnen.
Dit is wat je uiteindelijke QA-checklist eruit zou moeten zien:
- Een volledig opmaakdoornemen: Ga met een fijne kam door de gehele e-book, kijkend alleen naar opmaakvraagstukken. Zijn alle koppen consistent? Zien de alineasinspringing er goed uit? Zijn afbeeldingen correct uitgelijnd en breken ze niet over pagina's heen?
- Test op meerdere apparaten: Dit is onontbeerlijk. Laad het bestand op zoveel mogelijk apparaten en apps. Een Kindle, een Kobo, Apple Books, Google Play Books—zie hoe het op allemaal eruit ziet. Reflowable EPUB's kunnen verrassend anders tussen platforms weergegeven worden.
- Voer een EPUB-validatie uit: Gebruik een officieel hulpmiddel zoals de EPUBCheck-validator om ervoor te zorgen dat je bestand technisch gezond is en aan industrienormen voldoet. Dit is je beste verdediging tegen compatibiliteitsproblemen die je boek kunnen weigeren in onlinewinkel.
Door je digitale boek zorgvuldig herbouwen en te polijsten, creëer je een eindproduct dat het originele werk echt eert. Je hebt het succesvol ontgrendeld voor een gloednieuw publiek via het ocr en vertaal proces, en nu is het klaar voor hen om ervan te genieten.
Veelgestelde vragen over boek-OCR en vertaling
Zelfs met een solide workflow kan het aanpakken van een volledig boekvertaalproject je enkele kronkels gooien. Laten we enkele van de meest gestelde vragen aanpakken, van het navigeren door juridische grenzen tot het stellen van realistische verwachtingen voor je hulpmiddelen. Dit nu uitzoeken kan je later veel ellende besparen.
Denk eraan als het balanceren van de technische mogelijkheden met de praktische realiteiten van het project. Een beetje voorzorg gaat een lange weg.
Is het legaal om een auteursrechtelijk beschermd boek te scannen en te vertalen?
Dit is de grote vraag, en eerlijk gezegd, het leeft in een juridische grijszone. In veel plaatsen, inclusief de Verenigde Staten, kan het scannen van een boek dat je hebt gekocht voor je eigen persoonlijk gebruik onder "fair use"-principes vallen. De sleutelwoorden daar zijn persoonlijk gebruik.
Op het moment dat je die vertaalde kopie deelt, verspreidt of probeert te verkopen, ben je over een zeer duidelijke lijn in auteursrechtschending gestapt. Dat is illegaal tenzij je rechtstreekse toestemming hebt van wie de auteursrechten bezit.
Mijn twee cent: Behandel dit hele proces als een manier om toegang te krijgen tot inhoud die je al bezit. Het is voor het lezen van boeken die je wettelijk hebt gekocht, maar in je eigen taal. Deel of verkoop nooit de bestanden die je maakt. En wees altijd bewust van de auteursrechtwetten waar je woont.
Hoe ga ik om met complexe lay-outs zoals leerboeken of tijdschriften?
Niet alle boeken zijn eenvoudige, ongecompliceerde tekstblokken. Leerboeken met callout-vakken, tijdschriften met me